
Back in April, 2018 we were attending the world-known UK SEO conference called BrightonSEO. This conference is a great place for networking opportunities but also for its high-level conferences hold by top speakers from the industry. Oncrawl was attending for the second time and gave a conference about Rankbrain and AI in SEO.
This article aims to summarize this talk and to highlight strategic points to maximize your SEO efforts in a Rankbrain environment. You can read the full article or skip to the part you’re more interested in.
Crawl, indexing, rankings and AI principles
Key SEO indicators that favors Google’s crawl
Indexation and content interpretation
How to maximize your efforts regarding Rankbrain?
Crawl, indexing, rankings and AI principles
Before to dig more into the impact of Rankbrain on SEO, it is essential to understand how search engines work.
Actually, the life of a query made by a user begins long before your capture, by exploring and indexing the billions of documents that make up the web. Google’s algorithms are computer programs designed to navigate through billions of pages, find the right clues and send you exactly the answer to your question.
Doing so, Google consumes annually as much energy as the city of San Francisco. This energy is called crawl budget and refers to resources Google setups to crawl your website.
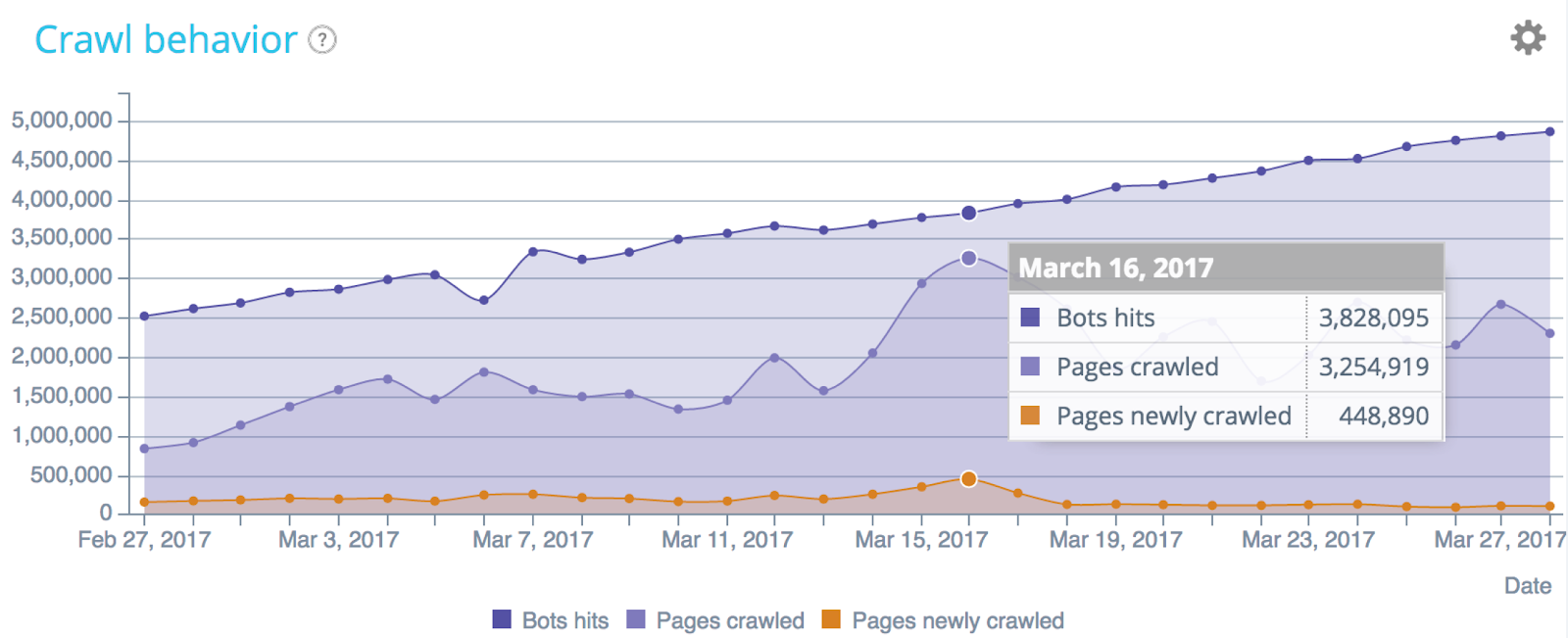
Understanding crawl behavior with log files analysis (Oncrawl data)
Understanding and optimizing crawl budget
It is thus important to understand how Google is seeing your website and how often he is crawling it.
Google says that:
“[…] we do not have a single term to describe everything this term seems to mean
If you observe that new pages are usually explored the same day they are published, then you don’t really have to worry about the exploration budget
[…] if a site has less than a few thousand URLs, it will be browsed correctly most of the time”
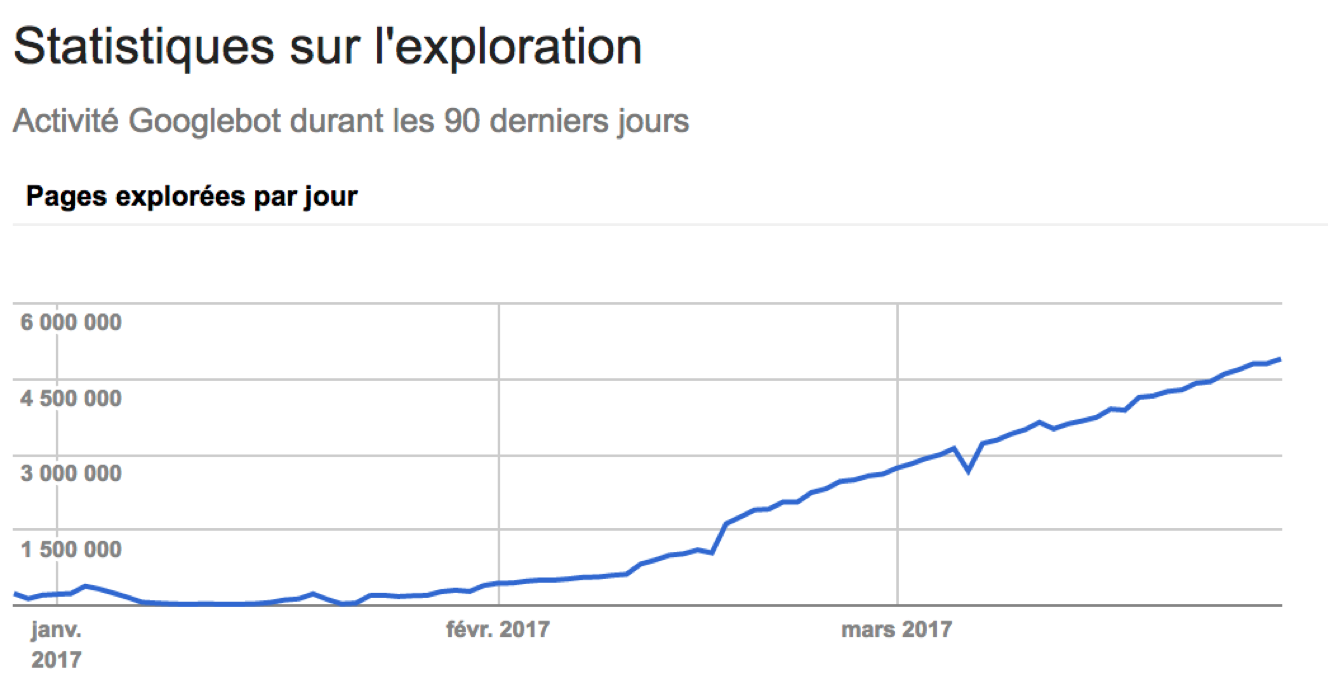
Things are, we all know this is not accurate and that we need more precise data about how crawl budget is being spent on your website. Indeed, 100% of websites have exploration data within their Search Console account.
While you can only access a sample of results using GSC, log files analysis uncovers your whole website’s crawl behavior. There, you can detect anomalies in the bot’s behavior, crawl spikes or any other issue.
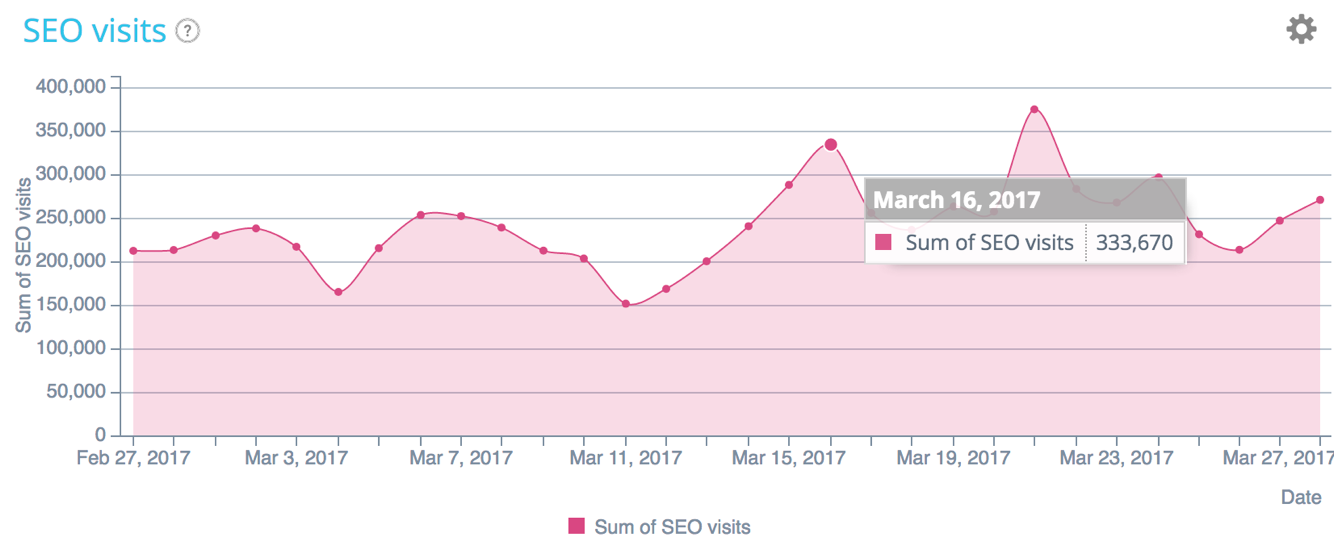
SEO visits repartition – Oncrawl’s data
Is crawl budget related to rankings and visits? The more the index is updated, the more Google will know that the page fit « the best answer to a query ».
