
Our Crawl over Crawl feature allows you to compare two different crawls and displays crawl evolutions.
In 2016, it built on our previous release about ‘Trends’ that gave you the opportunity to spot global trends between different crawls. Now you can access complete views of your SEO improvements and highlight differences between crawls on a given theme. The Crawl over Crawl updated included new types of graphs to read your data.
In 2019, the Crawl over Crawl feature has improved. You can now examine:
- Two versions of a website that contain the same or similar pages, such as production vs staging websites, or mobile vs desktop versions.
- The same website at two different points in time, such as before and after a change on the site.
Comparing two versions of a website
To compare two websites, Oncrawl looks at the Start URL you provide for two different crawls in order to determine the differences in the web addresses of the different sites. It assumes that these two versions of the website contain the same (or nearly the same) content. This means that a majority of the slugs of the URLs within the two domains, folders or subdomains that you are comparing need to be the same.
Here are some examples of sites that can be compared:
| Use Case | Crawl 1 – Start URL | Crawl 2 – Start URL |
|---|---|---|
| Production vs Staging sites | https://www.example.com | http://staging.example.com/site/ |
| Desktop vs Mobile sites | https://www.example.com | https://m.example.com |
| Regional versions | https://www.example.com/en-us/ | https://www.example.com/en-ca/ |
| Regional versions | https://www.example.com | https://www.example.co.uk |
For complex differences between start URLs, the automatic matching may not be sufficient. If this is the case, you’ll see an error when setting up your crawl that asks you to contact Oncrawl through the chat. We’re able to override the automatic matching in order to adapt to your specific case.
Comparing one website at two different points in time
To compare one websites at two different points in time, such as before and after an improvement or a major change on the website, you will need to provide:
- The same Start URLs
- The same breadth of crawl (the same subdomain exploration rules)
How to set up a Crawl over Crawl
You can run a Crawl over Crawl between two existing crawls, or request the comparison with a previous crawl when creating a new one. More information on creating Crawl over Crawls can be found in Oncrawl’s Knowledge Base.
How to read a Crawl over Crawl sunburst
You read a sunburst like a traditional pie. These graphics are very useful to follow the evolution of a website, crawl after crawl or to check differences between two versions of a website (between a live version and during a restructuration for instance).
This multi-level pie chart lets you compare two crawls depending on a given theme:
- The first level and inner circle : shows the pages belonging to the first crawl (the older crawl).
- The second level and outside circle : shows the pages of the second crawl (the newer one) that correspond to each segment of the inner circle.
So you can easily find, for example, indexable pages in the first crawl that are no longer in the second one and vice versa.
In this chart, the inner circle shows the repartition of pages from the first crawl point of view (the older one). You can see that there are indexable pages, no indexable pages and pages that were not in the first crawl but appear in the second (the grey section).
Then, for each section of the inner circle, you can see the pages’ repartition of a given section in the second crawl. The inner grey section means that those pages did not exist in the first crawl but appear in the second one (the outside green and red section belonging to the inner grey one).
Grey sections mean pages are whether new or not existing in the structure depending on which cercle they belong.
By clicking on the legend, you can decide which data you want to display or focus on. Crawl 2 offers a more global view.
Let’s have a look at the inner circle.
The distribution of pages in the first crawl according to their indexability
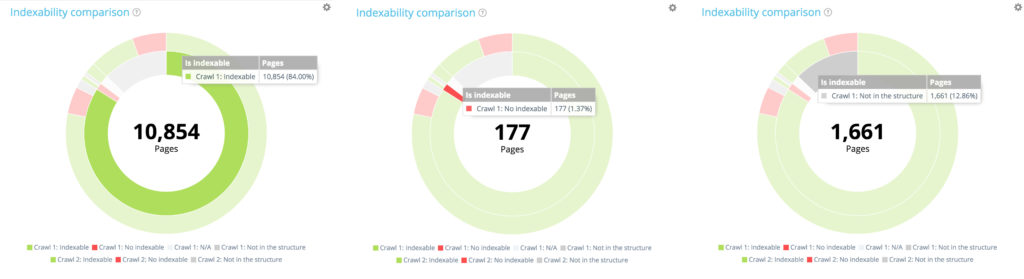 The first crawl contains 10 854 indexable pages and 177 no indexable pages. 1 661 pages have only been found in the second crawl.
