A Semantic Network is connected to the concept of a knowledge base that can represent real-world information for things that have relational connections. A knowledge base can have thousands of relation types with billions of entities, and trillions of facts. A semantic network can be created from any real-world existence with mutual features such as weight, size, type, smell, or color. The relationship between Semantic Networks and the Semantic Web is created by semantic search engines and optimization.
Semantic Networks are used in Semantic Parsing, Word-sense Disambiguation, WordNet Creation, Graph Theory, Natural Language Processing, Understanding, and Generation. The perspective of a Semantic Network can be used within Semantic Search Engine Optimization by providing a semantic content network.
In this SEO Case Study, two different websites with two different methods with the same perspective will be explained based on the Query, Document, Intent templates and the entity-attribute pairs behind them.
Using an understanding of how search engines represent knowledge and how they expand their representation of knowledge, I am able to leverage that to produce incredible ranking results. Once you understand the basic concepts, I’ll explain how I applied them to the two different websites, and then I’ll detail the methods I used.
How can Semantic Networks help your Website’s Ranking?
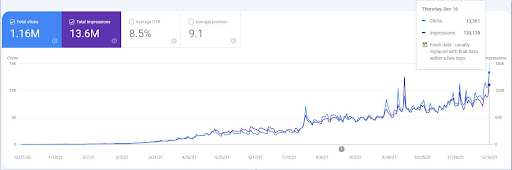
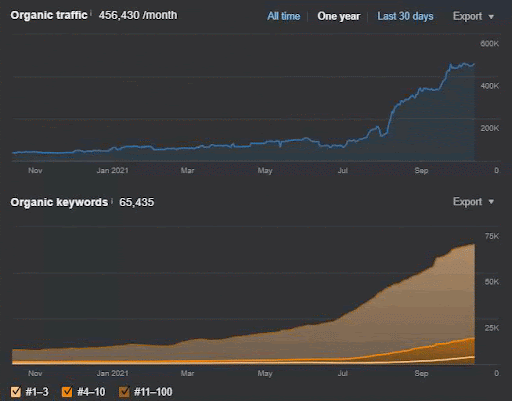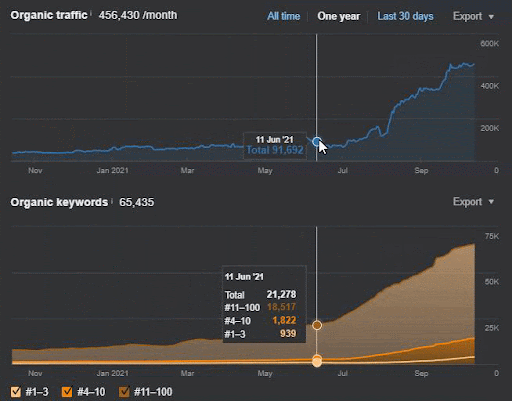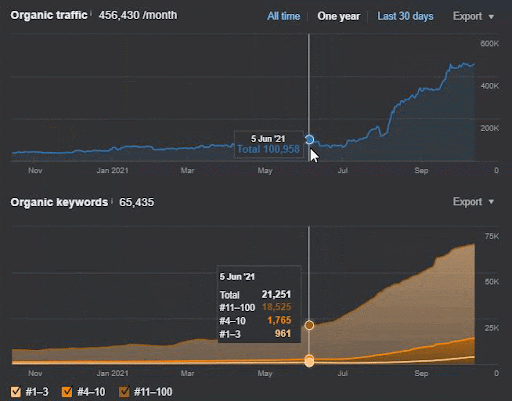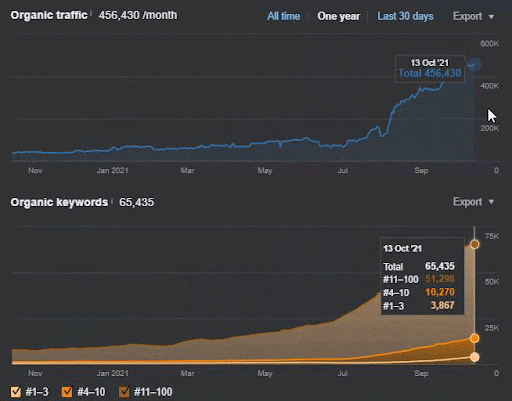
Below, you will find the overall raw results for Project I.
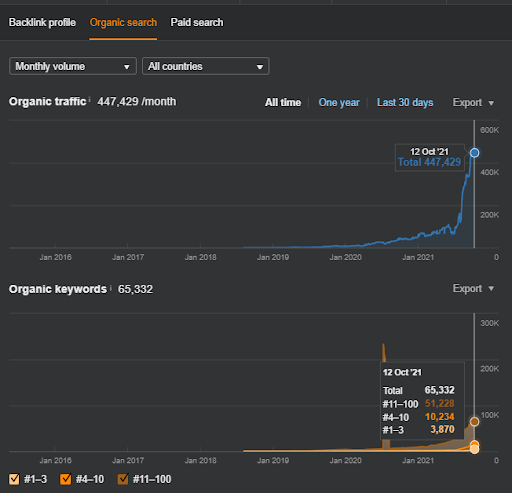
Results for the Project One which is IstanbulBogaziciEnstitu.com. To prove that the “Semantic Networks” can be used for SEO with query and document templates, I will demonstrate two different content networks from Project One. Project One will have much better results in the near future thanks to Semantic Content Network Two. The client will be responsible for the roll-out of this second network, but I will explain its logic as well.
17 days later, here is the progress made on Project I:
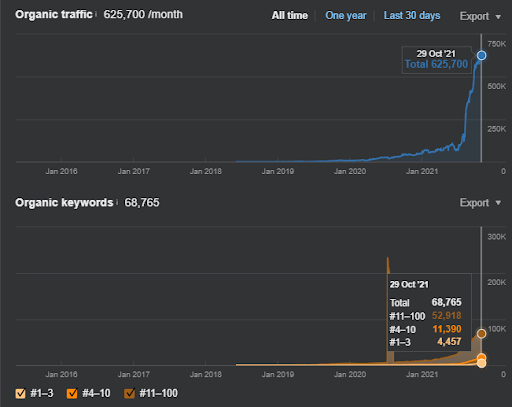
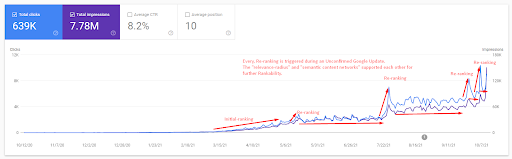
17 days later, the re-ranking process of Semantic Content Network is more clear.
Semantic Content Network concepts help us to understand the value of query, search intent, behavior, and document templates for entities from the same type. In this Semantic Network-focused SEO Case Study, the previous Topical Authority and Semantic SEO Case Study will be deepened via the two new websites that use semantically created content networks around the same entity types.
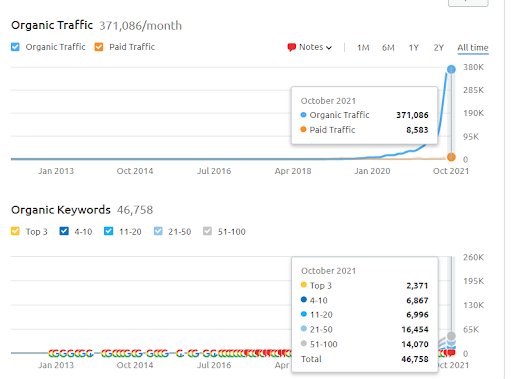
This is the SEMRush graphic of the First Project. I also must mention that this website has lost the June Broad Core Algorithm Update, if it wouldn’t lose its “Rankability”, the results would be better. For the next Broad Core Algorithm Update, with a better topical authority, coverage, and historical data, it can recover “Rankability” easily.
