
Extending search beyond textual queries and removing language barriers are recent trends shaping the future of search engines. With new AI-powered features, search engines are looking at promoting a better search experience and, at the same time, bringing new tools to help users retrieve specific information. In this article, we will address the rising topic of multimodal and multilingual search systems. We will also show the results of a demo search tool that we built at Wordlift.
The next generation of search engines
A good user experience embraces multiple interaction aspects between users and search engines. From the design of the user interface and its usability to the understanding of search intent and resolving its ambiguous queries, large search engines are preparing the next generation of search tools.
Multimodal search
One way to describe a multimodal search engine is to think about a system that is able to handle text and images in a single query. Such search engines would allow users to express their input queries through a multimodal search interface and as a result enable a more natural and intuitive search experience.
On an e-commerce website, a multimodal search engine would allow the retrieval of relevant documents from an indexed database. Relevancy is evaluated by measuring the similarity of the available products to a given query in more than one format such as text, image, audio, or video. As a result, this search engine is a multimodal system since its underlying mechanisms are able to handle different input modals, i.e. formats, at the same time.
For instance, a search query could take the form of “floral dress”. In this case, a large number of floral dresses are available on the web store. However, the search engine returns dresses that aren’t really satisfying for the user as shown in the following figure.
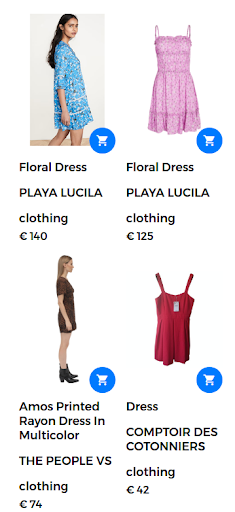
Returned results for the query “floral dress”.
To provide a good search experience and to return highly relevant results, a multimodal search engine is capable of combining a text and an image in a single query. In this case, the user provides the sample image of the desired product. When running this search as a multimodal search, the input image is a floral dress that is shown in the following image.

User-provided image for the multimodal query.
In this scenario, the first part of the query remains the same (floral dress) and the second part adds the visual aspect to the multimodal query. The returned results yield dresses that are similar to the floral dress that the user provided. In this use case, the exact same dress is available and, therefore, is the first result returned along other similar dresses.
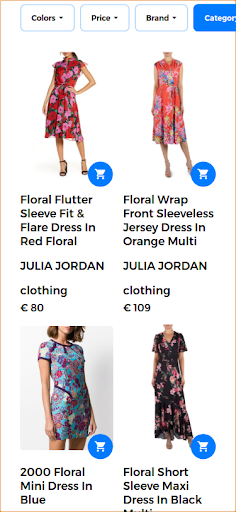
Relevant search results returned in response to the multimodal query.
MUM
Google introduced a new technology to help users with complex search tasks. This new technology, called MUM, stands for Multitask Unified Model and is capable of breaking down language barriers and interpreting information across different content formats such as web pages and pictures.
Google Lens is one of the first products to leverage the advantage of combining images and text into a single query. In a search context, MUM would make it easier for users to find patterns such as a specific floral pattern in an image that the user provides.
MUM is a new AI milestone for understanding information as presented here:
“Though we’re in the early days of exploring MUM, it’s an important milestone toward a future where Google can understand all of the different ways people naturally communicate and interpret information.”
To learn more about Google’s MUM multimodal search check this web story:

Extending search across languages
While the image is language agnostic, the search terms are language-specific. The task of designing a multilingual system boils down to building language models across a wide array of languages.
Multilingual search
One key limitation of current search systems is that they retrieve documents written, or annotated, in the language the user wrote the search query in. In general, these engines are English-only. Such monolingual search engines limit the usefulness of these systems in finding helpful information written in a different language.
On the other hand, multilingual systems accept a query in one language and retrieve documents that are indexed in other languages. In reality, a search system is multilingual if it is able to retrieve relevant documents from the database by matching the document’s content, or captions, written in one language with the text query in another language. Matching techniques range from syntaxical mechanisms to semantic search approaches.
Pairing sentences in different languages with visual concepts is a first step to promote the use of cross-lingual vision-language models. The good news is that visual concepts are interpreted almost in the same way by all humans. These systems, capable of incorporating information from more than one source and across more than one language, are called multimodal multilingual systems. However, pairing image-text isn’t always feasible for all languages at a large scale as discussed in the following section.
[Case Study] Driving growth in new markets with on-page SEO