The first crawl contains 10 854 indexable pages and 177 no indexable pages. 1 661 pages have only been found in the second crawl.
Now have a look at the outside circle. For each segment of the first circle, we find the distribution of these pages in the second crawl.
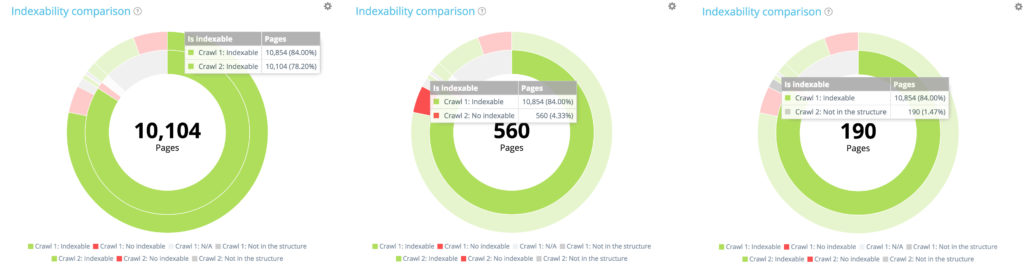
Among the 10 854 indexable pages in the first crawl, only 10 104 are still indexable in the second one. 560 are now non indexable and 190 pages were no longer part of the crawlable website at the time of the second crawl.
