
We’re excited to bring you a set of new enhancements to make analyzing your crawls and interpreting the results as pleasant as a summer day. If you’ve been at your keyboard over the past few weeks, you may have already noticed some of these changes. If you’ve been away, we hope you’ve enjoyed your vacation! Here’s what you can look forward to when you get back.
We’ll take you through the following product updates:
- Shortcuts to the answers to your questions about each URL
- New automatic segmentation functionalities
- New crawl mode: URL list
- Bonus improvements
Shortcuts to the answers to your questions about each URL
We’ve added a URL navigation shortcut menu in the Data Explorer and almost anywhere else you see a table of URLs.
Next to each URL in the table of results, you’ll now find an arrow that opens a shortcut menu.
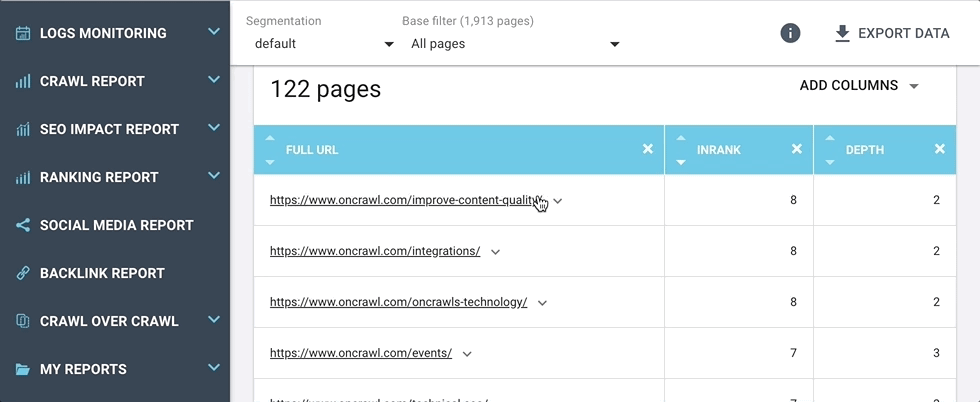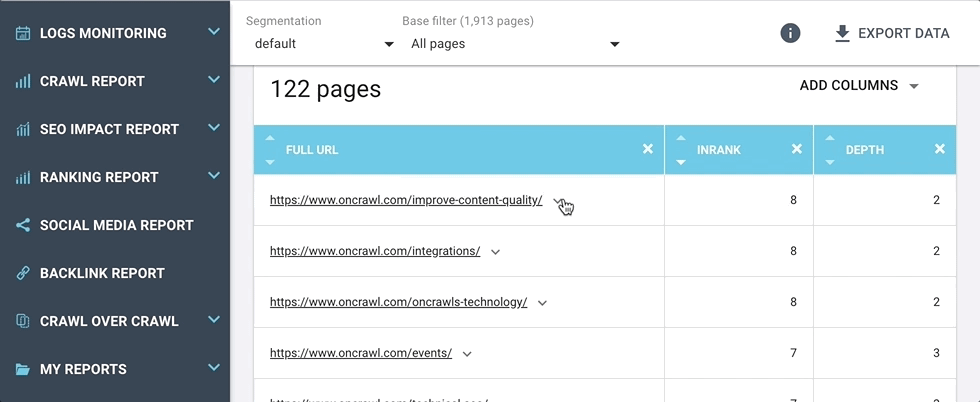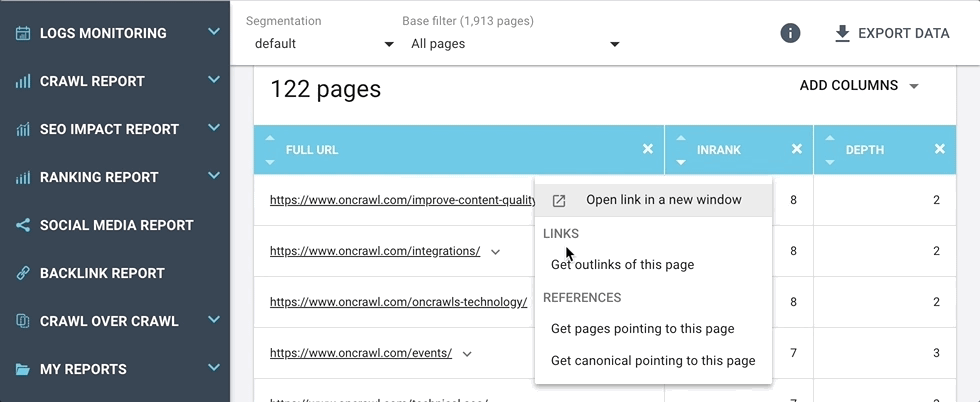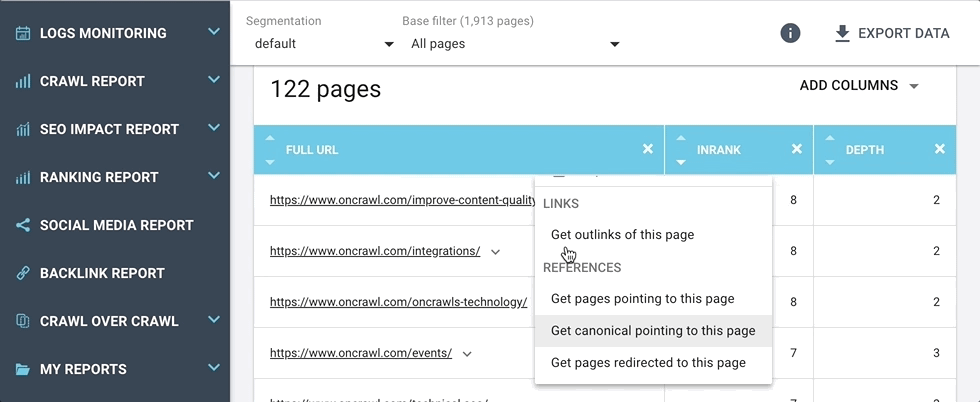
These shortcuts take you directly to the answers to questions you might have about the URL, for example:
- Where did this weird-looking URL come from?
- I can see that this page has duplication issues for the description, but what pages have the same description?
- I know this page is part of cluster for hreflangs or for duplicate content, but what are the other pages in the cluster with this page?
- If this page has a matching canonical, that’s great. But what are the pages that list this URL as their canonical page?
- I know a bunch of pages redirect to this URL, but which ones are they?
This menu is dynamic, and, when possible, can include shortcuts to the following information:
- Lists of linked pages (including inlinks, outlinks, redirections, canonicals, hreflangs)
- Lists of pages with shared duplicate content
- Lists of events for this page
- List of bot hits for this page
New automatic segmentation functionalities
We’ve expanded the ability to create segmentations.
By default, we still offer you a segmentation based on the first directory (the “URL first path”) in the URLs crawled.
When you create a custom segmentation, we now offer automatic analysis of a previous crawl to create a segmentation based on custom fields, or on the URL host.
All segmentations are available for logs and for crawls. However, if you try to use a segmentation criterion that can’t be applied to logs, or one that can’t be applied to crawl results, we’ll warn you right away that your segmentation won’t be able to be used for all types of reports. If you’ve received a warning that your segmentation can’t be used on crawl result reports, for example, the report won’t be available as a choice when viewing crawl results.
How to segment your crawl results based on custom fields
To use a custom field, you must have a previous crawl with custom fields. We’ll use those fields to automatically create a segmentation for you. Check out our documentation if you need a hand with creating custom fields for a crawl.