Effectively organize crawling
In order to define how your crawl budget is going to be spent you need to:
- Prioritize URLs to explore according to important factors;
- Schedule important pages first;
- Adapt budget according to needs to reduce costs;
- Optimize your website’ data quality to help algorithms make the good choices.
“Google’s spiders regularly crawl the web to rebuild our index. Crawls are based on many factors such as PageRank, links to a page, and crawling constraints such as the number of parameters in a URL. Any number of factors can affect the crawl frequency of individual sites.
Our crawl process is algorithmic; computer programs determine which sites to crawl, how often and how many pages to fetch from each site. We don’t accept payment to crawl a site more frequently.” Google Webmaster Guidelines.
Monitoring crawl frequency
Prior to optimize crawl frequency, you must:
- Analyze your log files to receive a sanity indicator regarding your SEO. They contain the only data that accurately reflects how search engines browse your website;
- Create alert when crawl frequencies drop or increase.
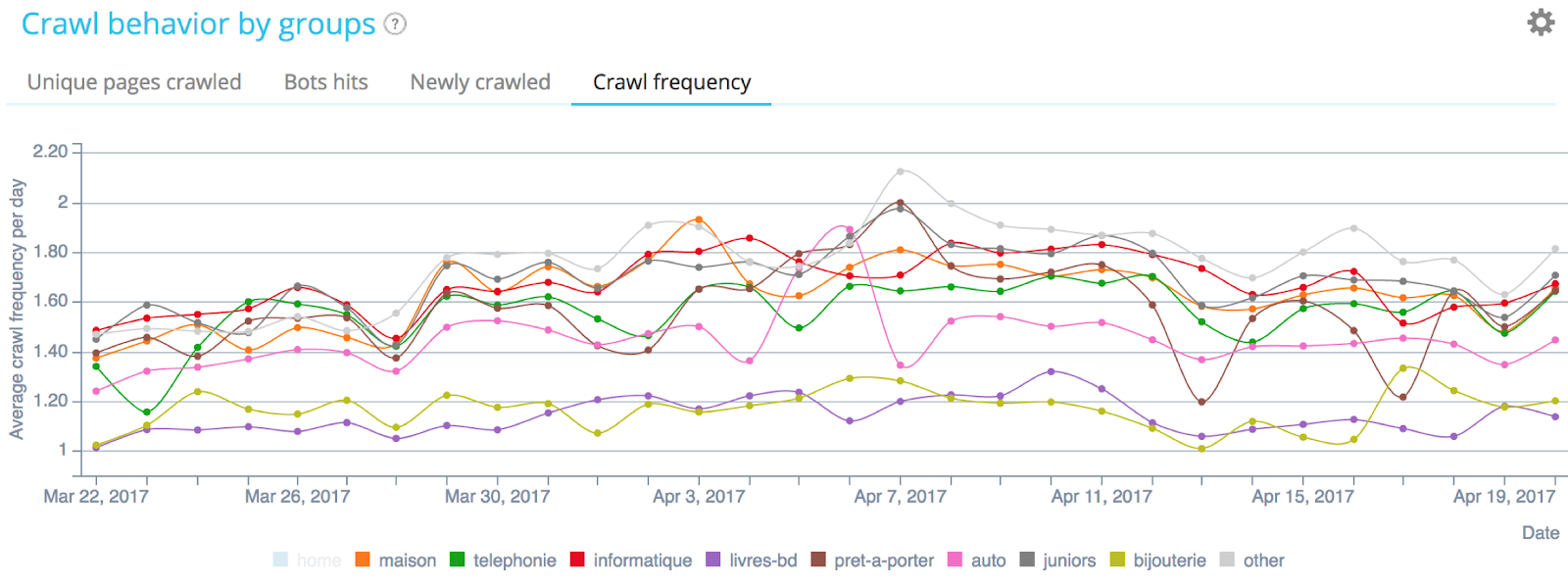
Crawl frequency regarding strategic groups of pages – Oncrawl’s data
Understanding the impact of variables on indexing
Algorithms use variables to define the amount of crawl budget to spend on your website. It is necessary to return the most beautiful data to help algorithms trigger the increase of crawl budget.
Google uses internal metrics (content, entity detection, schema.org, payload, popularity, etc) and external metrics (page rank, Trust & Citation Flow, etc) to index a page or not.
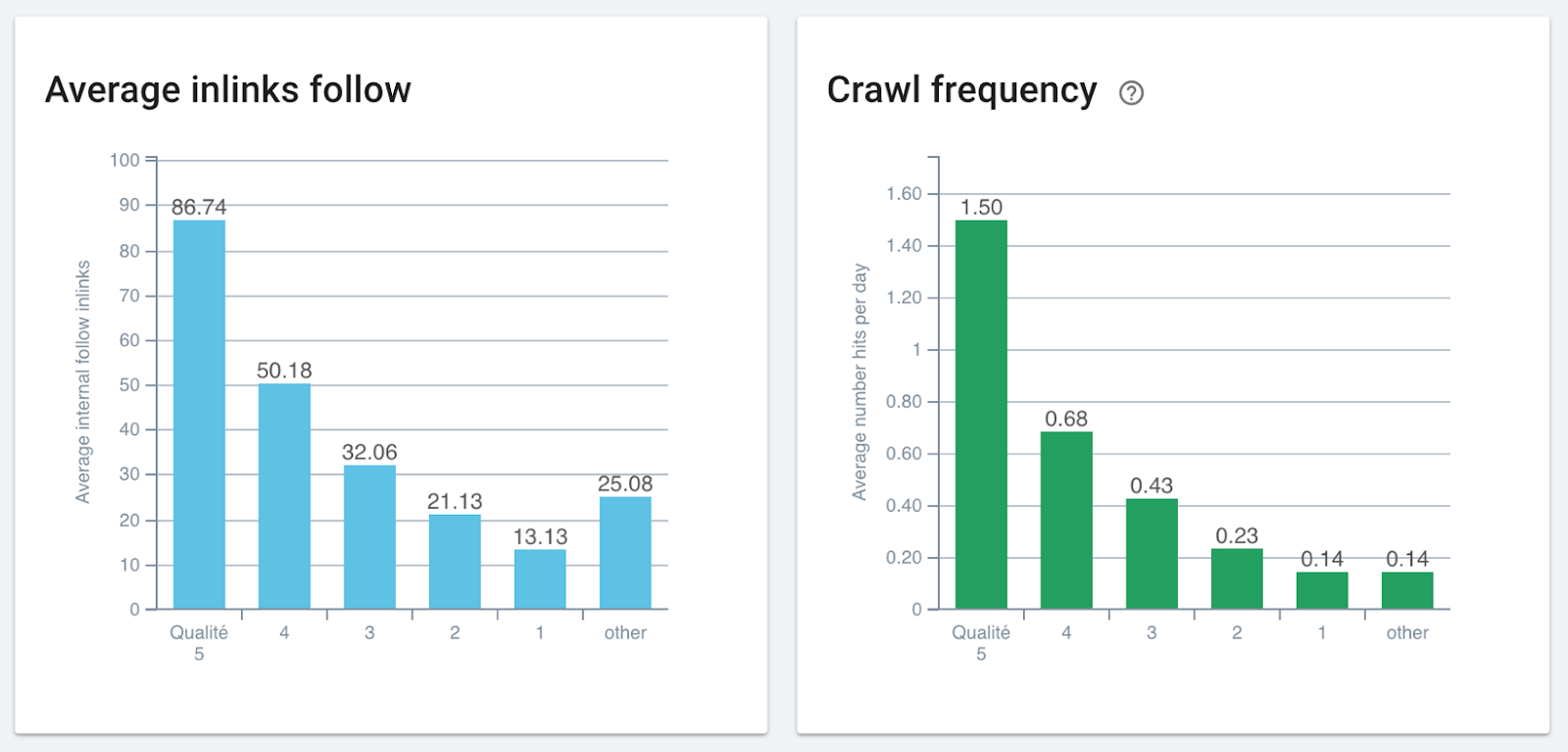
Correlation between the number of links and crawl frequency – Oncrawl’s data
Web scaling principles relies on :
- Use of massive data interpretation like natural language analysis and word embedding;
- Use of massive data correlation as the web is full of entities;
- Ontology which also includes all semantic that describes the relationships between terms or between named entities.
Optimizing rankings
Once indexed, Google scores each page of your website and uses many different computed metrics such as Pagerank, quality scores, website trust, etc and then aggregates many attributes to each page (Meta data, Title, Schema.org, N-Grams, payload, content interpretation…)
Web scaling principles also relies on:
- Use of massive data aggregation: human / computed;
- Use of massive data interrelationship / qualification: human / computed.
Understanding Artificial Intelligence
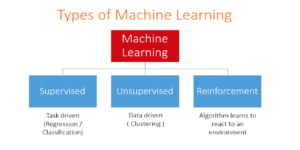
Crawling, indexing and ranking are now bounded to artificial intelligence. Algorithms, data aggregation, human/supervised validation, massive usage of data models, knowledge and interrelationship analysis refers to AI. Machine Learning can be a part of the process by adding multiple iteration cycles.
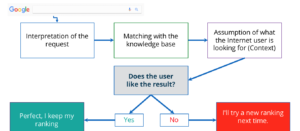
Google Rankbrain is a machine learning process and consists of re-ranking results. From interpreting a request to guessing what the user was looking for and adapting the result, Rankbrain is an ongoing test and learn process.
To keep your rankings and match Rankbrain’s guidelines, you need to help Google by maximizing exploration sessions and point the bot and users to the right direction:
- Reduce errors;
- Rectify technical issues;
- Reinforce content;
- Create depth shortcuts;
- Organize linking by objectives;
- Speed up the website.
Understanding Page Importance
Page importance also plays a huge role in the re-indexing process. A query-independent score (also called a document score) is computed for each URL by URL page rankers.
