
Scraping provides us a really quick and easy way to extract information from a website and save it in a usable format. Whether you are building shopping feeds, data visualisations or migrating pre-existing site content – scraping makes this all possible!
To give another example using scraping in SEO you might not have considered, in this article I’ll cover how to use Oncrawl to extract existing content to populate a new site where I’ll then be able to run experiments that you really don’t want to test on a live environment.
What is Scraping Content?
Content scraping is copying of content (or data) from one source on the web and using it elsewhere. Sometimes scraping can just be considered as stealing or plagiarism. In the vast majority of cases an automated bot is the one conducting the scraping although the reasons behind this can vary wildly.
Google (and Googlebot) is one of the most prolific content scrapers. It, mostly, does this to then index and analyse the scraped content to understand what is contained within it. The information gained in this way is then used to search results – i.e. what ranks when you search for something. Some would argue this is a worthwhile use of scraping.
Scraping can be pretty ‘dumb’ and just hoover up all the content, or scraping can be more specific, looking for particular pieces of information. What is key is that most scraping happens without the awareness, or even the consent, of the content owner.
Ethical Scraping
Even if you were not familiar with scraping before reading this, you may likely be wondering whether scraping is ethical or not. In some instances activities from scraping are not just unethical, but it is also illegal, too. Publishing someone else’s content (intellectual property) without consent or attribution is certainly not something you want to make a habit of doing.
There are some very good reasons to scrape content which can be done ethically – for the benefit of the content creator even!
If scraping an entire site and using the content to populate a new website sounds ethically suspect, most of the time it is. However, through web migrations, I have used this technique to pull across content which has been “forgotten” on a number of occasions. I’ll discuss a few of these scenarios again later.
For now, just be mindful that I am not endorsing you taking and publishing content without explicit permissions of the content owner.
Extracting (Scraping) Using Oncrawl
Oncrawl has a load of powerful features (and new ones come into use pretty frequently), but a lot of the tools have uses beyond the ones you might expect. Cloud-based crawlers are great at covering websites with ease, analysing & storing the information – but they can also help extract certain pieces of information, saving countless hours of manual work.
First, set up a new crawl and enable scraping. You can run a normal crawl from a home page which lets Oncrawl discover the pages OR you can upload a URL list if you know which pages you want to scrape content from.
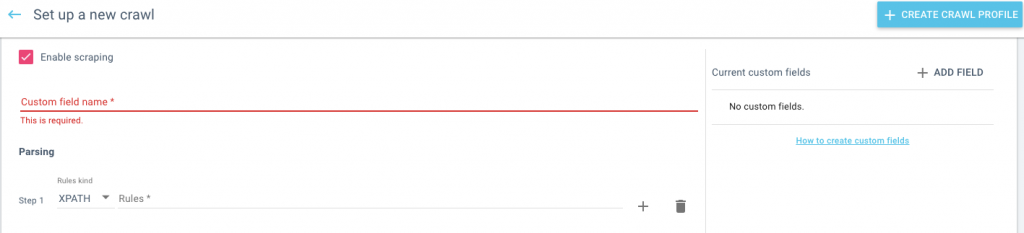
The real trick to scraping content effectively is knowing what information you want to take from the page and how to define this when you establish the crawl. You might want to have listed the different information you want to pull before you begin setting up the crawl.
For each separate element you want to scrape, you’ll need to create a field, and a scraping rule that tells the bot which information on each page that it should use to fill in the field.
In the crawl setup, define the field name – make sure this is descriptive, it’s what the field will be reported as when the process is complete. Oncrawl lets you use either REGEX or XPATH to define the different elements – you need to utilise the one you’re most familiar with.
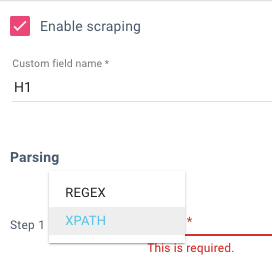
The simplest way to pull the XPATH you need is to view one of the pages with the content you want to pull, inspect the element you need – right-click and then choose “Copy XPath”.