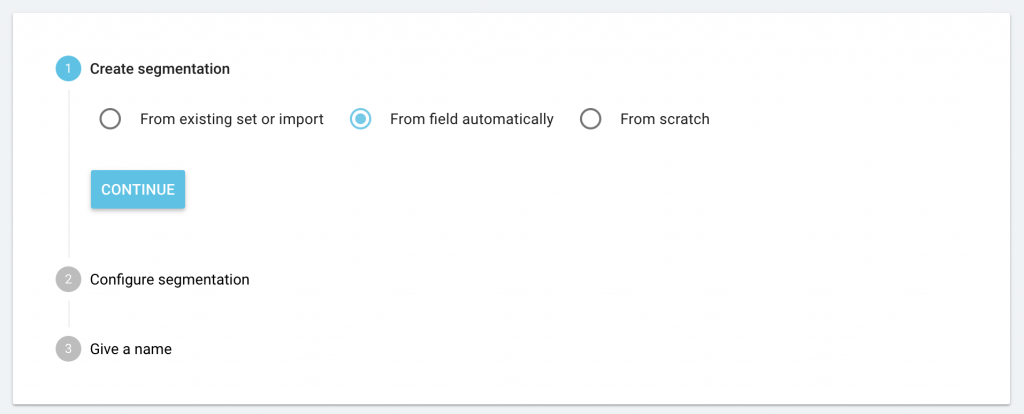
From the project home page, click “Manage segmentation”, then on “+ Create segmentation”.
You’ll see the new option “From field automatically”, as well as the previous options: “From existing or import” and “From scratch”. Choose “From field automatically” and click “Continue”.
From the drop-down menu, select the previous crawl with the custom fields you want to use.
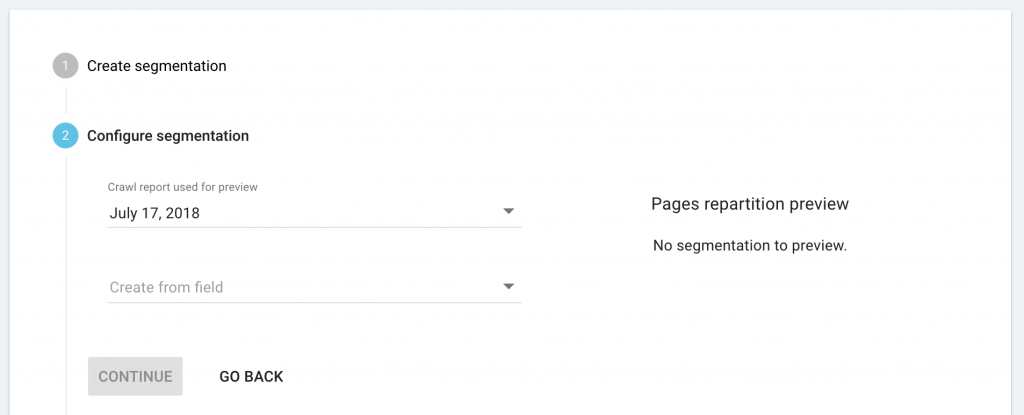
From the drop-down menu, select the custom field you want to use to create an automatic segmentation.
Click “Continue” to provide a name for the new segmentation and to save it.
Your new segmentation will not be available for use with log monitoring, unless the custom field you chose is based on the URL of the page, or on other data available in your logs.
How to segment your crawl results based on URL host (when crawling subdomains or multiple domains)
To use the URL host to automatically generate a segmentation, you must have already run a crawl with subdomains, or a crawl on multiple domains.
From the project home page, click “Manage segmentation”, then on “+ Create segmentation”.
You’ll see the new option “From field automatically”, as well as the previous options: “From existing or import” and “From scratch”. Choose “From field automatically” and click “Continue”.
From the drop-down menu, select the previous crawl with the multiple domains or subdomains that you want to use.
From the drop-down menu, select the field “URL host”.