“[…] the page importance score is computed by considering not only the number of URLs that reference a given URL but also the page importance score of such referencing URLs”
The data about the Page importance score are shared to URL managers, which pass a page importance score for each URL robots, and content processing servers.
One example of a Page Importance score is the PageRank, which makes crawl rate data-driven by SEO.
Page importance patent US20110179178
Page importance can however be optimized by playing with the right metrics:
- Depth and page localisation on the site;
- PageRank, Trust Flow, Citation Flow;
- Inrank – Oncrawl internal pagerank;
- Type of document: PDF, HTML, TXT;
- Sitemap.xml inclusion;
- quality/spread of anchors;
- Number of words, few near duplicates;
- Parents’ page importance.
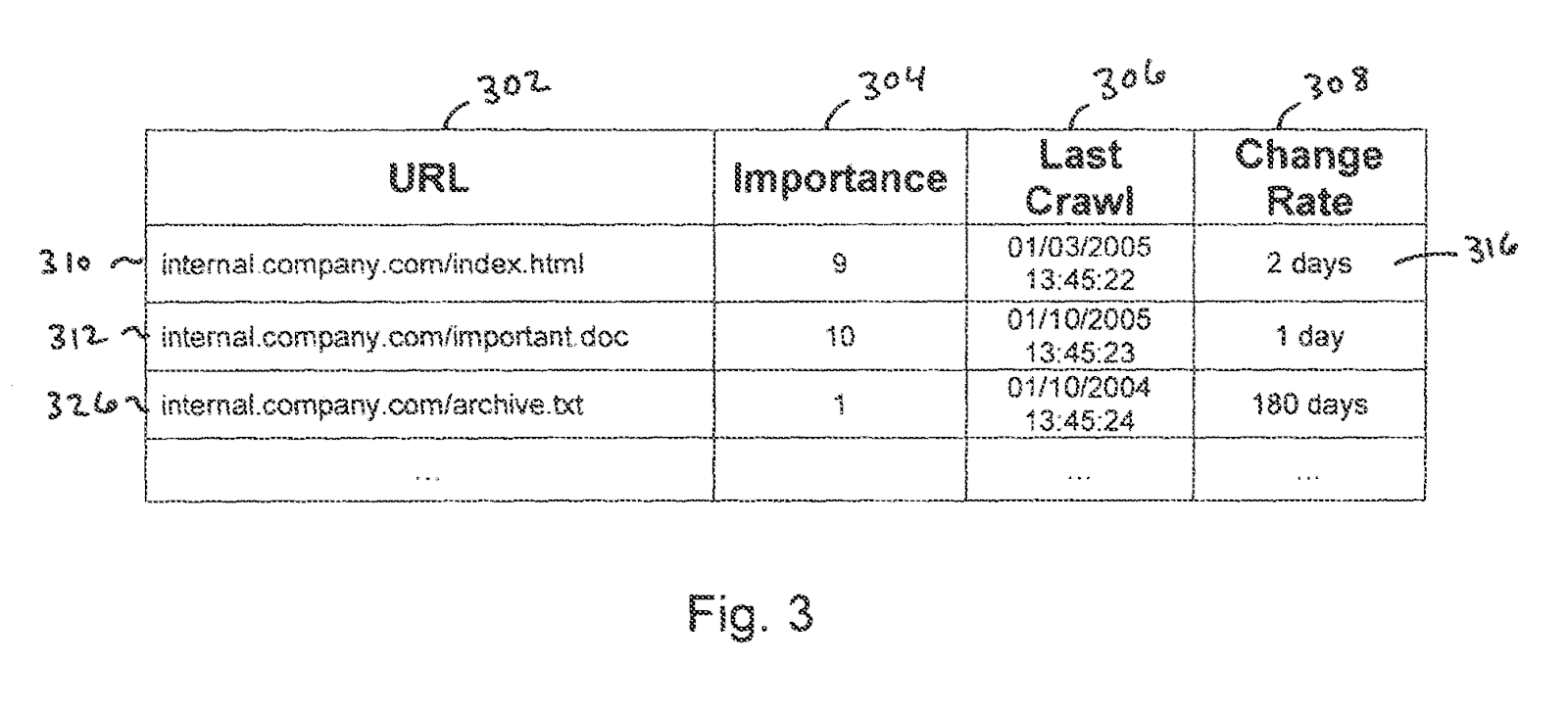
Key SEO indicators that favors Google’s crawl
Experimentations from the Oncrawl SEO team and insights shared by the community have shown that:
- Google does not like digging too deep into a site;
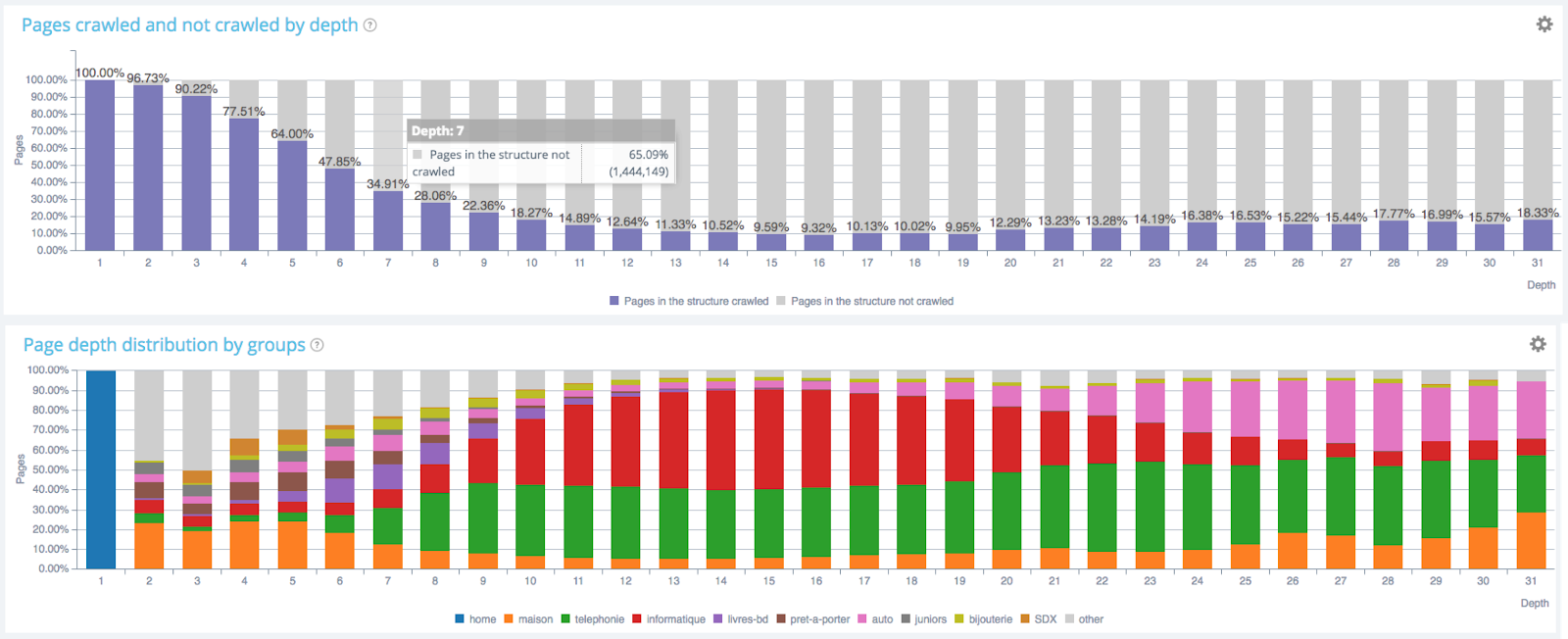
Impact of depth on crawl frequency – Oncrawl’s data
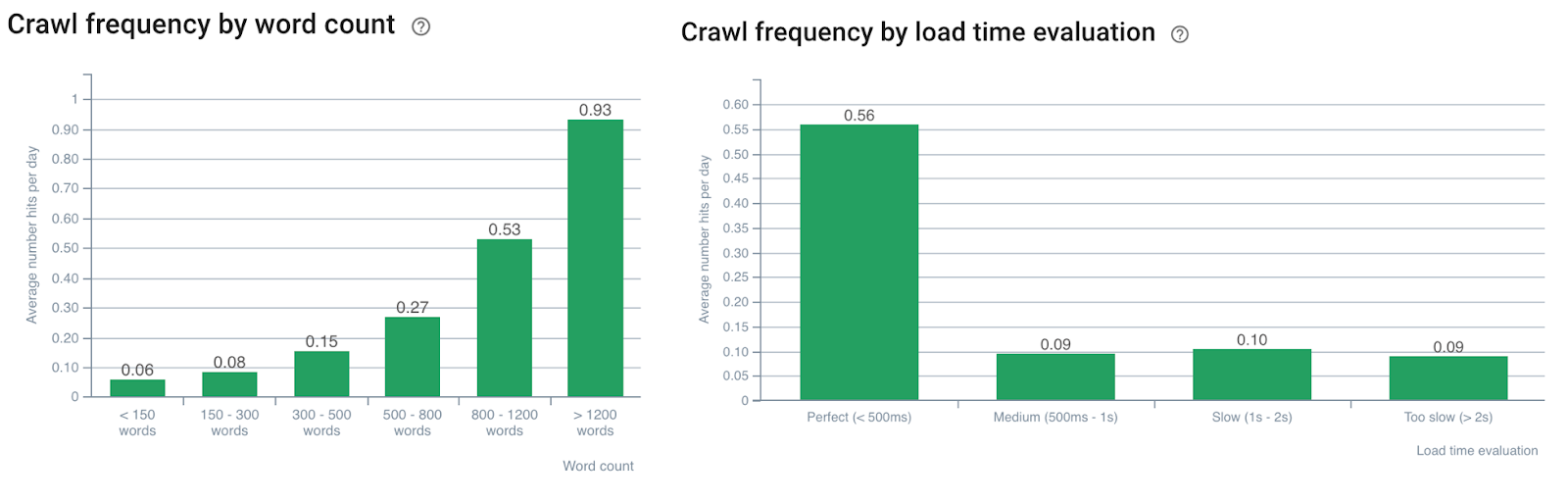
Google is sensitive to the volume of content;
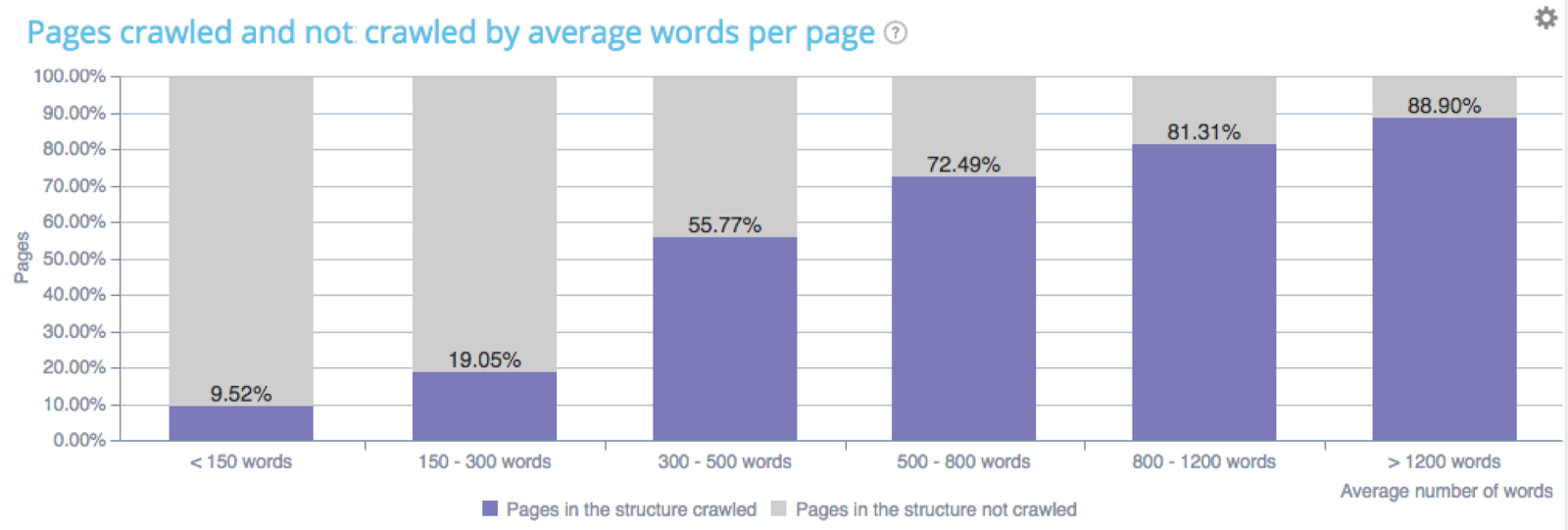
Impact of word count on crawl frequency – Oncrawl’s data
- Google is sensitive to internal popularity (Oncrawl Inrank);
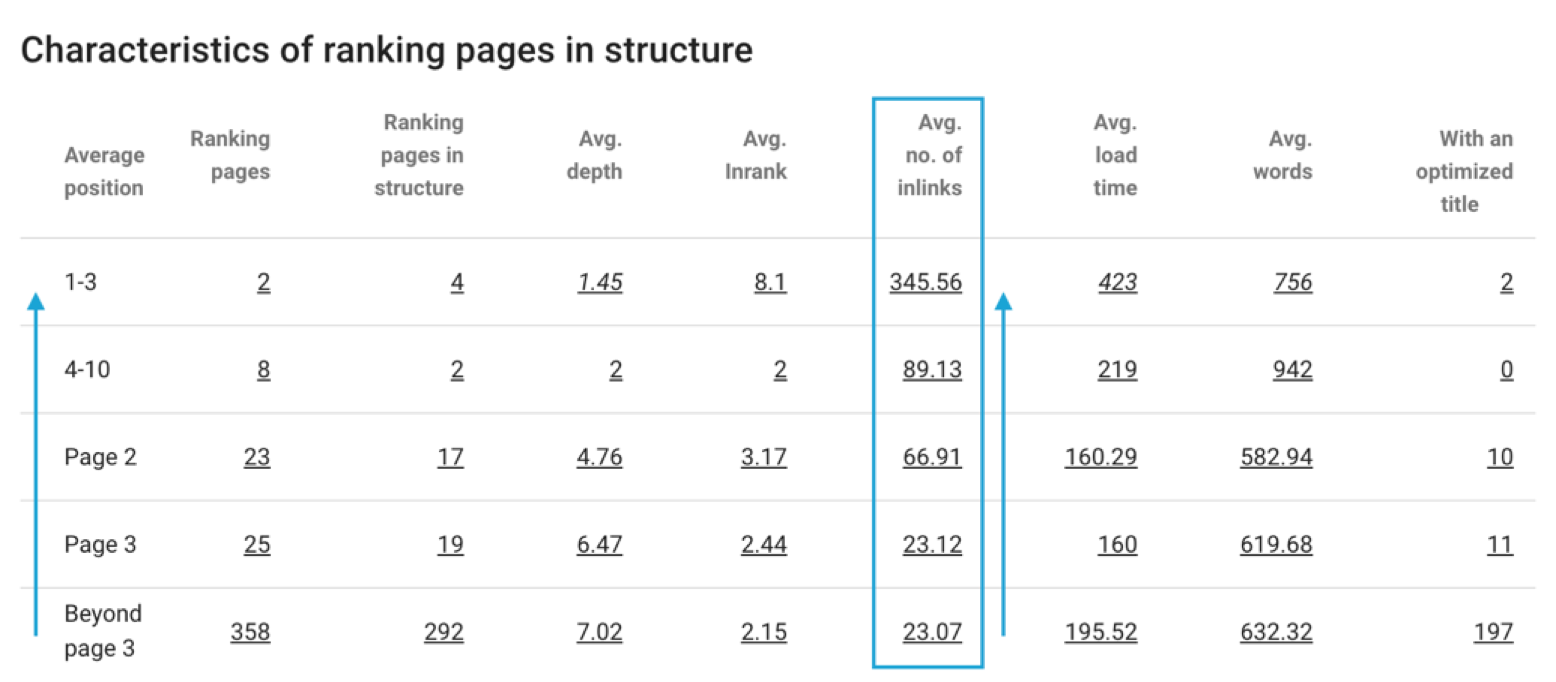
Impact of number of links on average position
- Google is sensitive to average CTR and bounce rates;
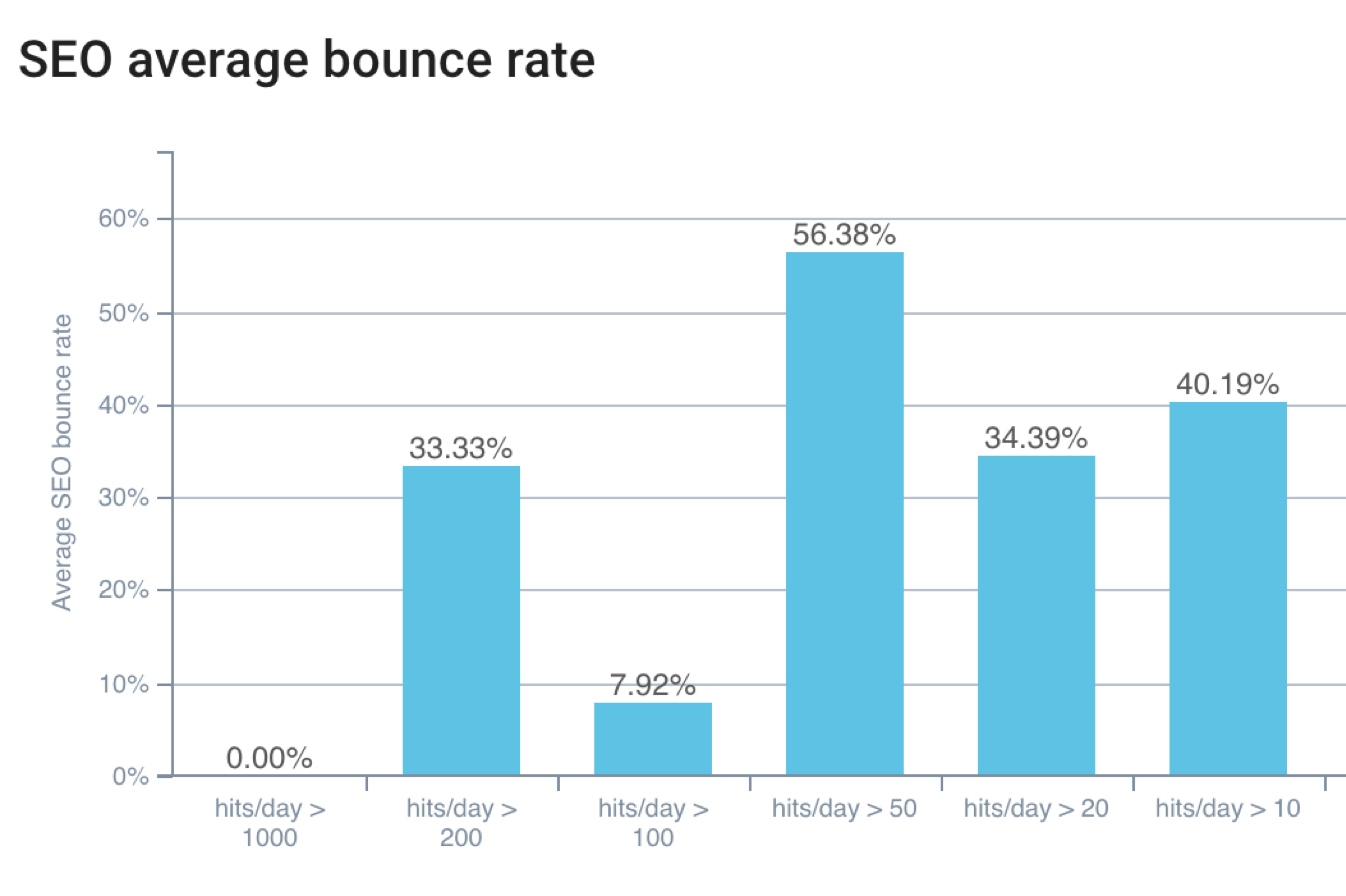
Less bounce rate= more bots hits
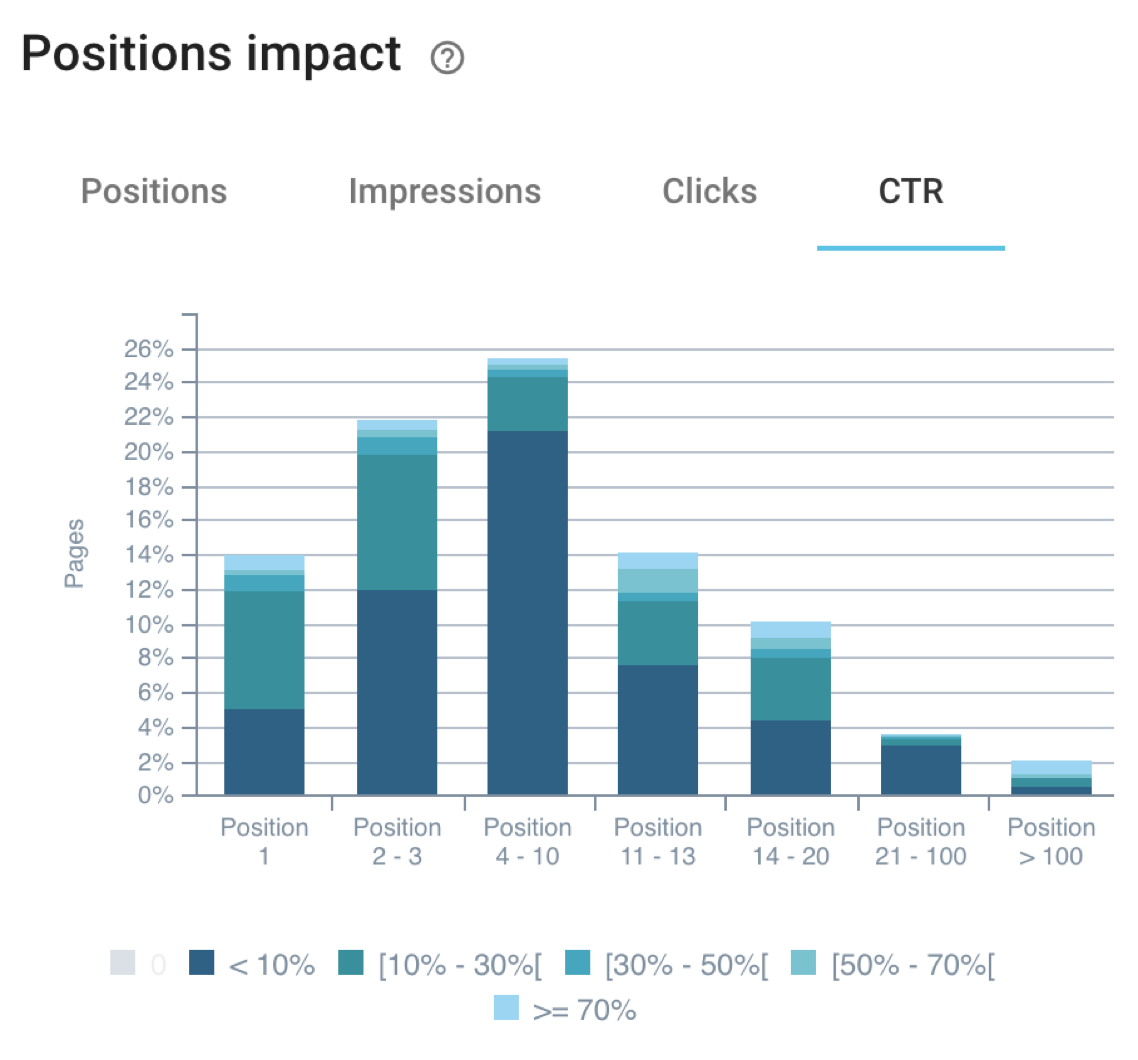