The name of the Second Project is Vizem.net. Unlike Project One, you can see that Vizem.net has a slower but steady increase. It’s because they use the Semantic Content Networks with slightly different perspectives. Below, you can see the Ahrefs results of the Second Project.
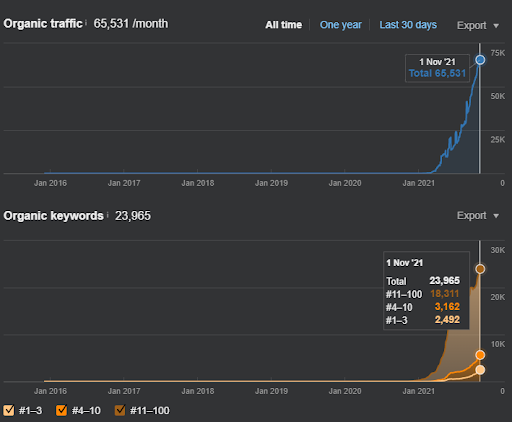
The results of the Second Project represents a “Slow Re-ranking Process” by improving the Topical Coverage and Authority gradually. The terms “Re-ranking” and “Initial Ranking” will be explained after the concepts related to the Semantic Content Networks. If you realize the “stability” within the graphics, it is because I have stopped publishing new content in the source. And, it affects the Re-ranking Process as you realize from the counts of the Top 3 Query Counts. The “Momentum”, and “Re-ranking” relations can be found after the explanations of the fundamental concepts.
Below, you can find Vizem.net’s SEMRush results.
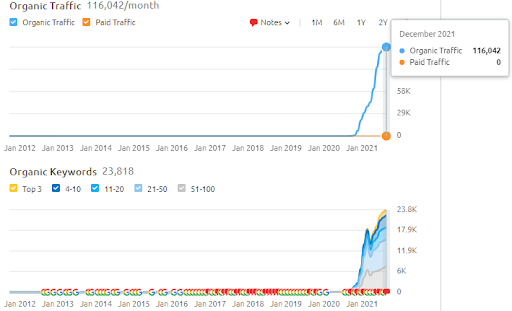
The actual traffic of this website is 3x more of the number that is stated within the SEMRush. You can realize the same “stability”, and the “momentum” concepts within these graphs as well.
While writing the Topical Authority SEO Case Study, I thanked Bill Slawski for educating my perspective. I repeat it for the Semantic Content Network SEO Case Study too. To understand the “Re-rank” and “Initial-rank” concepts, “Ways Search Engines May Rerank Search Results” should be read.
On 18th March 2021, Oncrawl, RankSense and Holistic SEO & Digital published a Python SEO and Data Science Webinar. In the webinar, the SERP has been recorded for animating the result differences. It can be seen that the search engine changes the rankings of certain sources with others with a similar frequency.
Before I continue further, I know that this is a long article. But, actually this is a brief explanation of a highly complex SEO methodology. Semantic Content Networks require too much thinking while designing them, and months of education for clients, authors, and along with the onboarding. Thus, in this article, I want to focus on the definitions of the concepts with the best possible executable brief suggestions and important Google, and other search engines’ patents, research papers along with their own concepts. In the long version (basically, a book), I have focused on “initial ranking” and “re-ranking” of semantic content networks.
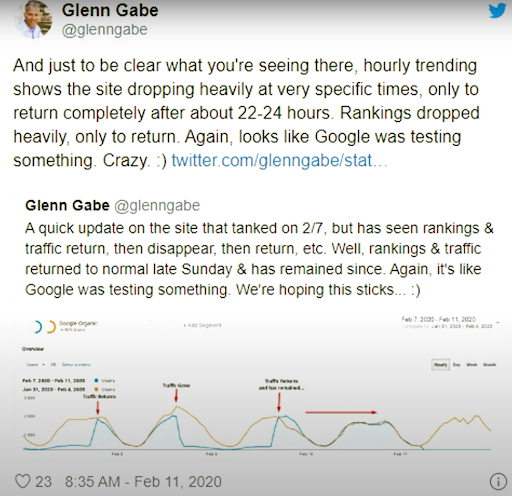
From 11 February 2020, Glenn Gabe has a good example for the Re-ranking and testing methodology of the Search Engines’ visually.
If you want to learn more, read the “Importance of Initial Ranking and Re-ranking for SEO”.
To dive deep into the real-world data for the SEO Case Study, the concepts for understanding the Semantic Content Network should be processed with a Search Engine Understanding-Communication perspective.
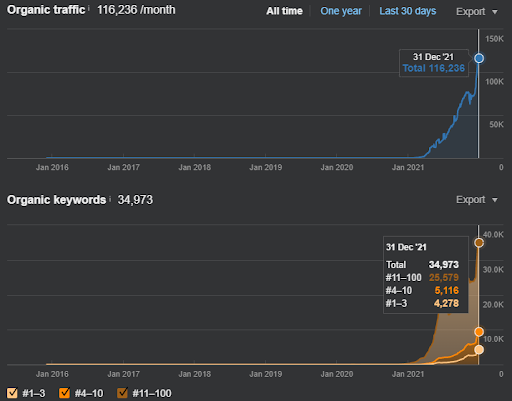
As a re-ranking example of the Vizem.net, the updated situation can be seen above. In the future sections of the SEO Case Study, there will be more explanations for the Re-ranking Algorithms of Google for SEO.
What is a Semantic Network?
A Semantic network can be used for connecting and analyzing the internet of things. It can be beneficial for recognizing the potential buyers in the technology market, or just co-word analysis for keyword network creations and clustering. A semantic network can be used for supporting the navigation and revealing the structure of relations, or relative importance of a thing to another thing. Semantic Network has the components below:
- Lexical Semantics: Understanding which word and concept are linked to which other ones, with what differences.
- Structural Component: Understanding which node is connected to which edge with what information.
- Semantic Component: Definition of the facts.
- Procedural Part: Helps to create further connections between components.
Since semantic networks are multi-purpose, NLP algorithms can also be used for very diverse purposes, such as to help with identifying complicated health problems. The same semantic network structure can be implemented in multiple other areas as long as these other areas have a semantic relation between one other.
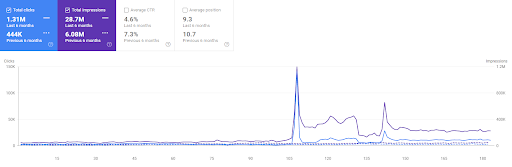
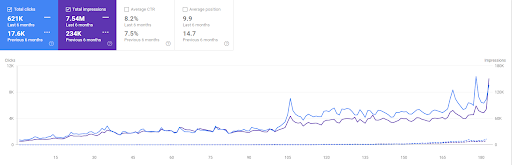
The last 6 months comparison of the First Project.
What is a knowledge base?
A knowledge base is an information library with classification in a machine-readable form. A knowledge base can be used as an encyclopedia that can be narrowed and deepened based on the query. A knowledge base can be formed based on propositions, fact extraction, and information extraction. The relation between a semantic network and a knowledge base is that everything that is in the semantic network will be placed into the knowledge base while extracting the facts.
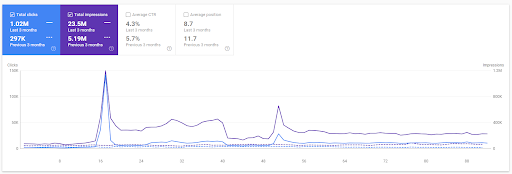
The last 3 months comparison of the First Project
What is a Semantic Content Network?