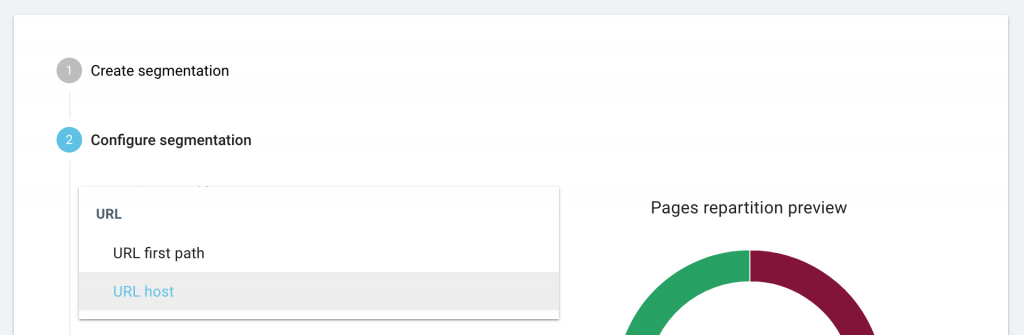
Click “Continue” to provide a name for the new segmentation and to save it.
This segmentation is based on the URL and will apply to all of your reports.
New crawl mode: URL list
You asked, we delivered. You can now crawl a list of URLs.
How to crawl a list of URLs
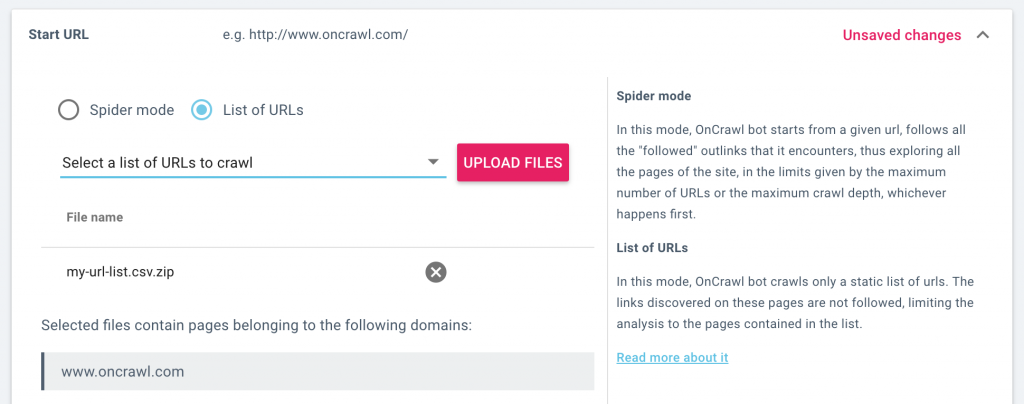
When setting up a crawl, you can now decide whether to crawl the site as a standard crawler that explores the structure by following the links on each page it visits, or whether to crawl a static list of URLs.
When crawling a list of URLs, the crawler will visit each page on the list you provide, but will not follow any of the links. This limits the crawl to the URLs in the list.
In the crawl settings, select “URL mode”, then upload a list of URLs. You can also select a list of URLs that you’ve uploaded previously. When you launch a crawl, only the URLs in your list will be crawled.
You can view, manage and upload URL lists from the Data sources page. From the project home page, click on “Add data sources”, then on “URL lists”.