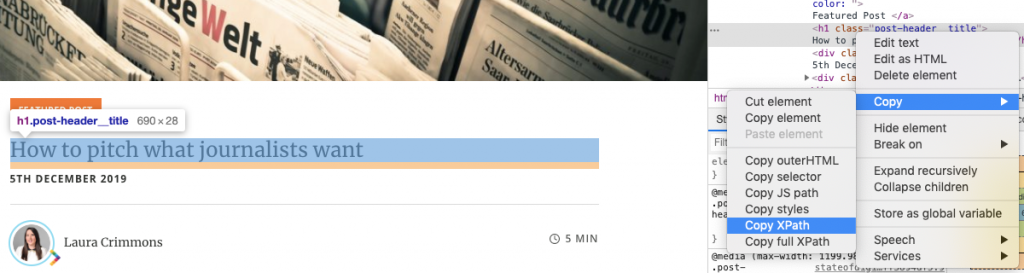
Back in Oncrawl, paste the XPATH in as Step 1, then as Step 2, define what in the XPATH you wanted. So in the example below we want the <h1> tag – which is //h1 then you want to just extract the string from within those tags – “string(*)”.
Without this second step, the output from this would be “ <h1>Some content<h1>” – for the purpose of this task, I don’t want HTML messing things up!
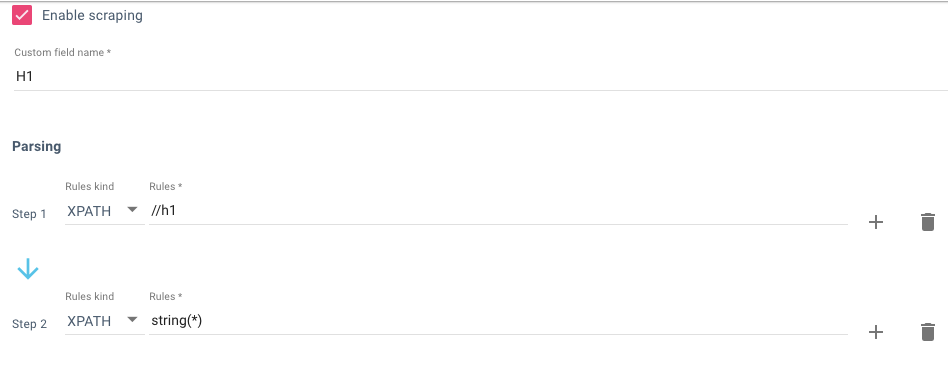
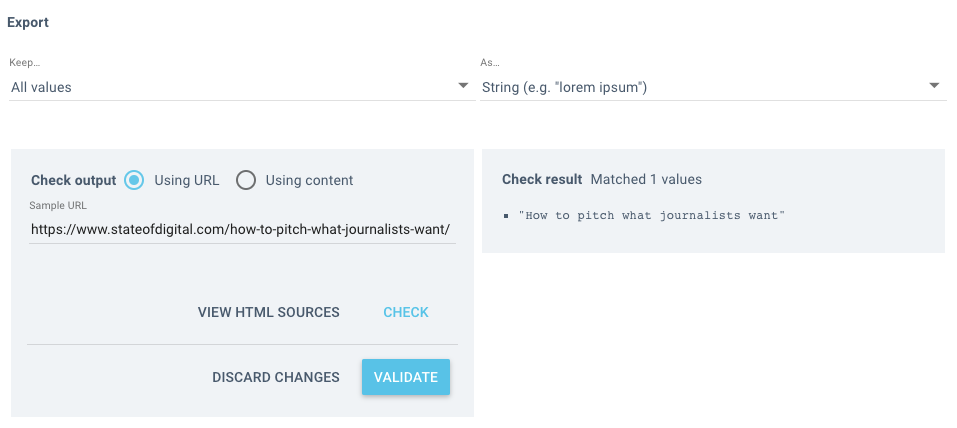
Before you start the crawl and scrape your site, you can test your rule to see what the result is. It is far better checking before rather than waiting to see it failed after the crawl has taken place.