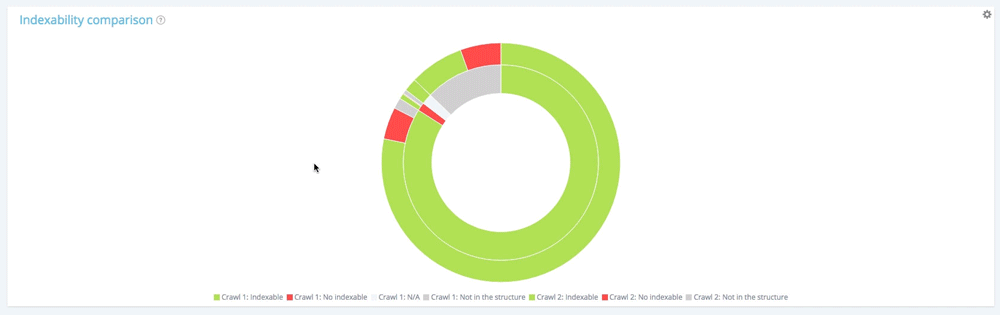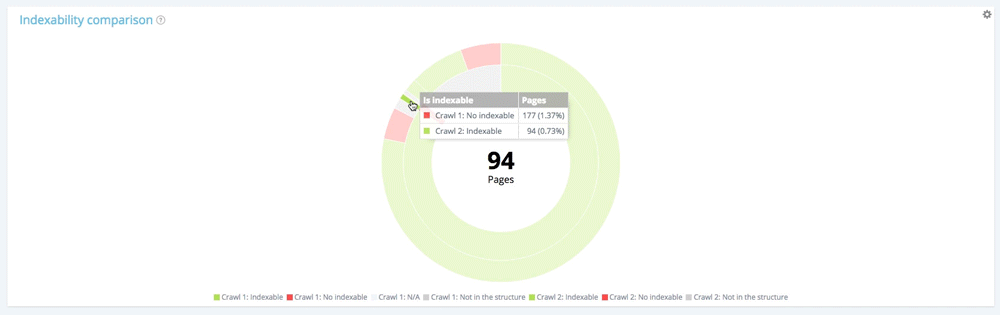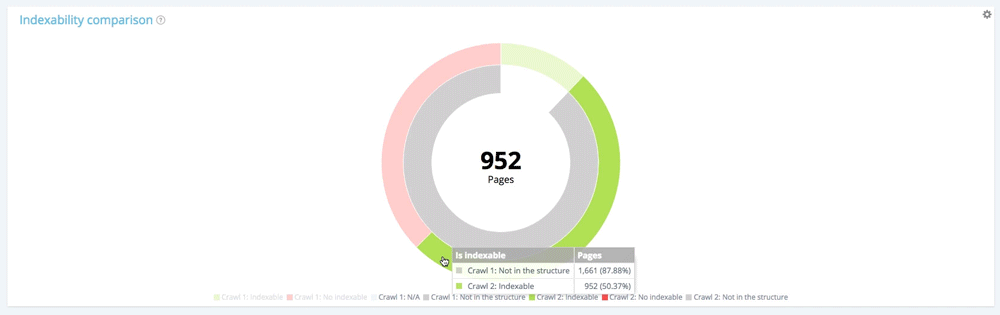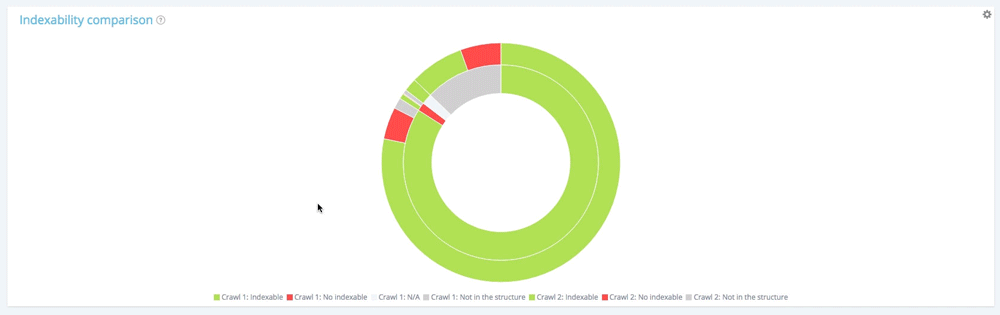
Let’s focus on a small section: non-indexable pages in the first crawl
By using the legend to hide indexable pages and pages not in the website structure at the time of the first crawl, we can concentrate only on the non-indexable pages in the first crawl.

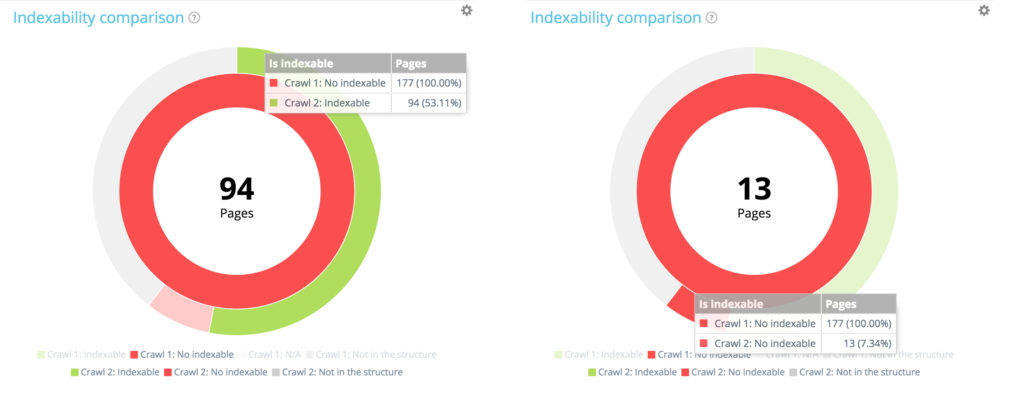 Among the 177 non indexable pages from the first crawl, 94 are now indexable in the second one and 13 remain indexable.