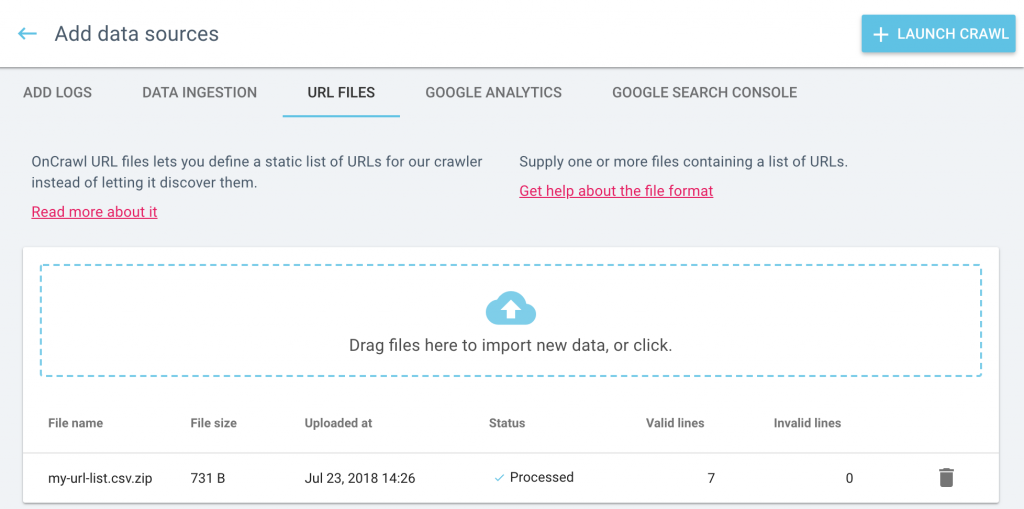
Check out our documentation for more details on the differences between crawling in spider mode and in URL list mode.
Bonus improvements
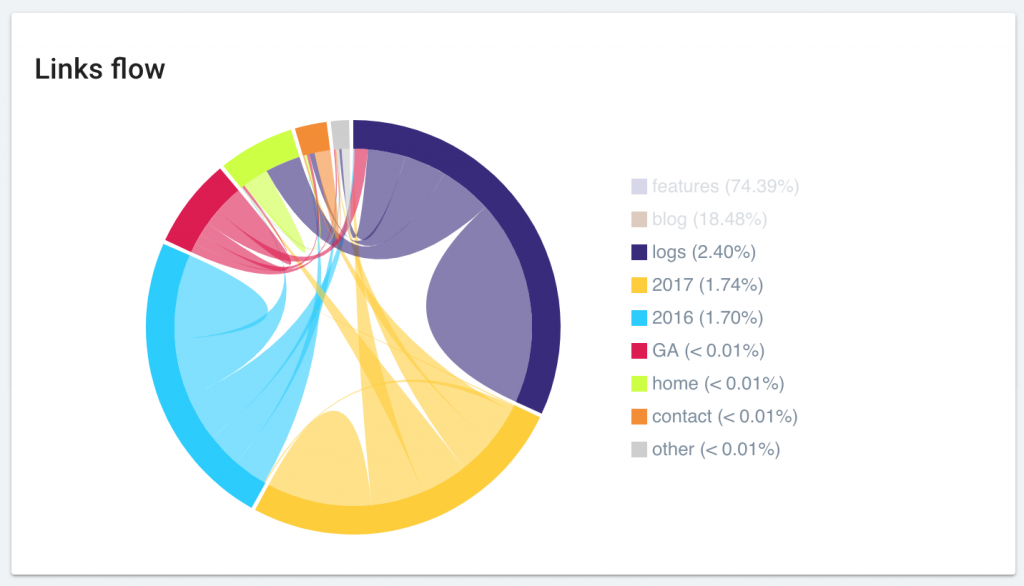
Link Flow diagram enhancements
We’ve improved the display of the “Link flow” diagram. Your favorite chart is now more beautiful than ever and even easier to read.