Better CTR=better positions
- Priority pages should be linked from the home, or ideally 1-2 levels from the home;
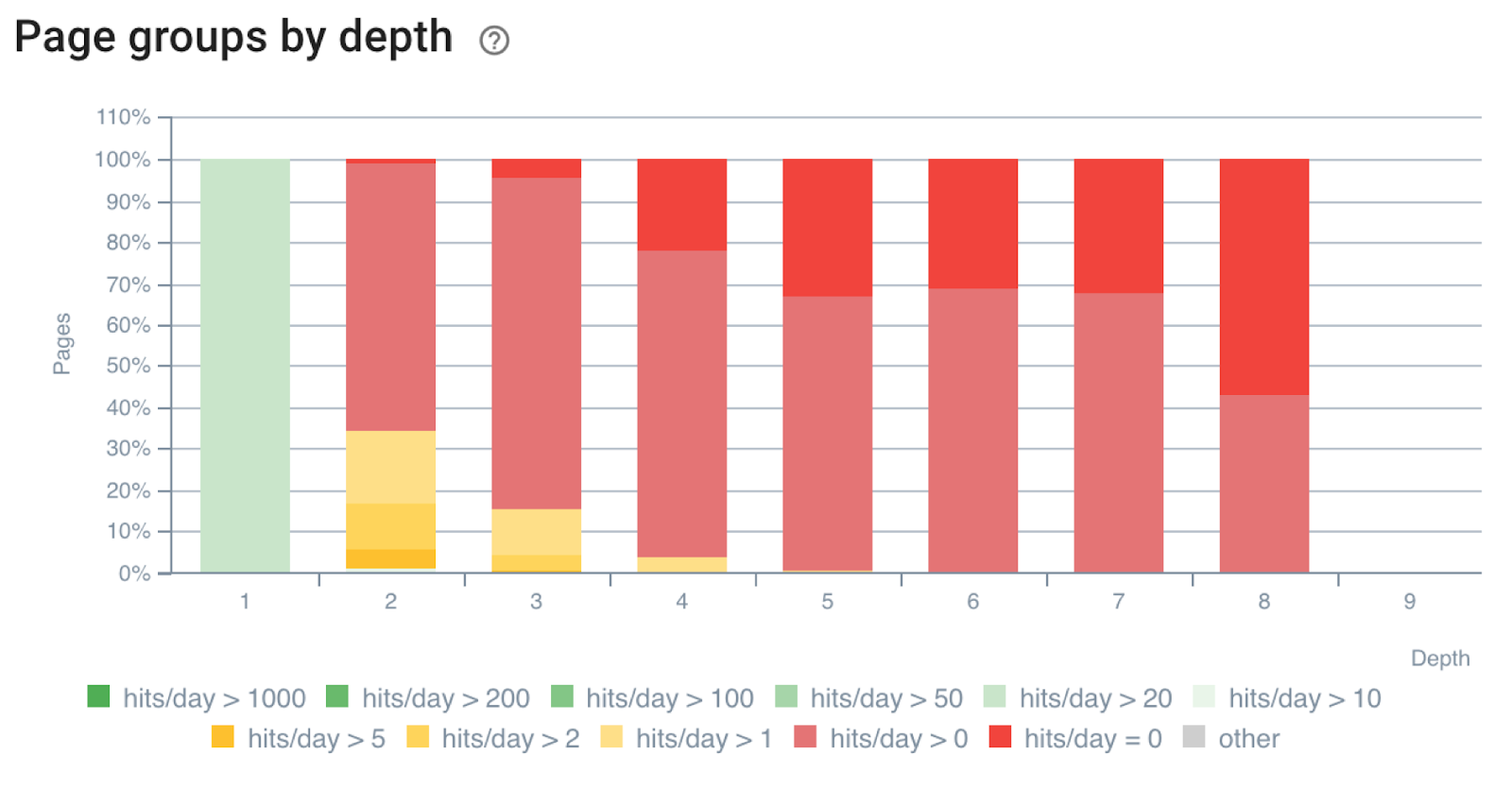
Number of bots hits regarding level of depth – Oncrawl’s data
- To be frequently crawled, a page must be fast and have a wonderful content.
Indexation and content interpretation
Google classifies three types of request:
- Transactional
- Informational
- Navigation
Depending on the type of request to rank, Google will more or less crawl you.
Google does not understand the content, but it seeks to understand concepts by using detection of named entities:
- It creates term and word weight matrices;
- It deduces page themes for the ranking process.
Understanding transactional requests
To illustrate this type of request, we have use the following request: “converse men’s chuck taylor”.