Paste a sample page into the URL field and then click validate – you’ll see the output on the right – simple!
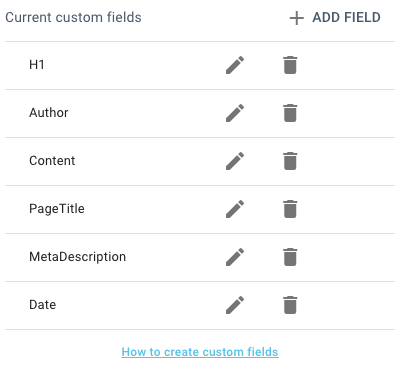
Once you have done this with the first element you wanted to scrape, you need to repeat it for the rest – creating a custom field for each one.
The whole process is a lot quicker, more efficient and kinder on the website you’re scraping if you know which pages you want Oncrawl to check. You can limit your crawl to just these pages using the URL list mode. I used an XML sitemap to build a URL list for WordPress posts in particular.
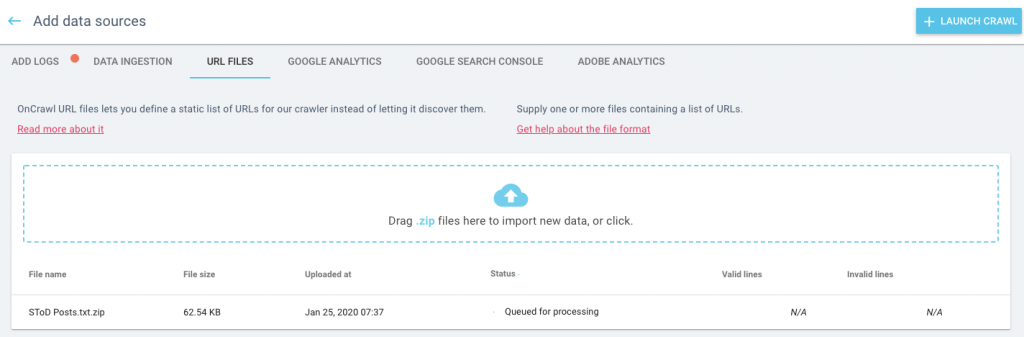
When this has been uploaded, click “launch crawl” and off you go!
Once the crawl is complete, navigate to the Data explorer and then change the fields to reflect the custom fields you defined earlier – that way you’ll see the information just for the scrape itself.
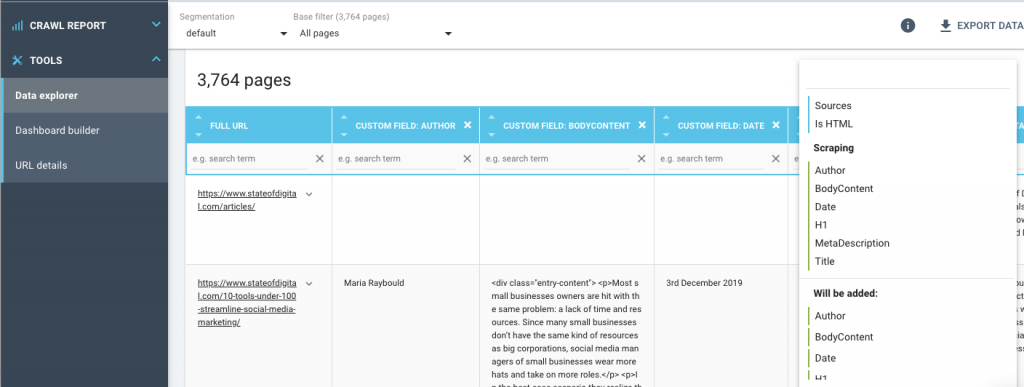
You can download this to CSV and then do what you want with it – easy!
