Your site's technical SEO determines what gets seen
Audit and optimize how traditional and AI search engines view your site









Get the data
to support your technical SEO decisions
What Oncrawl offers
Run comprehensive audits of your site's structure, crawlability, indexing signals, and internal linking.
Analyze server logs to see how Googlebot, Bingbot, and AI bots interact with your site.
Monitor the technical factors that influence crawl efficiency and indexing.
Put your technical SEO data to work
Audit and monitor your site's technical health
Your team shouldn’t have to find out about technical problems from a traffic drop.
- Run technical SEO audits across complex sites.
- Surface crawlability, indexing, and rendering issues systematically.
- Monitor technical health over time and detect regressions early.
- Use custom data points alongside standard metrics to match your workflow.

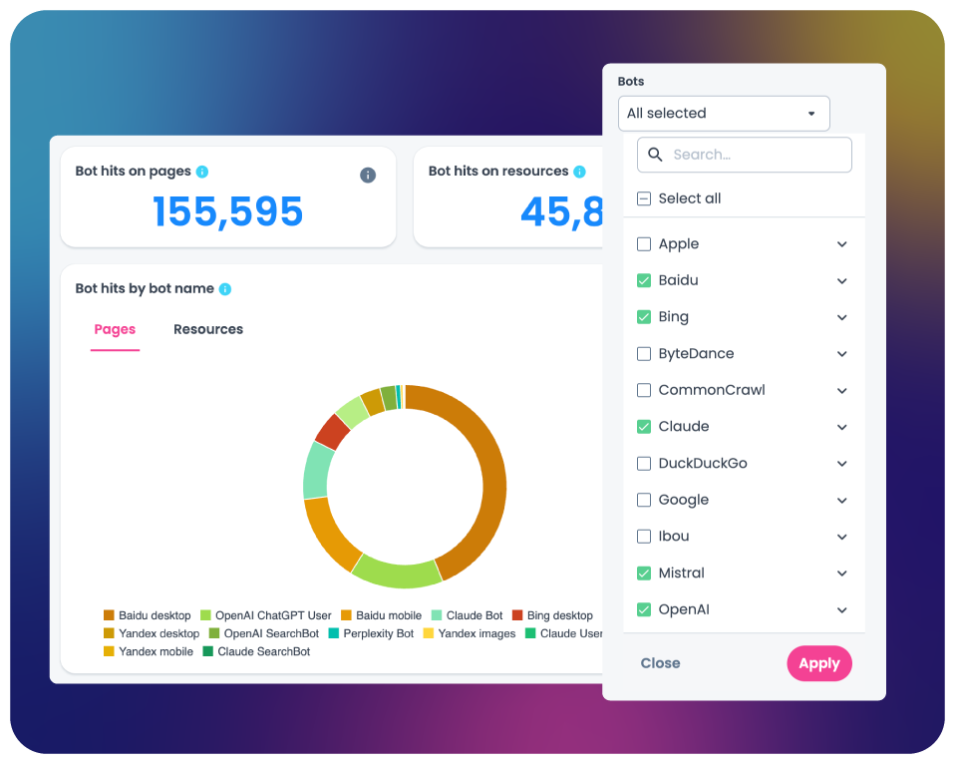
See how bots actually crawl your site
Your log files show what search engines and AI systems actually do on your site.
- Monitor how Googlebot, Bingbot, and other crawlers navigate your site.
- Track AI bot activity on your site.
- Identify wasted crawl budget and inefficient crawl paths.
- See which pages search engines prioritize and which they ignore.
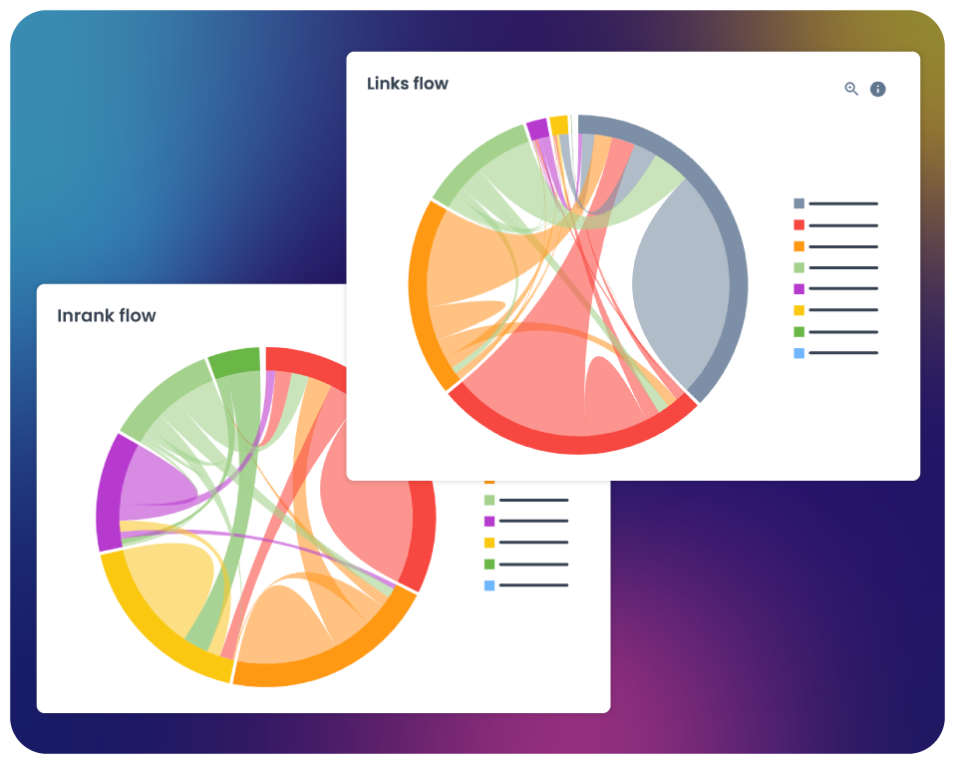
Strengthen your site architecture and internal linking
Spot architectural weaknesses that limit how effectively search engines navigate your site.
- Find orphan pages and sections with weak or broken internal links.
- Analyze how link equity is distributed across your site’s architecture.
- Identify structural bottlenecks where important pages are buried too deep.