More feedback when setting a start URL
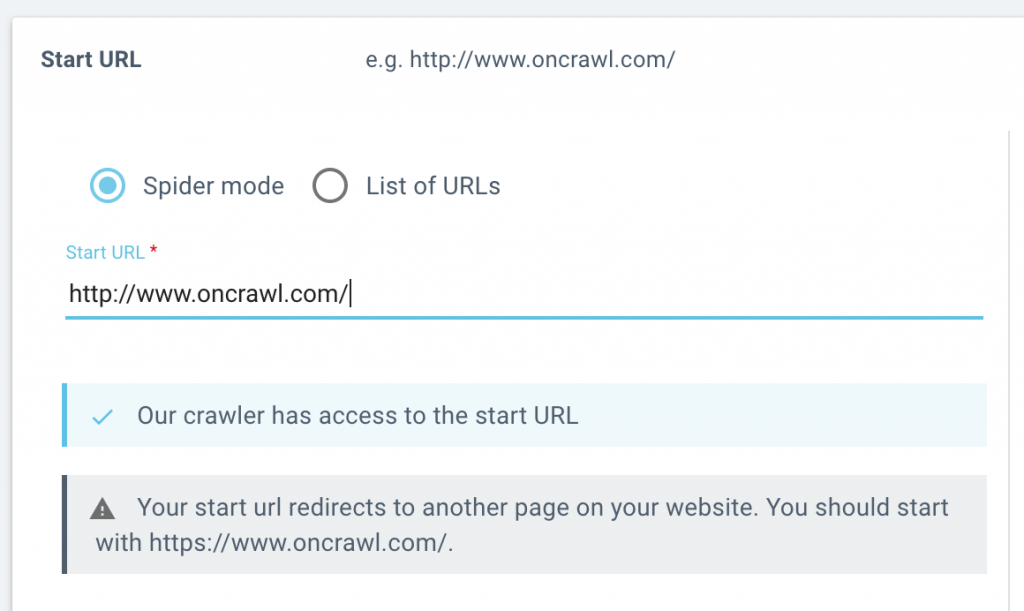
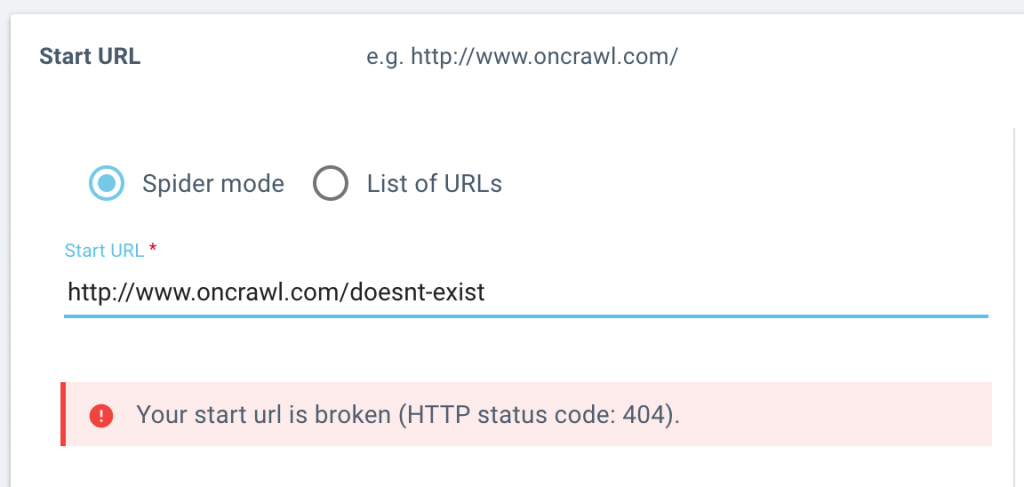
We’ll let you know if the start page you listed can be reached by our crawler, or if it’s redirected.