From MUM to MURAL
There are growing efforts towards applying advanced deep learning and natural language processing techniques to search engines. Google presented a new research work that allows users to express words using images. For example, the word “valiha” refers to an instrument made of tube zither and is played by the Malagasy people. This word lacks a direct translation into most languages, but could be easily described using images.
The new system, called MURA, stands for Multimodal, Multi-task Retrieval Across Languages. It allows addressing the problem of words in one language that may not have a direct translation into a target language. With such issues many pre-trained multilingual models would fail to find semantically related words or to accurately translate words to or from an under-resourced language. In fact, MURAL can tackle many real-world issues:
- Words that convey different mental meanings in different languages: One example is the word “wedding” in English and Hindi that conveys different mental images as shown in the following image from Google blog.
- Scarcity of data for under-resourced languages on the web: 90% of the text-image pairs on the web belong to the top-10 highly-resourced languages.

Images are taken from wikipedia, credited to Psoni2402 (left) and David McCandless (right) with CC BY-SA 4.0 license.
Reducing queries’ ambiguity and providing a solution to the scarcity issue of image-text pairs for under-resourced languages is another improvement towards the next generation of search engines powered by AI.
Multilingual and multimodal search in action
In this work, we use existing tools and available language and vision models to design a multimodal multilingual system that goes beyond a single language and can handle more than one modality at a time.
First of all, to design a multilingual system it’s important to semantically connect words that come from different languages. Second, to make the system multimodal, it’s necessary to relate the representation of languages to images. As a result, this is a big step towards the longstanding objective of a multimodal search multilingual.
The context
The primary use case of this multimodal multilingual system is to return relevant images from the dataset given a query combining an image and a text at the same time. In this vein, we’ll show some examples that illustrate various multimodal and multilingual scenarios.
The backbone of this demo app is powered by Jina AI, an open-source neural search ecosystem. Neural search, powered by deep neural network information retrieval (or neural IR), is an attractive solution for building a multimodal system. In this demo, we use the MPNet Transformer architecture from Hugging Face, multilingual-mpnet-base-v2, to process textual descriptions and captions. As for the visual part we use MobileNetV2.
In what follows, we present a series of tests to show the power of multilingual and multimodal search engines. Before presenting the results of our demo tool, here is a list of key elements that describe these tests:
- The database consists of 1k images that depict people playing music. These images are taken from the public dataset Flickr30K.
- Every image has a caption that is written in English.
Step 1: Starting with a textual query in English
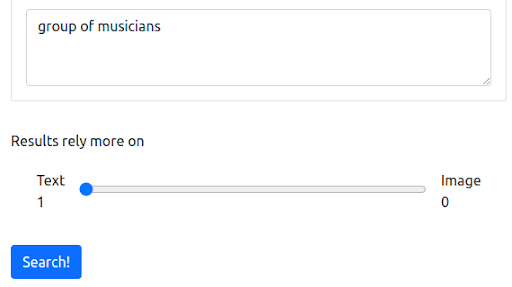
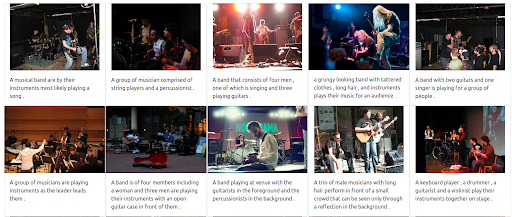
First, we start with a textual query that reflects the current way in which most search engines operate. The query is “group of musicians”.
The query
The results
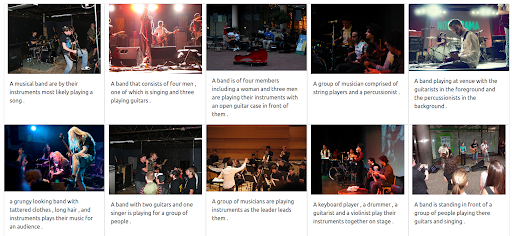
Our Jina-based demo search engine returns images of musicians that are semantically related to the input query. However, this may not be the type of musicians that we want.
Step 2: Adding multimodality
Let’s now add some multimodality by issuing a query that combines both of the previous textual query and an image. The image represents a more accurate representation of the musicians that we’re looking for.
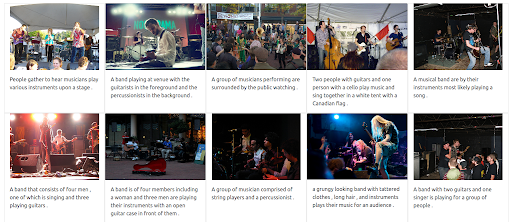
First of all, the UI needs to support issuing such types of queries. Then, we have to assign a weight to balance the importance of each modality when retrieving the results. In this case, both the text and the image have an equal weight (0.5). As we can see below, the new search results include a number of images that are visually similar to the input image query.
The query
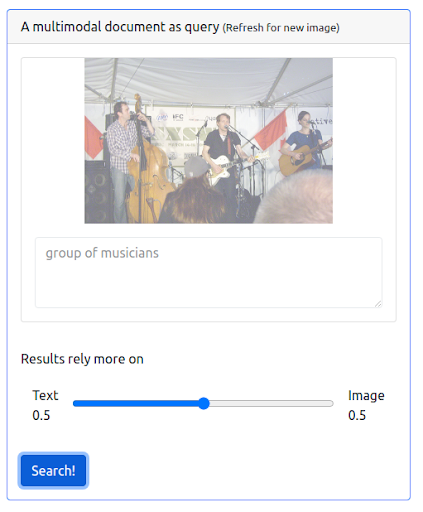
The results
Step 3: Assigning a maximum weight to the image
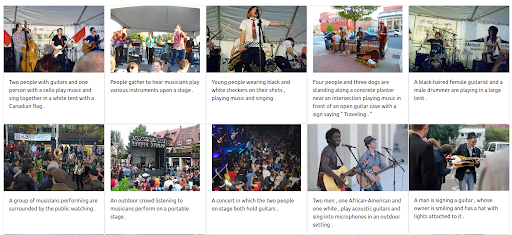
It’s also possible to give a maximum weight to the image. Doing so would exclude the input text from the query. In this case, more images that are visually similar to the input image are returned and ranked in the first positions. One thing to keep in mind is that the results are limited to the images available in the dataset.
The query
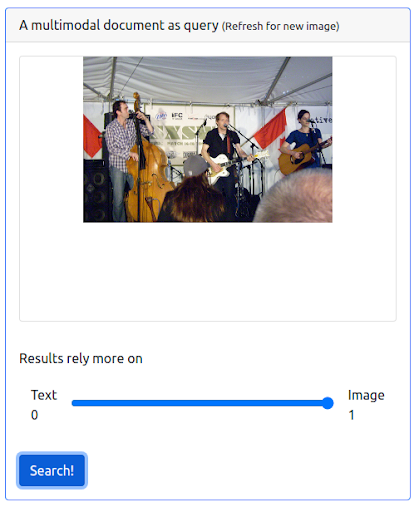
The results
Step 4: Testing the multilingual search
Now let’s try to issue the same query but using different languages. The weight of the text is maximized in order to illustrate the full power of this multilingual system. Please recall that the captions of the images are in English only. The search is repeated to cover the following languages:
- French: Groupe de musiciens
- Italian: Gruppo di musicisti
- German: Gruppe von Musikern
Regardless of the language of the input query the returned results are relevant and are consistent across the three languages. The results are shown below.
The results for the query in French

The results for the query in Italian

The results for the query in German
The multimodal multilingual future of search
In the coming years, artificial intelligence will increasingly transform search and unlock entirely new ways for people to express their queries and explore information. As Google has already announced, understanding information with MUM represents an AI milestone. More AI-powered systems in the future would include features and improvements that range from providing a better search experience to answering sophisticated questions and from breaking down language barriers to combining different modes of search into a single query.