- Ensure your internal linking strategy supports both crawl efficiency and content prioritization.
The foundation your SEO strategy
depends on
See what Oncrawl can do for you
Book your demo (nouvelle fenêtre)Our clients' results speak for themselves
"I'd recommend Oncrawl for technical SEO challenges."
Discover all our client success stories (nouvelle fenêtre)“What I really enjoy is that you have pre-defined reports but can also export all the data raw if you like. Big bonus points for the seamless API. Even bigger bonus points for being able to cross-reference with the GSC API and even simple spreadsheets – huge value add when building custom SEO models.”


"Oncrawl: My Go-To for Technical SEO"
Explore Booksy (nouvelle fenêtre)“Oncrawl is key for analyzing large marketplaces and tracking Googlebot. Its strength: combining crawl data, bot hits, and external sources to uncover high-impact SEO actions. I also love the scraping feature and insights on emerging bots like ChatGPT.”



"Reliable, Insightful & Actionable for Large Sites"
Visit our blog for SEO insights (nouvelle fenêtre)“Oncrawl is my go-to for large sites. Reliable and clear, it visualizes data and offers powerful segmentation. The monitoring system detects issues early. Combining crawl and live log analysis, it helps make smart SEO decisions that improve performance and ROI.”

"Highly recommend Oncrawl’s suite of tools"
Learn more about Roast (nouvelle fenêtre)“Oncrawl is a fast, scalable tool that helps our team deliver technical audits on large sites. Its speed makes it easy to spot crawlability and indexation issues, and automated reports simplify client communication. Strong integrations enhance our analyses, making Oncrawl highly valuable.”