Semantic Content Network represents a content network that has been prepared based on the semantic network components and understanding. A semantic content network can include multiple attributes from an entity or entities from the same group in order to provide a knowledge base with more detail.
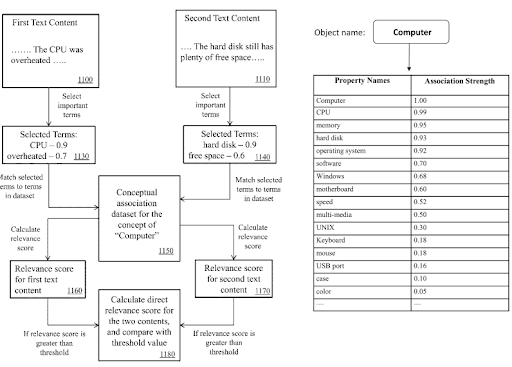
Within a Semantic Content Network, the Knowledge Domain Terms, and Triples can be used to signal a document’s main purpose, and possible neighborhood content pieces.
A search engine can compare its own knowledge base to the knowledge base that can be generated from a website’s content. If the website has a high level of accuracy and comprehensiveness for different contextual layers, the search engine can improve its own knowledge base from the website’s content. If a search engine improves and expands its own knowledge base from another source on the open web, it is a signal of a high-level Knowledge-based Trust.
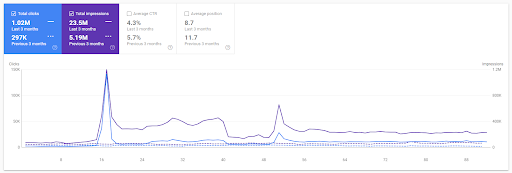
Year over Year Comparison for the Last 3 Months based on the First Project.
What is Knowledge Based-Trust?
Knowledge-based Trust focuses on open web-based on the “accuracy of information”, not “PageRank”. It is an algorithm similar to the RankMerge. Knowledge-based Trust involves triplets, fact extraction, accuracy check, and text understanding by removing the text ambiguity. Knowledge based-trust can be acquired by providing semantic content networks that have the strongly connected components within the article, based on different but relevant contextual layers.
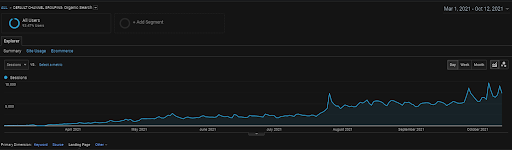
The Organic Session of the Vizem.net from GA for the Last 6 Months.
Below, you will see an example of a Knowledge-based Trust presentation from Luna Dong. It shows how a search engine can focus on the “internal ranking factors” instead of the exogenous ranking factors. It explains that a high PageRank can’t represent high quality and accuracy for the content by itself. So, having a KBT (Knowledge-based Trust) is important.
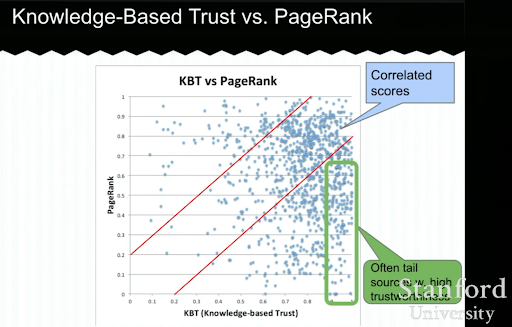
Many thanks to Arnout Hellemans who shared this educational lecture with me during a private SEO chat. If you want to learn more about Knowledge-based Trust: Stanford Seminar – Knowledge Vault and Knowlege-Based Trust
What is Contextual Coverage?
Contextual Coverage and Topical Coverage are not the same as Knowledge Domain and Contextual Domain are not the same. A contextual coverage represents the processing angles of a concept. A concept can be processed based on its mutual points to the other things. Such as if the entity is a country, its stance on the environmental crisis can be processed. If other countries are processed from the same angle, it means that we are covering a contextual domain.

Google Search Engine builds its research papers and patents over time. The right quote from the section above is an attribute to the “context vectors” while the left section is an attribute to the “phrase taxonomy”. The interesting thing is that, even the example is the same, which is “digital camera”.
The deepened details and sub-parts of these combinations represent the contextual layers within a contextual domain. Every entity whether it is named, or not, has many contextual domains. Thus, Google extracts more contextual domains and users search longer queries every year. When the Natural Language Processing and the Natural Language Understanding are developed, the queries and the documents expand together in terms of detail, and context.
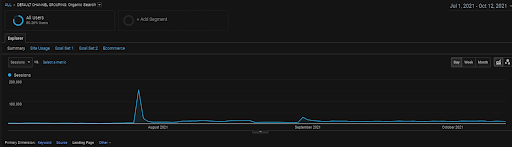
The GA Organic Sessions graphic for the last 4 months of the BoğaziciEnstitu Project. Due to the “Historical Data Gaining Stage” of the project, the increased details are not clear to be seen as linear.
A contextual coverage can be understood by the “context qualifiers”. A context qualifier can be an adjective, adverbial or any other preposition such as phrases beginning with “for, in, at, during, while”. The entity-related questions below are not the same in terms of the contextual domain:
- What are the most useful fruits for children with insomnia?
- What are the most useful fruits for children with anxiety?
The entity-related questions below are not the same in terms of the contextual layer:
- What are the most useful fruits for children with severe insomnia over 6 years old?
- What are the most useful fruits for children with low-level anxiety under 6 years old?
The entity-related questions below are not the same in terms of knowledge domains:
- What are the most useful books for children with severe insomnia over 6 years old?
- What are the most useful games for children with low-level anxiety under 6 years old?
But all of these questions can be in the same Semantic Content Network because they are all about the same “concept”, and “interest area” with similar search activity, and search-related real-world activity.
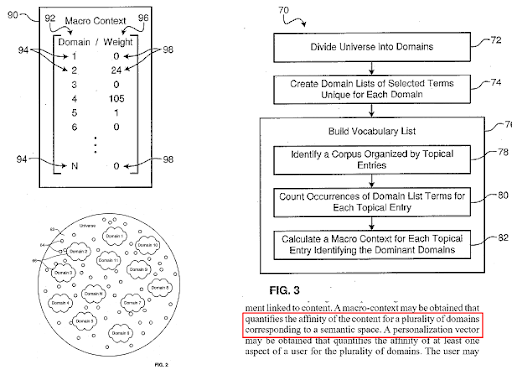
A search engine divides the web into different knowledge domains, and calculates the macro and micro context scores for a source, a web page, and a web page section at the same time.
I know that I have lots of new concepts for you, and since this is the brief version of this article, I won’t be able to talk about everything here, but in a future Semantic SEO Course, I will process these things such as the difference between “search activity”, and “search-related real-world activity”.
Let’s continue a little bit to the more concrete things.
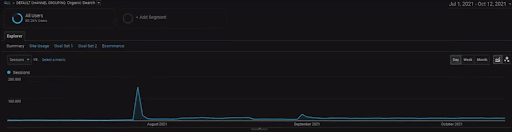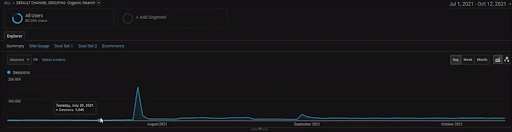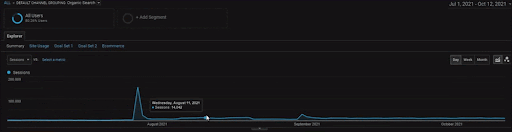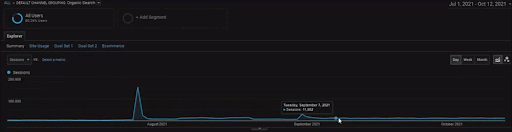
To show the details of the BogaziciEnstitu Project, you can check the interactive image version. The testing and re-ranking process of search engines are clearer on this project after the historical data source event.