When setting up a crawl, you’ll know right away whether the crawl be able to advance past your start URL. If we encounter a problem, we’ll let you know if:
- your start URL can’t be reached (returns a 4xx or 5xx)
- your start URL is redirected (returns a 3xx status code)
- your start URL can’t be crawled (robots are prohibited by robots.txt)
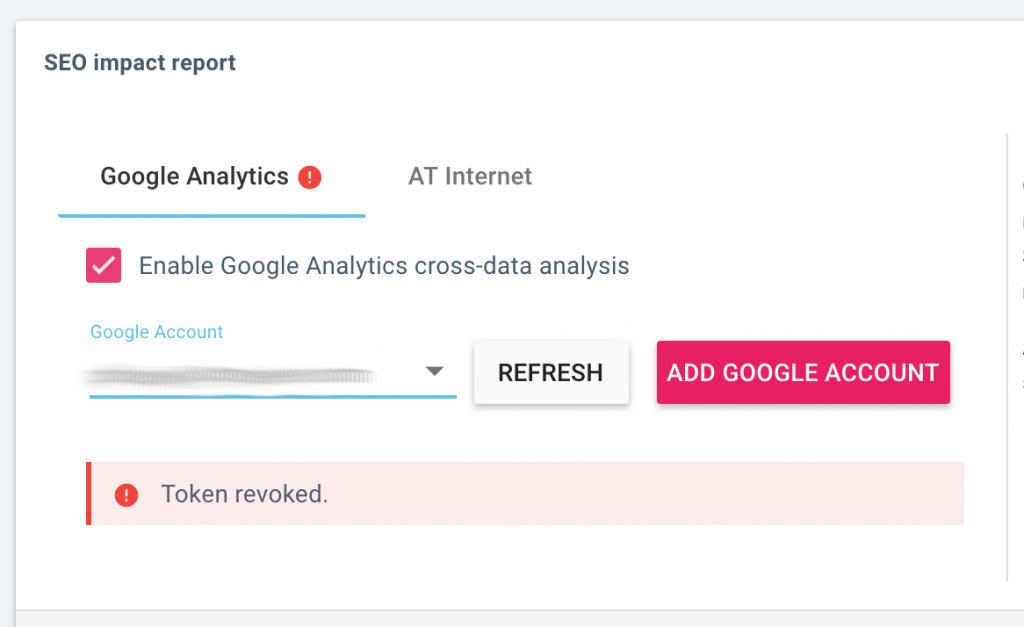
More feedback when connecting a third-party service
When setting up a new crawl, we now let you know right away if the connection to a third-party service is successful, or if we’ve encountered a problem.
This applies to the crawl settings in the following sections:
- SEO impact report: connection to Google Analytics or to AT Internet
- Ranking report: connection to Google Search Console
- Backlink report: connection to Majestic
Find all of your external data and integrations in one place
We’ve renamed the “Add integrations” button to “Add data sources”.