Among the 177 non indexable pages from the first crawl, 94 are now indexable in the second one and 13 remain indexable.

Of the 177 non indexable pages in the first crawl, 70 are no longer present in the second crawl. 94 + 13 + 70 = 177. We find the expected breakdown of the 177 non-indexable pages from the first crawl.
Focus on new pages: pages only found in the second crawl
Now let’s use the legend to hide both indexable and non-indexable pages from the first crawl, and show only pages that were not part of the website structure during this crawl. This allows you to see the status of new pages in terms of indexation.
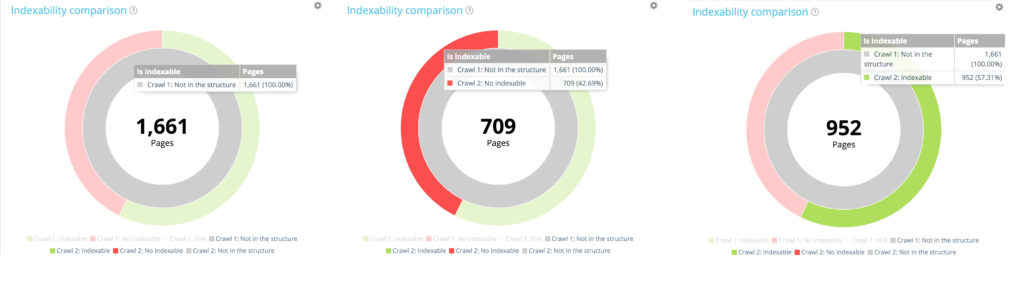
All new pages: 1 661 pages.
Of the 1 661 newly created pages, 709 are not indexable.
Of the 1661 newly created pages, 952 are indexable.
Summary: all pages from second crawl
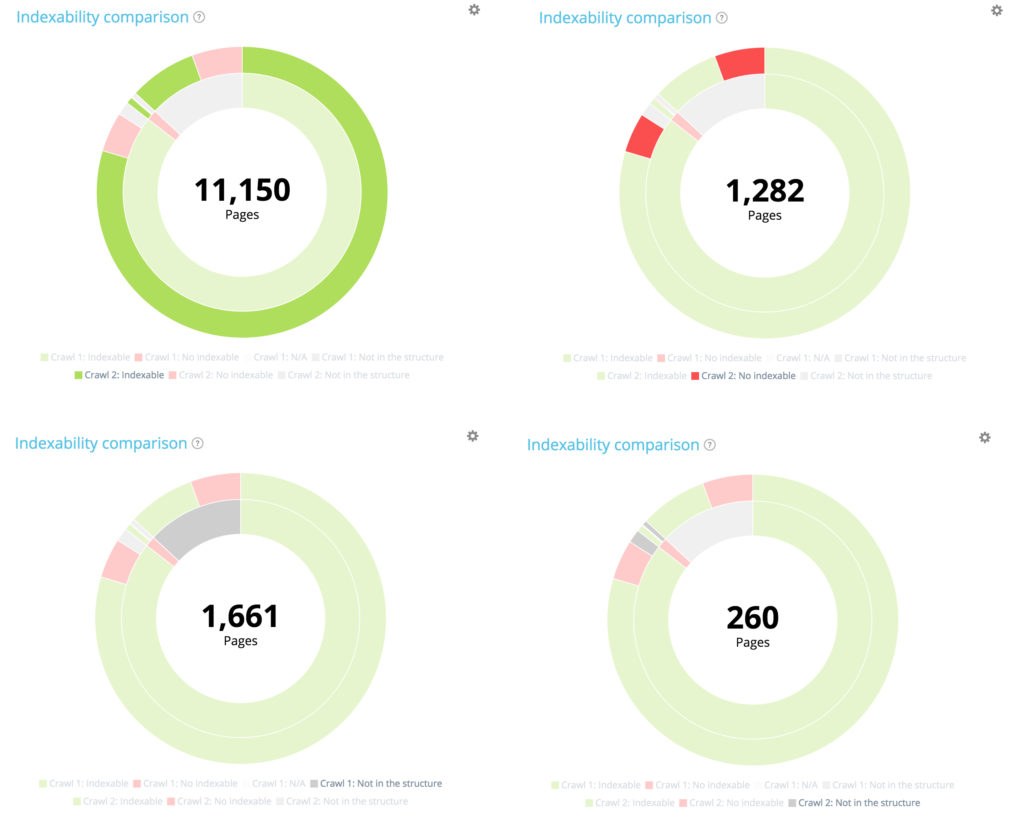 10 104 pages were indexable in the first crawl. 11 150 are now indexable in the second one. 177 pages were non indexable in the first crawl but 1 282 are now non indexable in the second one.