Using Scraped Content to Populate New Website (WordPress)
The fields I selected when setting up the scrape were the ones I would need to pull this content across into a new WordPress website to populate the posts (blog). In this example I am creating a sandbox site to experiment what would happen if I change the internal linking of the website without having to do it blind on the live site.
WordPress is the example I’m using here (because it’s relatively easy), but you can do this with most CMS or put the scraped content directly into a database if you feel that way inclined.
For simplicity’s sake, I’m using the WP All Import plugin (on free licence) to do all the heavy lifting.
First, things first, you need to take your CSV export from Oncrawl & run the Import.
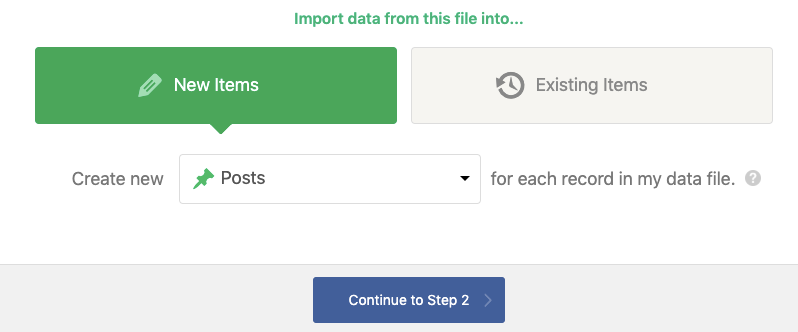
As I mentioned, I want these to be posts – but this information can populate products (with WooCommerce installed), categories, pages, etc.
This can take some time, but be patient, it’s worth it!
When the file has been parsed, you then need to map the different values from the CSV to the fields in the blog. You’re telling WordPress what the Post title is, where the content goes, the category, etc.
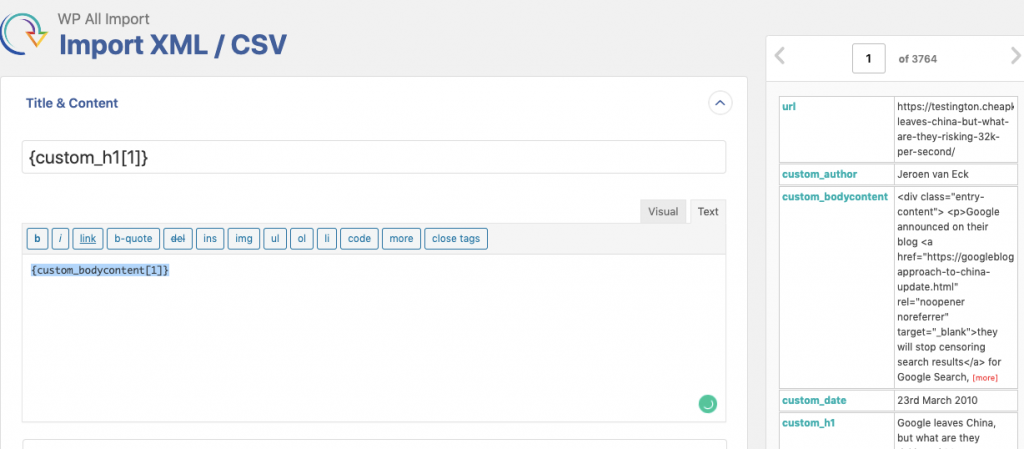
This is where you discover if you have scraped all the content you needed or whether you are missing any information!