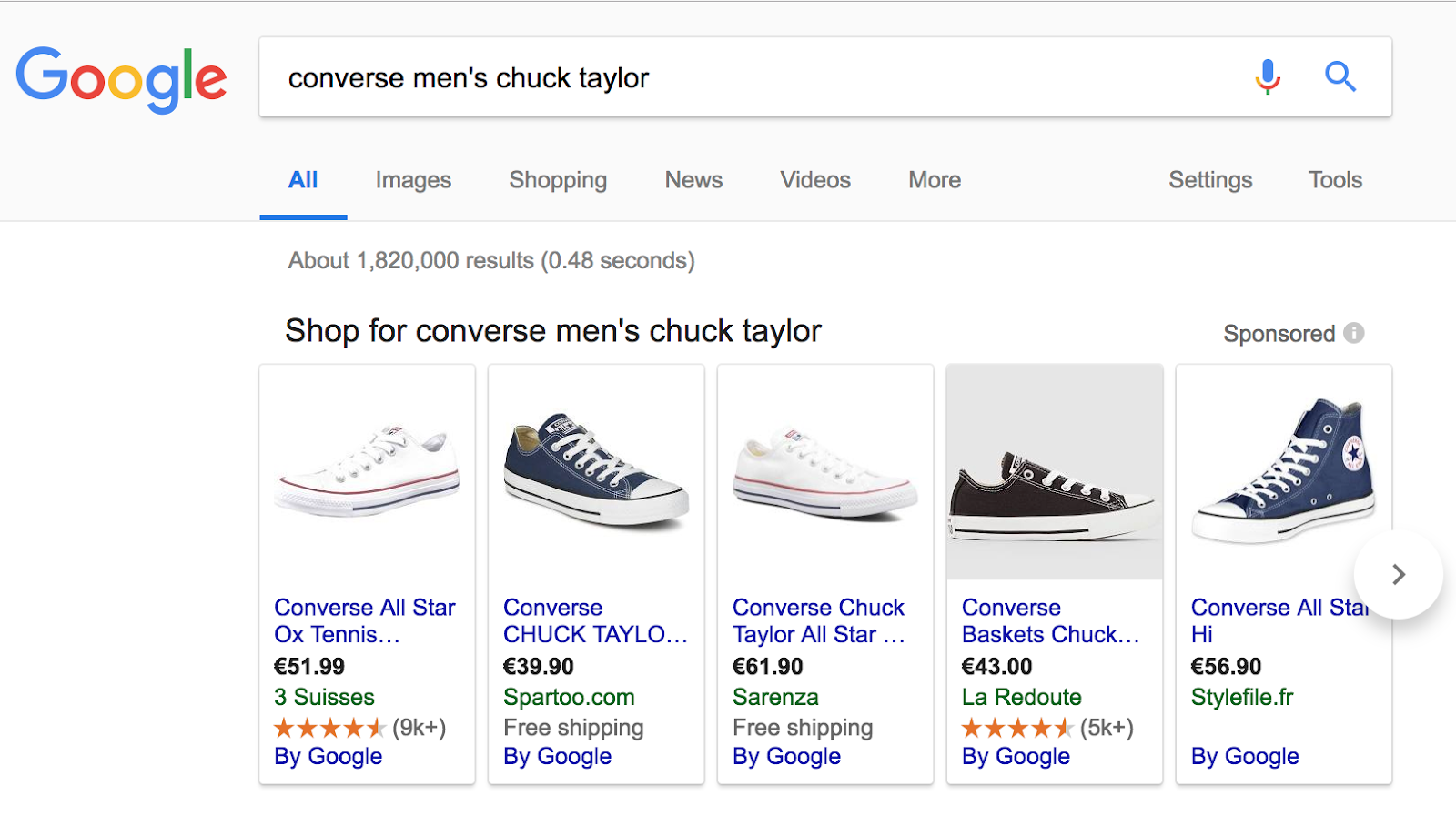
Here the user wants to get to a website where there will be more interaction.
Pages on “converse men’s chuck taylor” refers to cold content and transactional request and receive an average crawl frequency. It’s important to think the linking in terms of brand/product entity relationships.
Understanding informational requests
This type of query is made when the user is looking for a specific bit of information. For example “Clinton”.
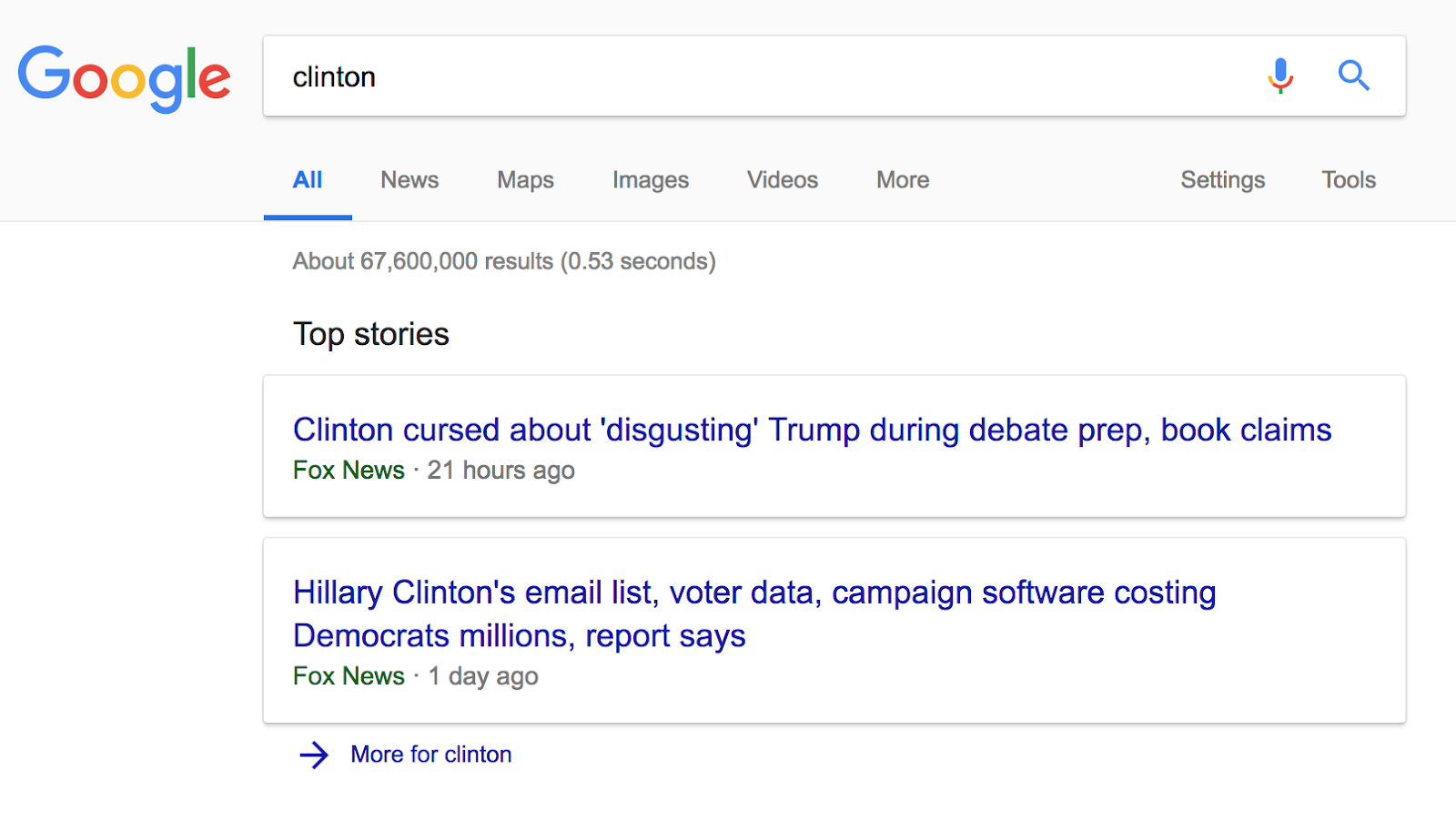
Results show pages about “Clinton” or “Trump” as this is a hot “informational” subject, receiving a high crawl frequency. The linking needs to be powerful and based on named entities.
Understanding navigational requests
Navigational requests are made by users looking to reach a particular website.
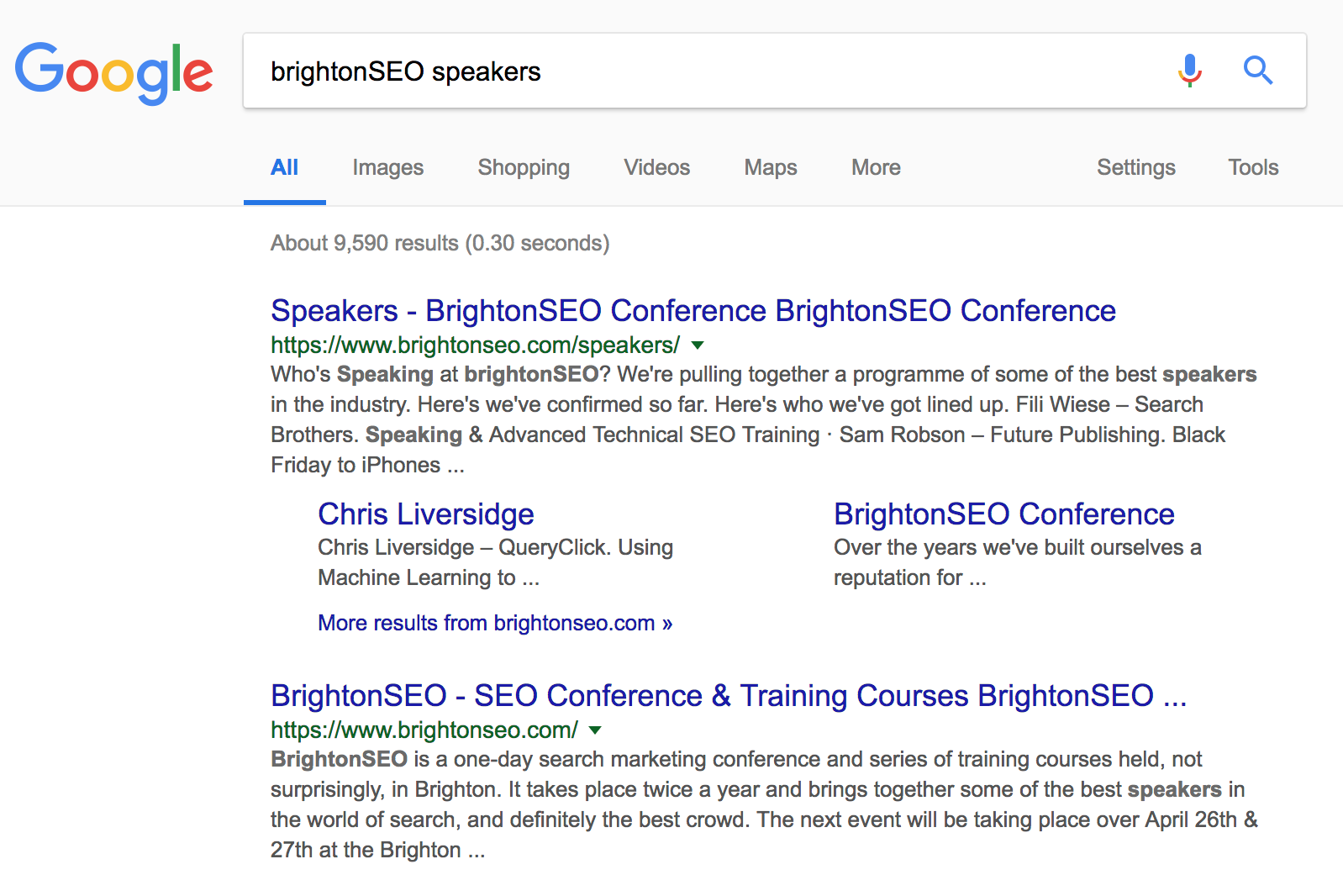
On this example, pages targeting “BrightonSEO speakers” are displayed because they are known as part of the BrightonSEO website. This website is receiving a low crawl frequency and needs to rely on good semantic SEO optimizations, Trust and Citations.