How is MuM Related to the Semantic Content Networks?
Multitask Learning with a Unified Transformer or the Multitask Unified Model trains language models to evaluate visual inputs, as well as text. It is able to generate text along with understanding. Additionally, MuM is language-agnostic, in other words, Semantic SEO depends on language skill, but it is not restricted to a language. Since entities do not have a language and meaning is universal, MuM leverages the information from multiple languages and multiple contexts into a single knowledge base.
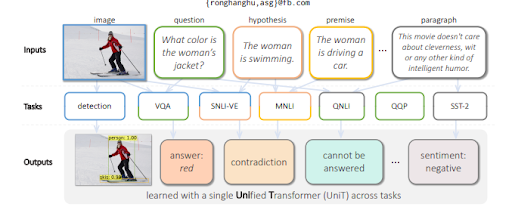
To answer the questions from a visual, MuM generates questions based on the detected objects within an image. In the near future, audio- and video-related questions will be able to be generated as well.
MuM uses different domains for object detection and natural language understanding with a transformer encoder-decoder structure. Every input comes from a different area of the open web while all of them are evaluated from a single shared decoder. Below, you will be able to see a further example from the research paper.
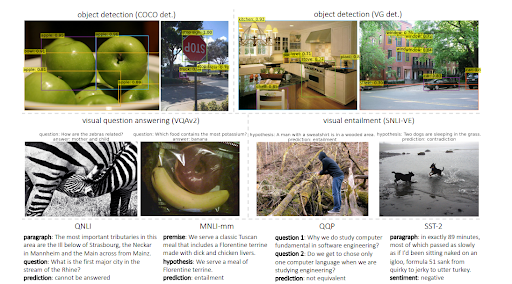
As a note, MuM can be 1000 times stronger than BERT, but BERT is still used within the Text Encoder of MuM. The main advantage of MuM is that it can be used for visuals, and audio directly, which is why it can be called a “multitask” model. The second advantage is that it removes all of the language barriers directly. The third advantage is that it is able to connect everything to another thing without the need for extra intermediaries. The fourth advantage is that MuM can generate text as well, unlike BERT.
The connection between MuM, the Knowledge Base, Semantic Networks, and Contextual Coverage is that the search engine is able to find much more contextual domain via context qualifiers and their combinations with possible knowledge domains. Thus, a well-structured Semantic Content Network that is shaped with a proper Topical Map and Source Context can improve the Knowledge base Trust, along with the Topical Authority.
What is the Source’s Context?
The Source’s Context represents two things. The central search internet of the source, and central search activity that can be done with the related search activity. For an e-commerce website, the source context is purchasing a specific product or a specific type of product. If it is a travel website, the source’s context is going somewhere from another place for different types of foods, landscapes, or just business. Based on the Source’s Context, the Semantic Content Network design, and the Topical Map will need to be configured further. This requires choosing the central sections within the topical map, and supplemental sections within the topical map.
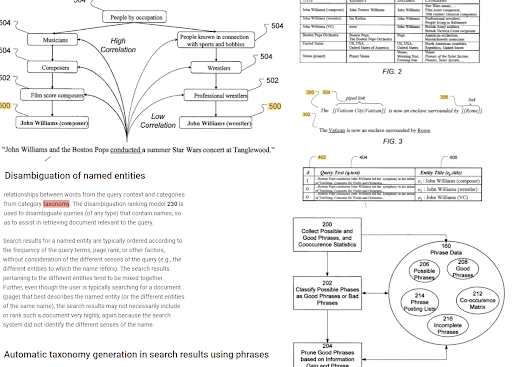
The phrase-based indexing, and the entity-oriented search understanding are connected to each other based on the semantics. Above, the “Named Entity Disambiguation” and the “Automatic taxonomy generation in search results using phrases” can be seen together for determining the “context”. The good phrases, and the unique but correlated information for a topic will help for better initial and re-ranking.
Again, some of these concepts, the “topical map configuration”, “semantic content network design” have not been defined yet, and this is not the right place for it. But, the related search activity has been explained along with the canonical search intent, and representative phrases for these canonical search intents.
Background of the Semantic Network Focused SEO Case Study
Based on the concepts above, I used Semantic Networks to create an SEO Case Study. We’ll look at the two website projects I mentioned at the beginning of this article and examine the results, and how I implemented Semantic Networks to produce them.
To give you an idea of how powerful these networks can be, the SEO-related results for the Semantic Network-focused SEO Case Study are listed below.
- Semantic Network Understanding is a necessity to create a proper Topical Map.
- For both of the projects, Technical SEO is not used in order to isolate the effects of semantic SEO.
- Page Speed Optimization is not used, for the same reason.
- Design and WUX (Website User Experience) Optimization are not used.
- Backlinks (External References and PageRank flow) are not used.
- Both of the brands do not have historical data. Vizem.net is completely new, BoğaziçiEnstitusu has an older history but it was lower than the actual company.
- OnPage SEO or other verticals of the SEO is not used.
- Both of the brands have a better server than the previous Topical Authority Case Study example.
This Semantic Network-focused SEO Case Study will help the people who want to improve their Semantic SEO perspective with two different methodologies and concepts that focus on two different websites.
Project Two: Vizem.net focuses on Visa Application Process. Before writing, publishing, or even launching these projects, I have shown both of these websites many times to my other clients, or partners. And, Vizem.net has started its “Topical Authority” journey recently.
SEO based on Semantic Networks Case Study has been written in two different versions. If you want to read all of the related patents, research papers, and deeply detailed examinations, interpretations from the search engine point of view while understanding search engines’ decision trees further, you can read the Importance of Initial-ranking and Re-ranking SEO Case Study article which is longer than 30.000 words. If you do not have enough theoretical knowledge for SEO and historical background, you can continue to read the executive summary.
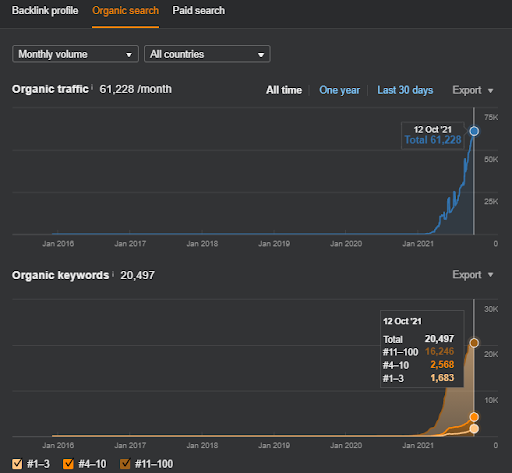
Below, you can see the Second Project (Vizem.net) graphic from SEMRush.
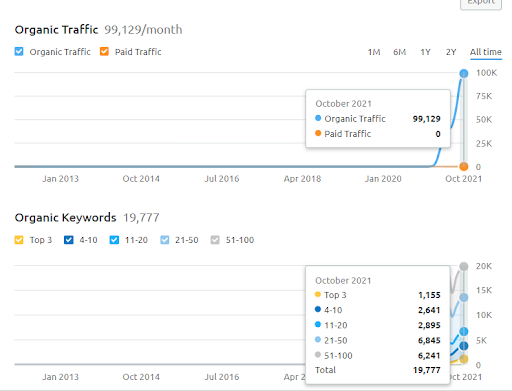
The SEMRush graphic of the Second Website. Vizem.net is an entirely new source that targets industries with a high level of rooted competitors such as “Visa Application”. Especially, due to the latest events in Turkey, the industry’s competition level is increasing. Thus, using the Semantic Network perspective for creating a Content Network is useful.