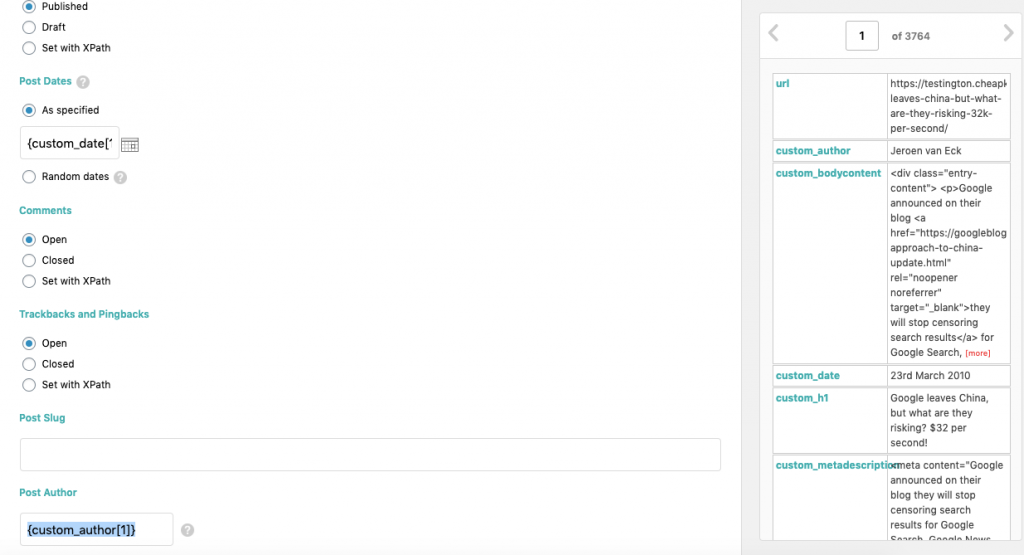
Once you’re happy that the fields have been mapped appropriately, you can review the total count of posts (rows) that’ll be imported and whether the content looks right or not.
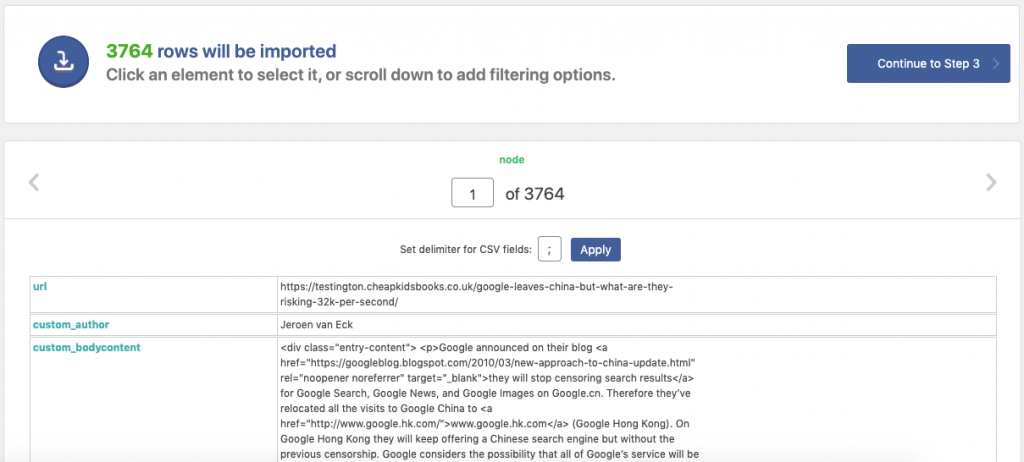
Start, the import (don’t close the window whilst it’s in progress) and you’re nearly there.