When you click on the “Add data sources” button, you can navigate among the different sources by clicking on the tabs at the top of the screen.
You can add your external and third-party data here:
- Log files used for log monitoring, SEO visit reports, and crawl budget analysis
- Data ingestion files, used to add custom fields to the analysis of each URL
- URL files, used to crawl a list of URLs
- Google Analytics accounts, used for SEO visit reports and googlebot behavior
- Google Search Console, used for ranking reports and keyword information
It’s all in one easy-to-find place.
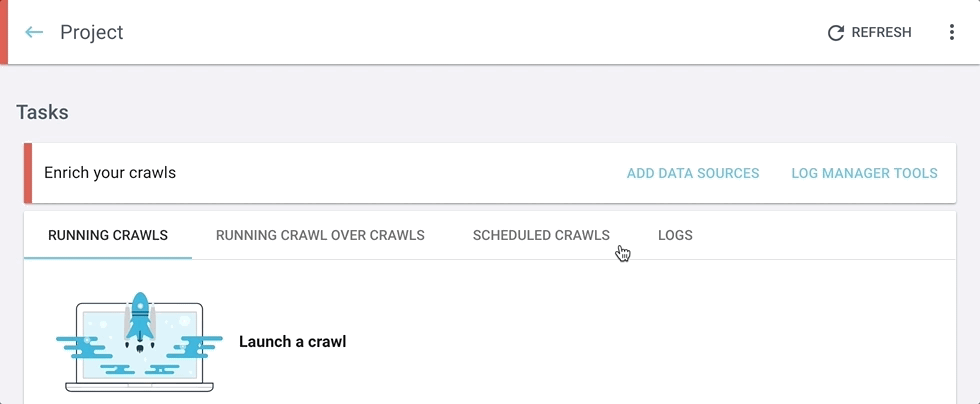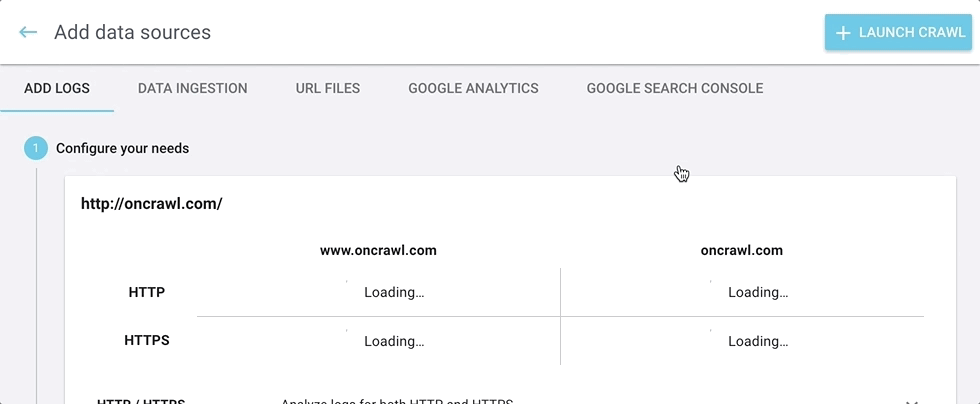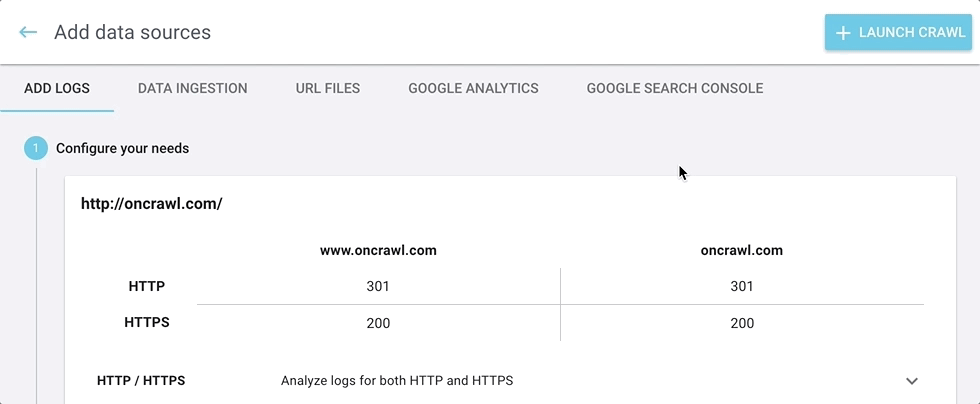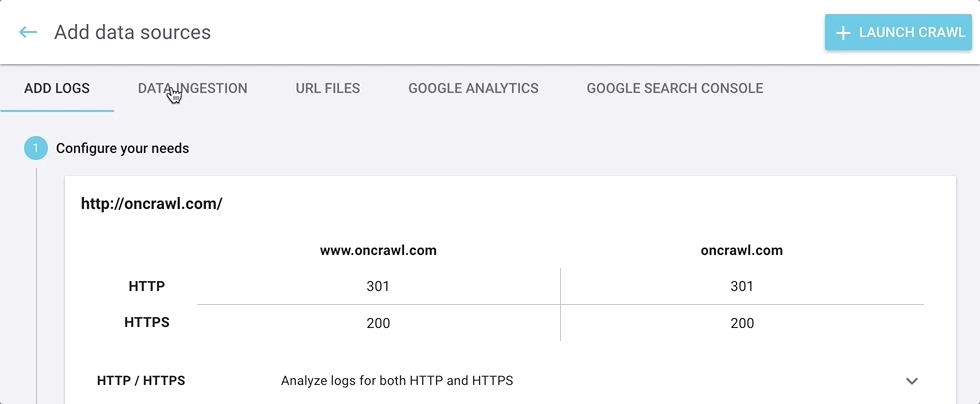
You can still find the log manager tool in its usual location, at the right of the “Enrich your crawls” tab under “Tasks” on your project homepage.