First Project: İstanbul Boğaziçi Enstitüsü: 600% Organic Click Increase in 3 Months – Leveraged Historical data and Initial Ranking
İstanbulBoğaziçi Enstitusu is one of the hardest SEO Case Studies that I have performed, not because of the Search Engines, but because of the people and my health issues. Thus, I have left the project and didn’t publish the third semantic content network which is designed to complete the semantic relations based on the source’s context. Even if it doesn’t have knowledge domain terms, and contextual phrases implemented properly, it is configured with enough levels of semantic connections and accuracy, to allow for an overall organic search performance of over three million sessions per month if the third content network is published in the future, accounting for the increasing effect of the second semantic content network as well.
Below, you will see the changing graphics of the İstanbulBoğaziçi Enstitusu on GSC for the last 12 months. The project was launched in May 2021 in a proper way and ended within September 2021 by publishing two Semantic Content Networks.
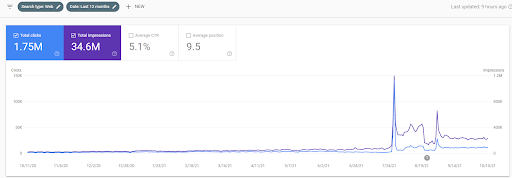
Below you can see the more detailed version. From 1400 daily clicks to 140000 clicks, and then a regular 10.000+ clicks per day can be seen within the Organic Search performance
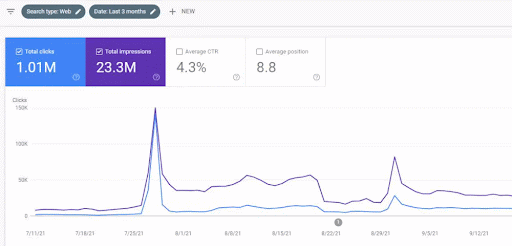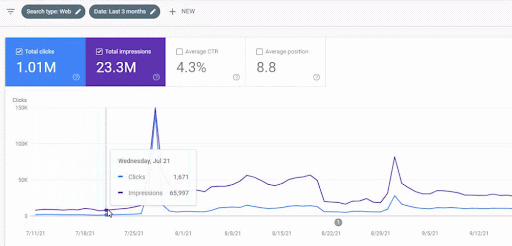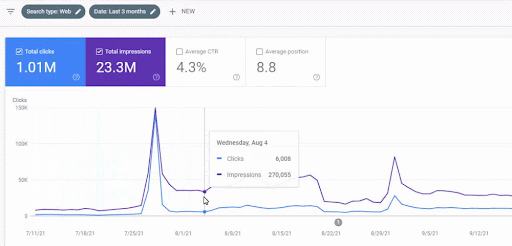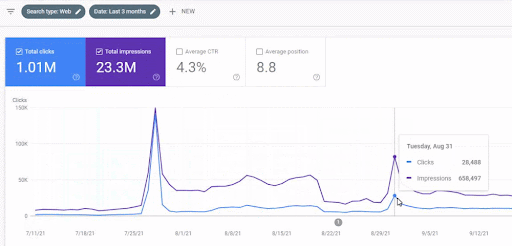
The traffic increase of the first content network after the launch can be seen below.
This screenshot shows the 4th month of the First Semantic Content Network.
As you can see from the graphic, the entire website’s overall traffic has been dominated and affected by the First Semantic Content Network which focuses on the “educational branches”. The second content network that I have launched with this website can be seen below from the Google Search Console. The screenshot below is from the 16th day of the second semantic content network.
The initial ranking and re-ranking have been used within the article because they define the phases of ranking algorithms along with their types and purposes before testing a source, and a web page from the source within the SERP for more important queries that have a popularity.
What is the First Semantic Content Network of the First Project Focused on?
“Semantic Content Network” uses a semantic network from a knowledge base to explain the main, secondary, and tertiary relationships between the things within the knowledge base. Thus, creating a Semantic Content Network requires designing the next semantic content network based on the source’s context which is the website’s main function. In this context, the first semantic content network has focused on “university departments, educational branches, and the necessities for a university education within a specific organization and branch.”
Below, you will find the First Semantic Content Network’s Ahrefs Graphic.
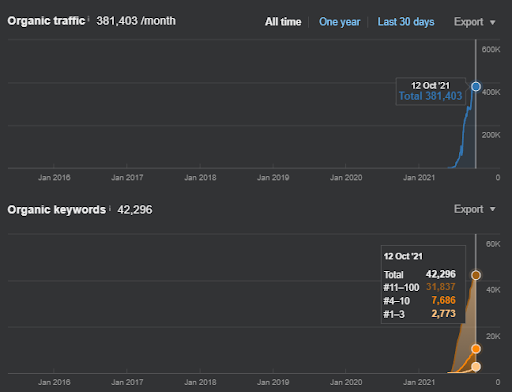
This is five days later from the previous screenshot.
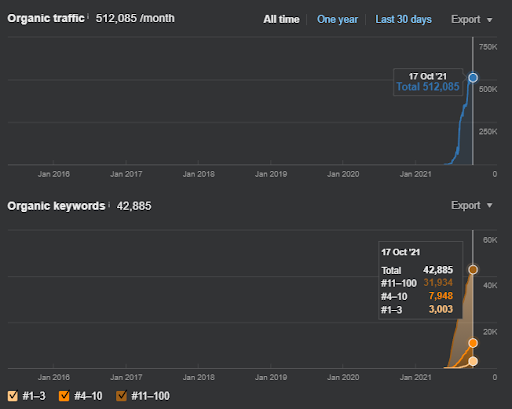
“Root: istanbulbogazicienstitu.com/bolum”, after the first initial-ranking phase, the re-ranking process is more efficient and productive.
You can see the four day later version as below for supporting the nature of the “re-ranking”.
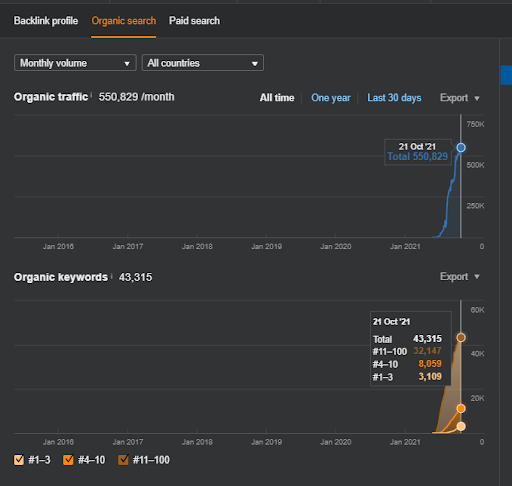
What is the Second Semantic Content Network of the First Project Focused on?
The second semantic content network has focused on the occupations, jobs, skills, and necessary education for these skills, or routine. Based on the first semantic content network, the second semantic content network has been supported. And, according to the “query templates-intent templates”, two more different semantic sub-content networks are created and placed with the “relational connections” while being connected to the upper-similar hierarchical levels.
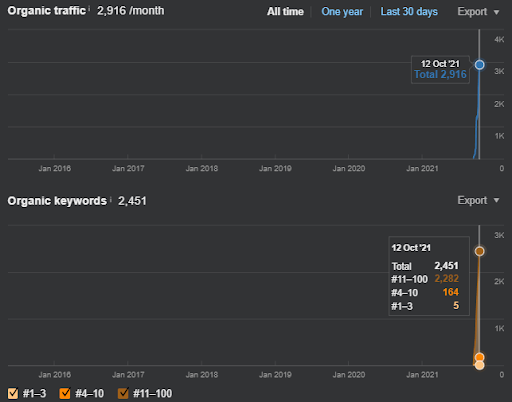
I know that these sections are complicated to you because you didn’t see a definition for the things below, yet.