10 104 pages were indexable in the first crawl. 11 150 are now indexable in the second one. 177 pages were non indexable in the first crawl but 1 282 are now non indexable in the second one.
1661 pages have been created, and 260 pages have been deleted from the structure.
Crawl over Crawl: available data
This new feature is divided by business expertises and between the following tabs:
- Structure
- Internal linking
- Content
- Status Codes
- Performance
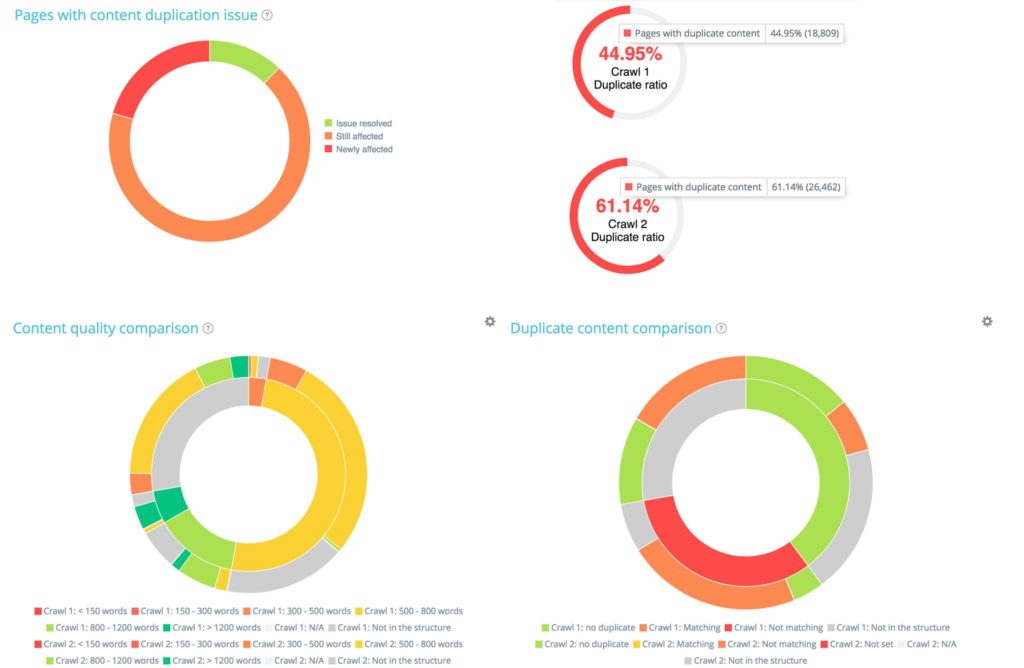
For instance, in the ‘Content’ section, you will find a strong focus on the differences in duplication between the two crawls:
Also, you can analyze how your page depth differs between the two crawls. In the graph below, you can see depth differences:

For example, if we look at depth 5, we can see pages that are gone to shallower or deeper depth or pages that come from shallower or deeper depth between crawl 1 and 2. Here, 264 pages that were in crawl 1 and in depth 5 have gone to a shallower depth (depth 4, 3 or 2).
This is just an overview of what is available. Our Data Explorer also lets you dig into more than 700 metrics for crawl comparisons.