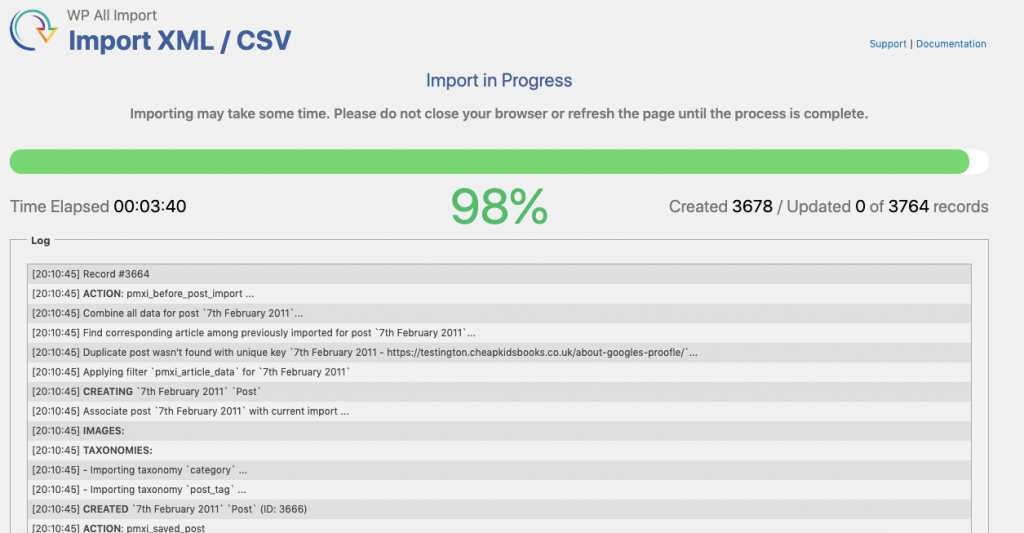
You may find there are a handful of records which didn’t import properly (not unusual when you’re scraping content). You can review any errors in the logs at the end of the process – but aside from this you’re done.
More Ethical Scraping Scenarios
Scraping content becomes an addiction when you get started to it, but it has some very real time-saving (and money-making) applications. None of these are the “perfect” fix for any of the problems, but they are neat work-arounds when you need to act quickly.
Pre Site Migration
If you are migrating to a new website, it doesn’t hurt to take an informal backup of the site content – especially if you know some content is being removed/merged as part of the process. I have lost count of the times I have seen projects with no pre-migration backups or, the backups are with a disgruntled web developer or are corrupt/unusable.
Content Migration Backups
Unfortunately SEOs don’t often get involved in a site migration process as early as they should do. One of the common scenarios this creates is that blogs either get “forgotten”, not scoped in the migration OR someone decides it’s fine to leave them behind. In my experience, about 4 in 5 of these decisions are going to detriment the new site. Offering to scrape/import the content quickly and easily (based on the above method), can quite often win the day.
Creating Product Feeds
As frustrating as this is, not every ecommerce site I’ve worked on has had the facility/budget to establish a shopping feed from within the platform itself. This is never good, but it’s possible to scrape the data from the site and pull together in line with Google’s own data templates.
Auditing for Internal Linking Opportunities
Finding internal linking opportunities on a large content site isn’t easy, but I’ve had success scraping the content from the pages and then importing into Sheets, using REGEXMATCH to locate specific mentions of key terms. You can also utilise a formula like (=SUM(LEN(F2:F2)-LEN(SUBSTITUTE(F2:F2,”<a”,””)))/LEN(“<a”)) to count the number of <a> tags within the content area too – to prioritise content with fewer contextual links.
Comment Analysis
If you have a blog with a thriving comment section and want to understand the sentiment or trends within the content itself, scraping the comments to CSV gives you the opportunity to do some specific analysis with it via Excel, Sheets or Python.
What’s Next?
When you get used to scraping, it gives you A LOT of options and opportunities you weren’t previously aware of. To get the most from it, practice working with Xpath and always test samples of extraction before embarking on any large scrapes to ensure your time is well-spent.
With a number of the examples/potential applications I’ve provided scraping the content is never the best option. Databases and APIs almost always offer a quicker, cleaner and more efficient way of getting the data you want. In my experience however, budgets, timelines and previous decisions (mistakes) will remove these as options. Do you want to be the marketer who’s a victim to these limitations, or do you find workarounds?