- Semantic Content Network
- Source Context
- Semantic Sub-content Network
- Knowledge Base
- Relational Connections
- Initial Ranking
- Re-ranking
- Contextual Coverage
- Comparison Ranking
- Fact Extraction
After explaining the second website, it will be easier to understand these concepts and sentences.
Vizem.net: From 0 to 9.000+ Daily Clicks Per Day in 6 Months – Leveraged Comparisonal Ranking with Contextual Coverage
You can see the graph of Vizem.net for the last 12 months. For this project, due to the Covid-19, we have experienced lots of economical problems since the investor is from the gym industry. Thus, I can tell that the economical problems slowed down the project, and it caused some latency for the “Re-ranking processes”.
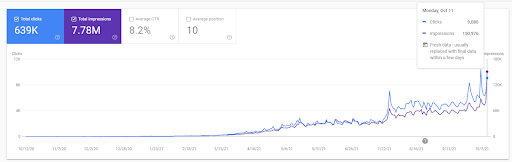
To understand the initial ranking, and re-ranking a little bit further, you can use the graph below.
Some of the definitions related to the Initial-ranking and the Re-ranking from the graphic above can be found below.
- The big ranking jumps happened during the Unconfirmed Google Updates. Some tests gave some Featured Snippets, and People Also asked Questions.
- Some tests from Google removed the FS and PAA earnings.
- Every time, the timeline between two re-ranking processes was shorter.
- The re-ranking processes improved the source’s Rankability every time.
- The source always improved its relevance radius while expanding the query clusters.
As just a note, I can leave a sentence below.
If a Search Engine indexes your web page, it doesn’t mean that the search engine understood the web page. Indexing happens faster than understanding, and most of the time, a search engine ranks a web page with predictions, “initially”. After the understanding, the “re-ranking” happens.
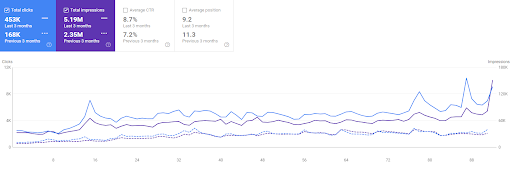
The last 3 months comparison of the Vizem.net
How is the Semantic Content Network of Vizem.net?
I remember that for many of my clients, friends, or secret SEO Groups, during the meetings, I have demonstrated both of these websites by saying, “they will explode”. And, while writing this article, I am telling you this:
Watch the “istanbulbogazicienstitu.com/meslek” Semantic Content Network, because it will explode. And, you can find a video that I have published before writing this article while demonstrating the “Historical Data” from a seasonal event and its effect on the Initial, and Re-ranking processes. You can see it below.
Based on this, the Semantic Content Network of Vizem.net is not similar to the İstanbulBogazici Enstitusu, thus, I didn’t use an “intense level of Topical Coverage and Historical Data increase”, I needed to create the authority related to the certain types of entities, their attributes, and possible actions behind the queries for these entity-attribute pairs. Vizem.net doesn’t have only “educational university branches”, or the “occupations, and online courses” within it. It has “countries for visa applications”. Thus, creating enough level of Topical Authority requires consistency over time with at least 190 different semantic content networks.
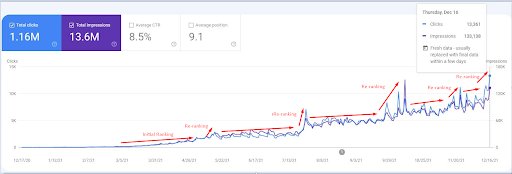
A screenshot from the 18th of December 2021. You can see the continuous re-ranking and increase of impressions and the clicks.This is 4 weeks later from the previous screenshot.
To see the re-ranking events, you can compare the naked version of the organic search performance graphic that demonstrates the Semantic SEO’s effect.
These 190 different semantic content networks are shaped based on the “country” itself, and the countries’ are put into the center of the topical map with every possible contextual layer to improve the search activity coverage.
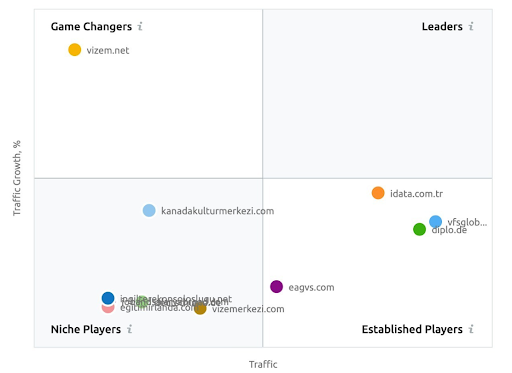
A screenshot from SEMRush showing their perception for the Vizem.net unlike other industry players.
I have also published another video, just for Vizem.net. In this video, the last situation of the website doesn’t exist, thus, I believe, it also provides a nice comparison between today and that day.
Lastly, publishing irrelevant things within an irrelevant article, website segment, or source can decrease the overall relevance of the web entity to the specific knowledge domain. Vizem.net will show its real value, and Rankability in the future will be much better.
The last 6 months comparison of Vizem.net.
Before I continue further, I know that this is a long article. But, actually this is a brief explanation of a highly complex SEO methodology. Semantic Content Networks require too much thinking while designing them, and months of education for clients, authors, and along with the onboarding. Thus, in this article, I want to focus on the definitions of the concepts with the best possible executable brief suggestions and important Google, and other search engines’ patents, research papers along with their own concepts. In the long version (basically, a book), I have focused on “initial ranking” and “re-ranking” of semantic content networks.
If you want to learn more, read the “Importance of Initial Ranking and Re-ranking for SEO”.
Until now, we have processed the things below.
- Semantic Network
- Knowledge Base
- Semantic Content Network
- Knowledge Based-Trust
- Contextual Coverage
- Contextual Domain and Layers
- MuM’s Relevance to the Semantic Content Networks
- Source’s Context
These concepts are to understand how Semantic Content Networks function, and how they can be used with a topical map. The next sections will be about how a search engine ranks Semantic Content Networks Initially and later, Modifying. In this context, the things below will be processed.
- Initial Ranking
- Re-ranking
- Query Template
- Document Template
- Search Intent Template
- What you should do to leverage Semantic Content Networks
What is Initial-ranking for SEO?
This is a new term and concept for SEO, but an old one for Search Engines. The long version of the “Semantic network focused SEO Case Study” focuses on the Ranking Algorithms based on query-dependent, document-dependent, source-dependent algorithms, and multiple patents. Predictive Information Retrieval or predictive ranking algorithms try to decrease the cost of computation. And, even if indexing happens in one day, understanding a document can take months or even years. Computing an initial ranking is therefore a way to improve the SERP Quality while decreasing the cost. Some Search Engine related tasks have higher priority than others for keeping the index alive, fresh, and of high enough quality.

The term initial-ranking appears in tens of thousands different Google Patents and research papers because it is a classical perspective among the search engine builders. Thus, above, you can see different patent documents with continuation of the same paragraphs, and terms with minor changes around the term initial-ranking.
The initial ranking represents the rank of a document on the SERP immediately after being indexed. The initial ranking of a document represents the overall authority, and relevance of the source to the specific topic, query template, and search intent. The same content can be ranked differently in terms of initial ranking between different sources. The initial ranking is important while using Semantic Content Networks to see the overall quality and authority increase of the source. Every new document increases its initial ranking while decreasing the indexing delay if the semantic content network design is correctly structured.