Furthermore, Rankbrain is based on Natural Language Processing. It means the algorithm is able to represent strings of text in very high-dimensional space and see how they relate to another. Google then maintains a knowledge base on named entities and understands the relationships between entities:
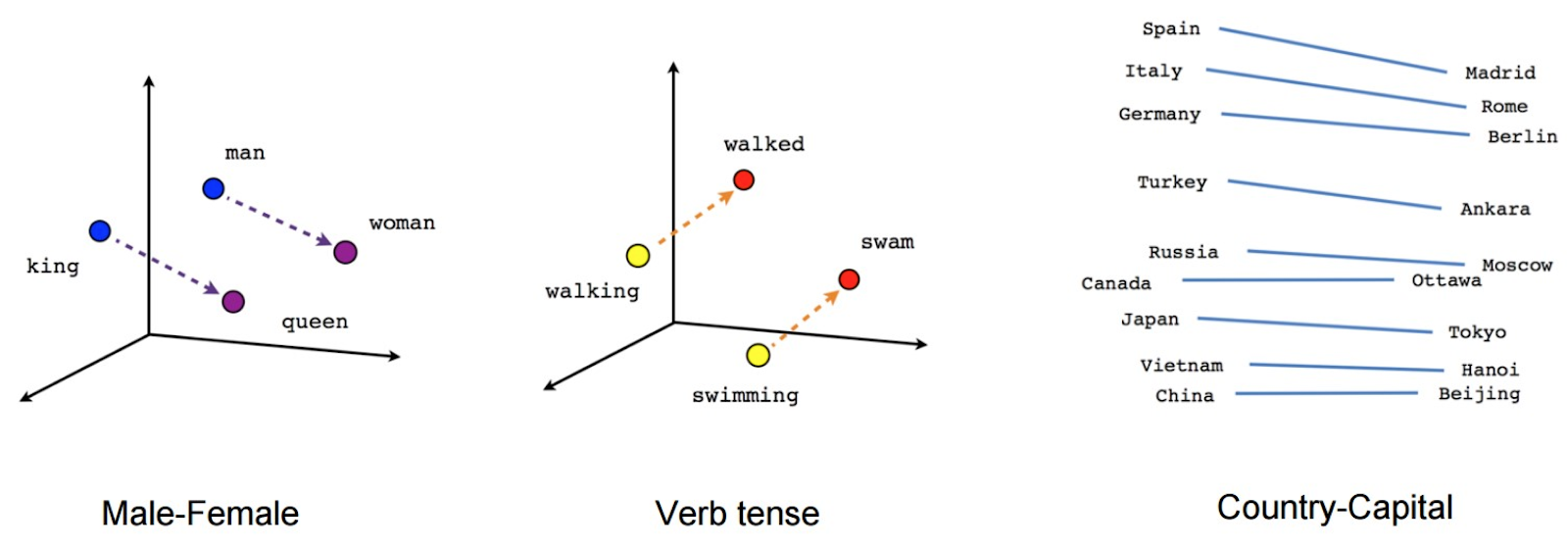
In a search engine algorithm, a tool is needed to calculate a “similarity” score between two documents.
This note is strategic for creating a relevant ranking, but it is used in combination with a very large number of other signals, rather major (like the popularity of the page), or minor (like the presence of a keyword in the page URL).
Each entity or concept is vectorized for the machines to understand:
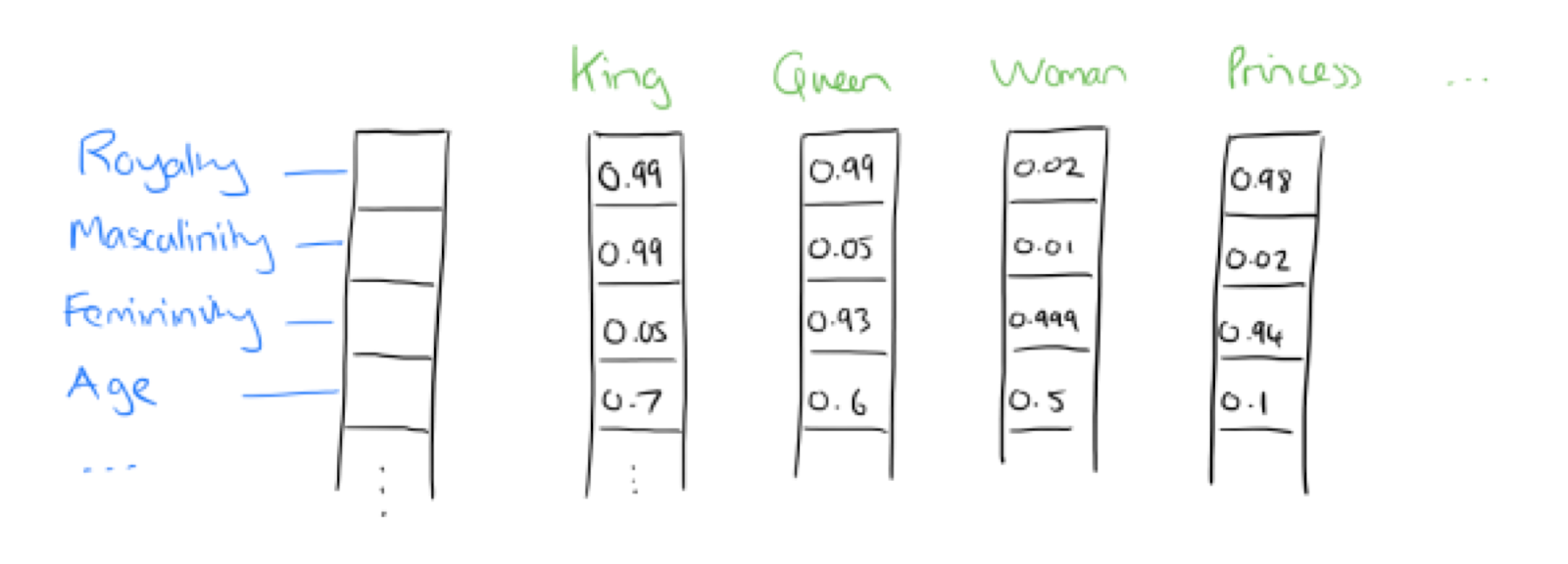
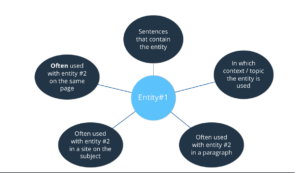
And then Google can evaluate the distance between two concepts. For each entity, Google knows:
To use a more concrete example, let’s search for “how old is the wife of Bill Gates?”
- “How old is”: assumption of a request on age
- “The wife of”: type of relation
- “Bill Gates”: individual/personality
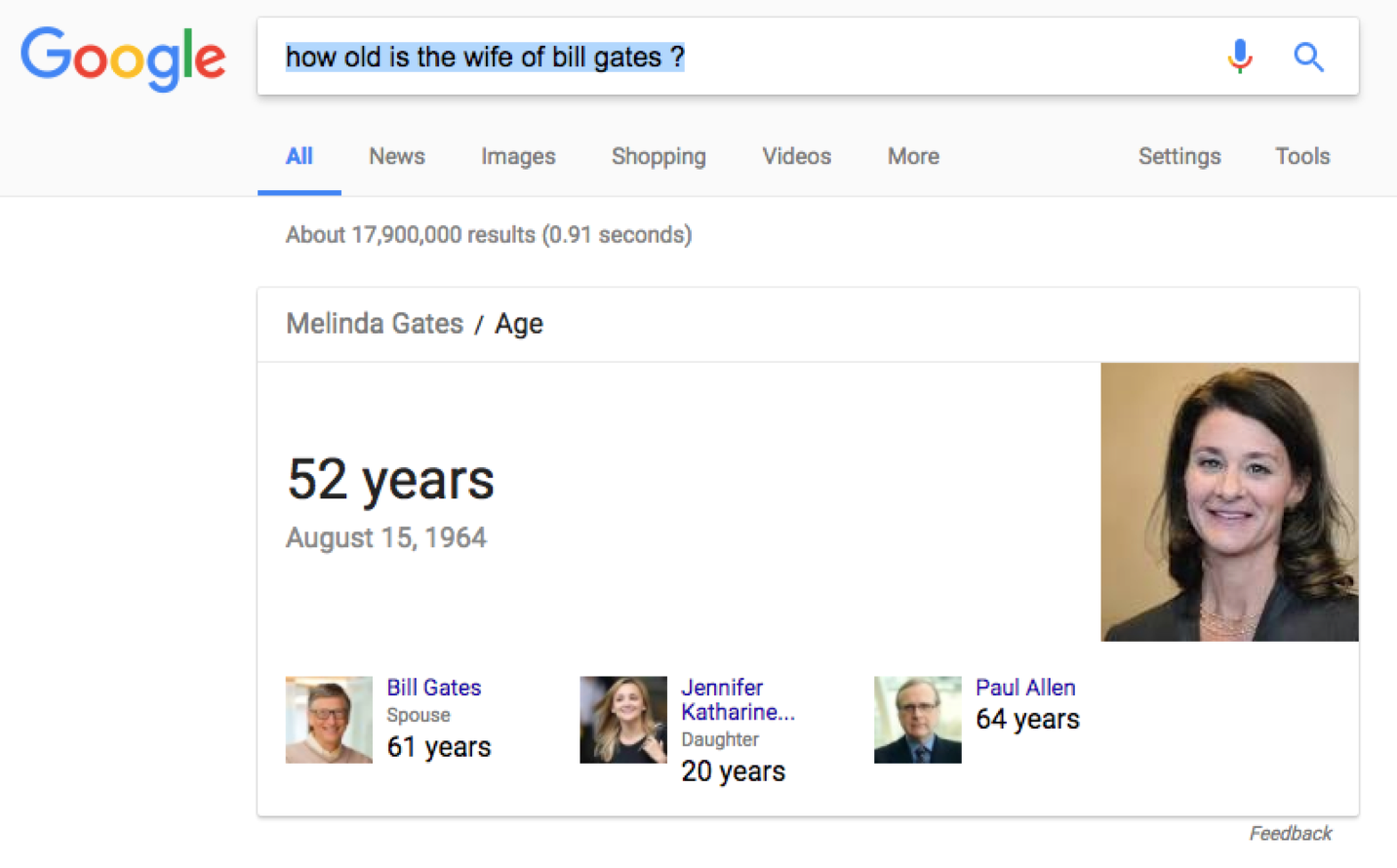
To summarize, Google will tend to crawl pages by “package”:
- On the same path (discover);
- On the same topic (recrawl).