The initial ranking supports the re-ranking process and its efficiency for the source. And, “Rankability of a source” should be processed with these two terms, initial and re-ranking.
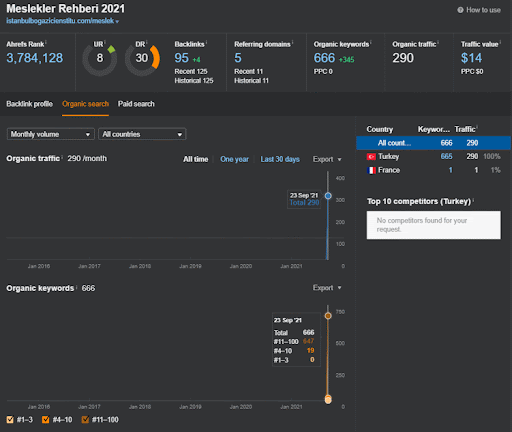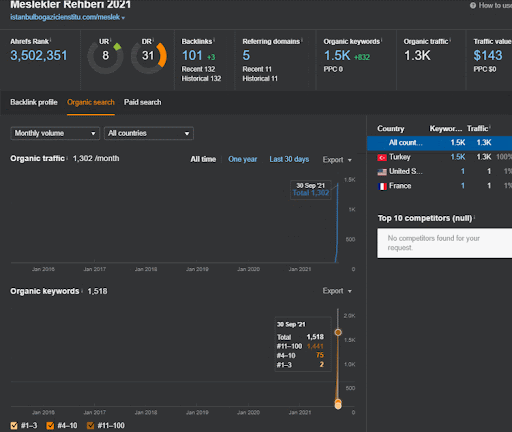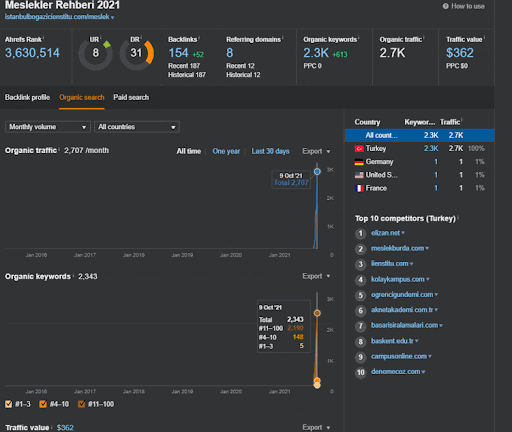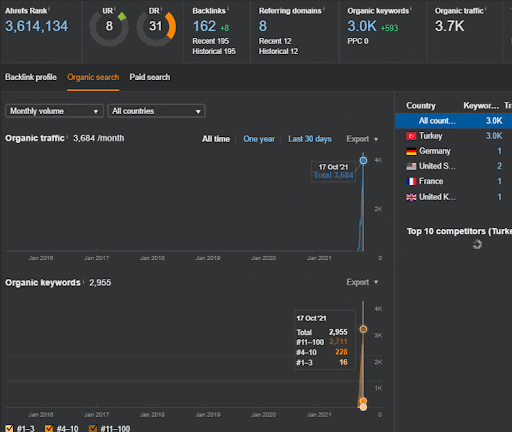
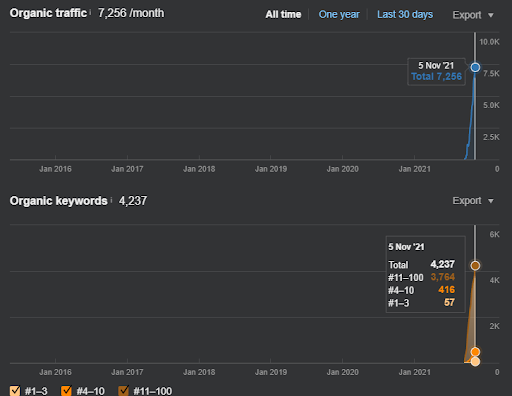
You can watch the first 20 days of the Second Content Network’s organic performance change from Project I.
In this context, whenever Vizem.net publishes a new document, or whenever the İstanbulBogazici Enstitu publishes a new semantic content network, the initial ranking is better than before while the content gets indexed faster.
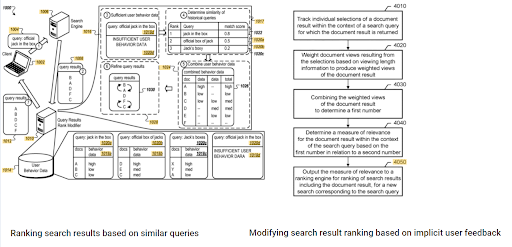
The prominence of the initial ranking and the historical data can be seen between these two complementary Google patents. One is for initial and re-ranking documents based on the implicit user-feedback. The other one is for doing the same if enough level of user data doesn’t exist, based on the similar queries. The similar queries are also the point that relate the Semantics. Creating a Semantic Content Network will decrease the energy for reading the mind of the website owner from the search engine’s point of view.
What is Re-ranking for SEO?
The re-ranking is the process of changing a document’s ranking on the SERP based on the feedback of the users, or relevance, and quality evaluation algorithms. Re-ranking frequency can signal an algorithm update, or an update on the document, or a site-wide update for a source. Re-ranking is affected by the historical data which is explained in the previous SEO Case Study that focuses on the Topical Authority. Examining the re-ranking processes and the feedback from the search engines help for the configuration of the semantic content network design. Re-ranking timelines can be shortened with the help of the actual traffic, as well as with historical data if the contextual and topical coverage is improved.
The re-ranking processes are affected by the initial ranking and the quality of the neighborhood content. The neighborhood content will affect the ranking of any strongly connected components. Re-ranking processes can signal the weak spots, and the ability of the search engine to understand certain sections of the semantic content network. If the design is correctly created, the semantic content network will continue to rise and rise in terms of organic search performance over time, and any Google Updates will confirm these processes.
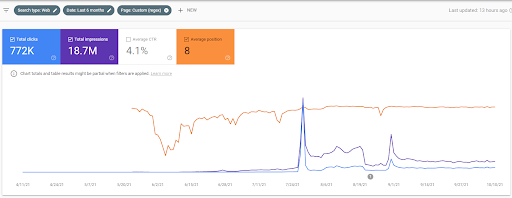
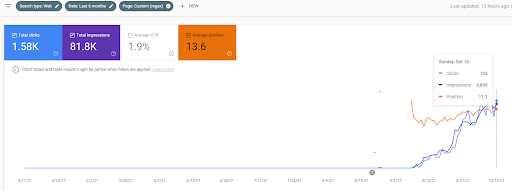
Below, you can see the comparison of the Semantic Content Network 1 and Semantic Content Network 2 of the İstanbulBoğaziçi Enstitu in terms of the initial and re-ranking.
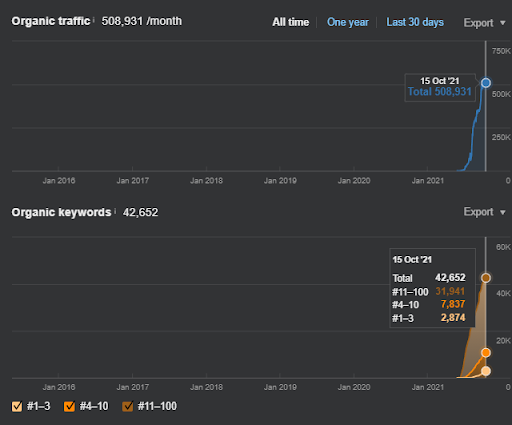
15 October 2021, performance of the first semantic content network of the İstanbulBoğaziçiEnstitusu which is the 124th day of the launch.