The more content it will met with expected entities (related to the theme), the deeper it will crawl. The type of entity, its rarity or popularity will directly impact the crawl frequency.
Internal linking must then be thought from the relationship between entities present in your content. You can check you named entities directly within your crawl reports.
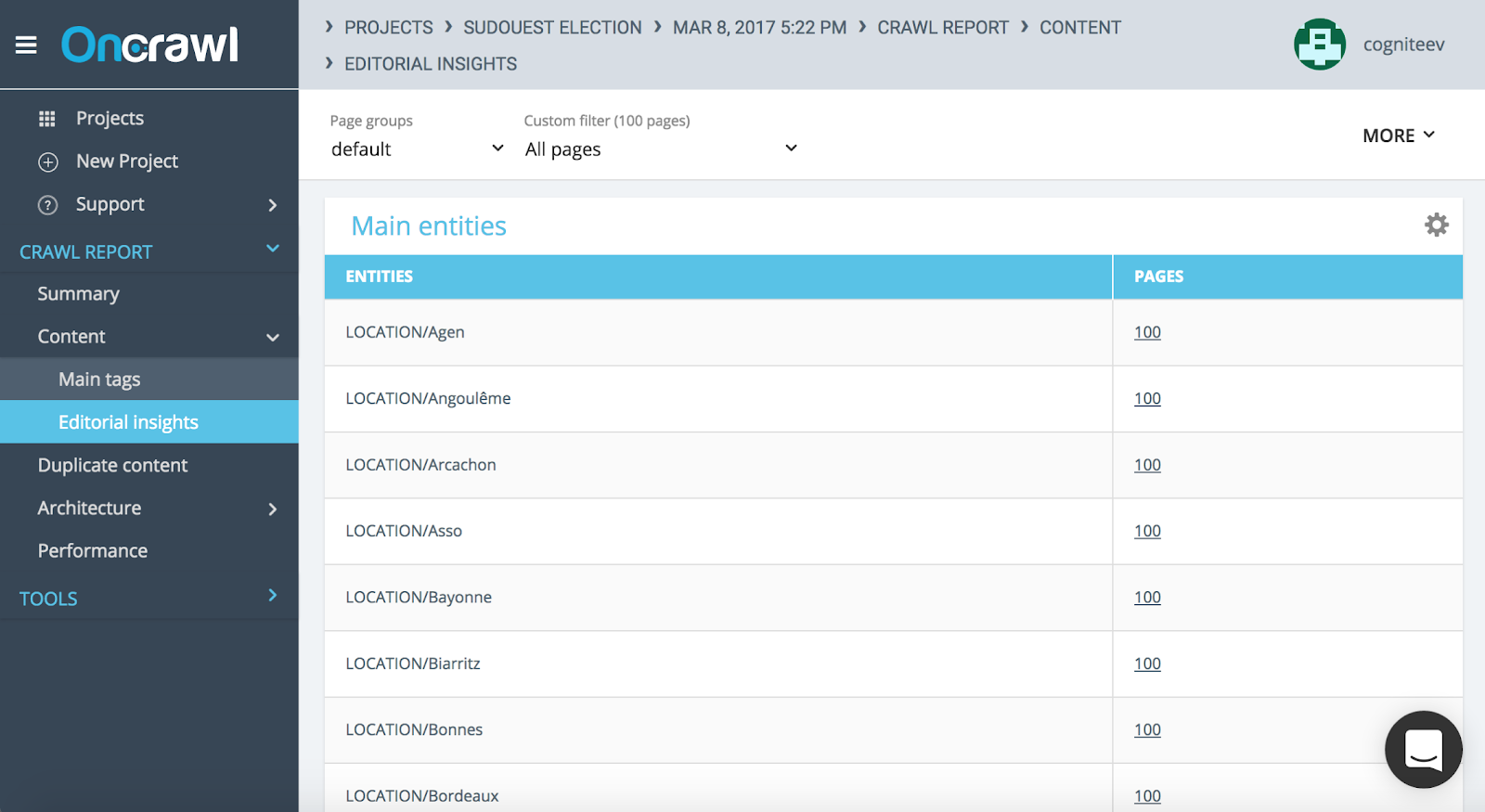
Editorial insights tab about named entities within Oncrawl’s crawl report
How to maximize your efforts regarding Rankbrain?
First, map your website by:
- Type of content;
- Pages categories.
Then, understand which entities are present within your content and analyze how pages with entities are linked.
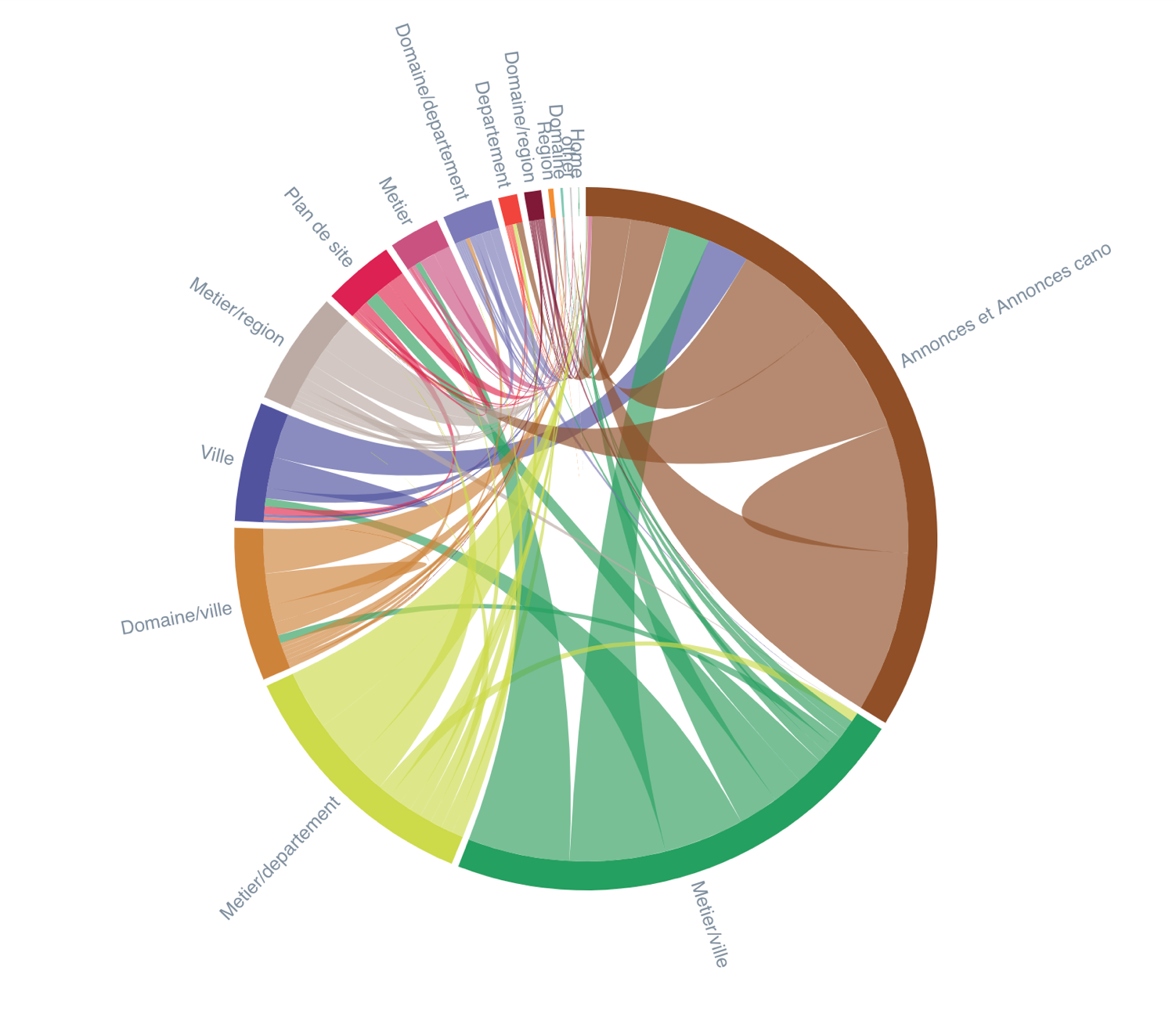
Inrank flow: Shows how internal linking popularity is spread – Oncrawl’s data
To do so, the first step would be to crawl your website in order to:
- Categorize your pages;
- Extract named entities by pages groups;
- Identify pages with or without named entities to adjust your content;
- Monitor the number of words per groups of pages;
The goal is to define the ideal content metrics to maximize your crawlability.
![]()
![]()
Then, use named entities in your link anchors, create packages of linked pages according to entity typology. Here is the example of a media site:
Conclusions
Crawling, indexing, ranking and re-ranking are all based on artificial intelligence and machine learning principles.
It is not so intelligent because they need us to validate models. Never forget that they are only algorithms: you have to know and manipulate the metrics they take into account to manipulate them!
- Crawling consumes energy, simplify bots life by paying attention to depth, navigation shortcuts, duplicate and especially load time, weight in the current index mobile first context. Follow crawl budget with your logs!
- Indexing is based on internal/external metrics content. Moreover, Google is using the Knowledge Graph as a learning base for named entities.
- Ranking refers to the consistency of all these data with user intentions and depends on quality (technical) and relevance (semantic) scores. Also, user’s behavior and intention are taken into account such as his personal background of research and visit.
The key is to make users want to come back to manipulate the CTR and bounce rate! In other words, favorise titles, meta description, content, speed and UX/UI!