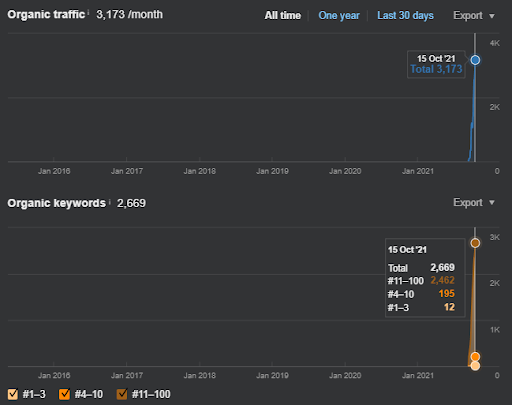
15 October 2021, performance of the Second Semantic Content Network of İstanbulBogazici Enstitu which is the 19th day of the launch.
As you see, the second content network increases the organic query count and the rankings much faster than the first one. The Semantic Content Network 1 has the benefit of the “seasonal SEO” which gives enough level of historical data in a positive way. If there is a seasonal SEO event, the search engine will re-rank the pages, and assign the new relevance-radius and search activity coverage scores to the documents and the sources. Thus, I have chosen to use a “sudden launch” for the “university branches” first. It was the first step of the Topical Authority Building which is equal to the “historical data * topical coverage”.
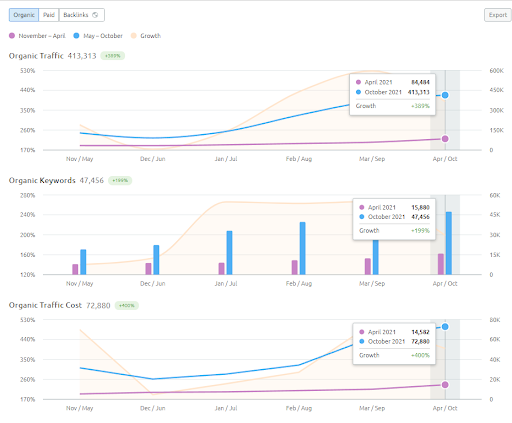
The 6 Months of Growth Comparison of the İstanbulBogazici Enstitu from SEMRush.
Note: To compensate for weaknesses in the execution, I designed a Semantic Content Network 3 to unite the first two using conceptual connections by providing the source’s context. If I launched it, you would see that the source would acquire more than 1,2M organic traffic based on the Ahrefs graphic, in reality, it can be more than 2M. You can see my prediction’s validity from the performance of the Second Content Network. Whenever you check it, you will see that it has thousands of new queries with higher rankings.
In the first Semantic Content Network, the first 3 ranking queries appeared after 2 months’ for the second one, they appeared on the 15th day. You can imagine the increase in authority. Since the knowledge base of the website is left partially incomplete, after the source loses its momentum for semantic network completion, the search engine can prioritize other sources, and it can decrease the re-ranking positivity along with the relevance-radius and Rankability.
Implementing Semantic Networks on these sites makes use of a few concepts and “templates” used by search engines. Before I tell you about the method for setting up a Semantic Network, you should also understand what these templates are and how they work. This will help you understand how search patterns and document structure impact ranking, and therefore why the method I used in this case study is so effective.
The Initial Ranking, and Re-ranking are two different ranking algorithm types for a search engine based on timing. Search engines have other types of ranking algorithms such as query-dependent, query-independent, content-based, link-based, usage-based. To be able to understand the ranking systems, and clustering-associating technology of the search engines, the query-document-intent templates, and their relation to each other should be understood.
What is a query template?
A query template represents a search pattern with ordered phrases that cover an entity for seeking factual information. A query template can have a question format, a proposition format, or an order of word types such as one adjective and one noun. A query template is useful for generating seed and synthetic queries from the point of view of a search engine. A seed query can help a search engine to choose centroids for the query clusters while helping the clustering web page documents, their types, and possible search activities for them.
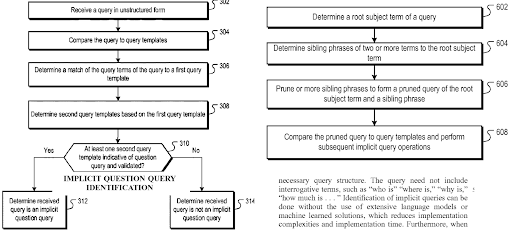
Another Google Patent about “Implicit Question Query Identification” which Nitin Gupta invented along with Steven Baker. “Implicit Question Query Identification” is also related to the question generation which is connected to the “K2Q System”.
In this context, a query template can be used for feeding the search engines’ historical data for creating trust. Even if a search engine doesn’t understand all aspects of a query, or a document for it, still some certain sources can be ranked earlier and better than others because of the document templates. If a source satisfies queries from a template, the search engine will rank the specific source for these types of queries from the same template better initially and during the re-ranking processes. Thus, on the web, we have sources that only focus on a single vertical with a single query template, like Wikihow, or GiftIdeas.

“Query Suggestion Templates” is one of the documents that explains how a search engine can generate query templates based on query logs. Since, Nitin Gupta is one of the inventors of this patent, it has more value for me.
A query template can be used for creating a successful semantic content network, but in page contextual domains, and connections should be configured properly for connecting multiple semantic content networks for multiple query templates.
Note: The topic Query Templates, Intent Templates and the Document Templates are closely related, and another SEO Case Study will be published to demonstrate further details about it.

A section from the Representation Learning for Information Extraction
from Form-like Documents of Google for extracting information from templatic content.
What is a document template?
A document template can signal the purpose of a web page based on the design elements, or even the request size, count and types. If a web page has too much JS, it can be a js-dependent website, or the interactivity needs can be higher than others. This can be confirmed easily by just checking the event-listeners on the web page, or input types, and API endpoints. When it comes to thinking like a search engine, remember that the web is a chaotic place. And, everything possible for understanding the users, especially if the users are Markovian, meaning that they are more influenced by the current page than their history of navigation.

A section that explains how a search engine can use the document templates to see a user’s interest area.
Did you know that Prabhakar Raghavan, the VP of Search on Google, also has a research that asks the same question? “Are Web Users Markovian?”.

A section from the “Are web users Markovian?” research paper.
Yes, they are. Probabilistic Ranking, and Degraded Relevance Ranking are the main columns of a semantic search engine for understanding the users, and creating the best possible highest quality SERP that is prepared for states of possibilities.
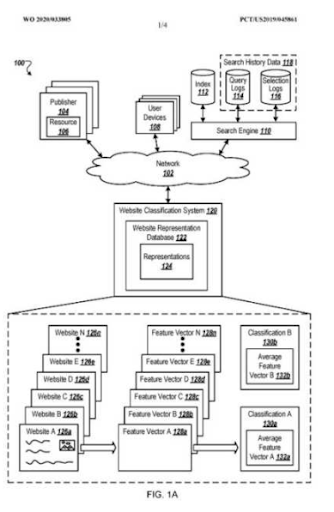
Previously, to make “the website design, and look, or tonality” an argument for the representation learning for websites, Bill Slawski has written the “Website Representation Vectors”.
What is a search intent template?
A search intent template can be represented by the need behind the query template. A query-document template can be united based on an intent template. Having a search intent template with possible “Degraded Relevance Ranking”, and “Probabilistic Ranking” understanding will help for creating the best possible search activity and search intent coverage with correct order. While creating a Semantic Content Network, the most important thing is adjusting the document-query-intent template based on the source’s context for completing a semantic network based on a knowledge domain by improving the contextual coverage to improve the knowledge-based trust and topical authority.
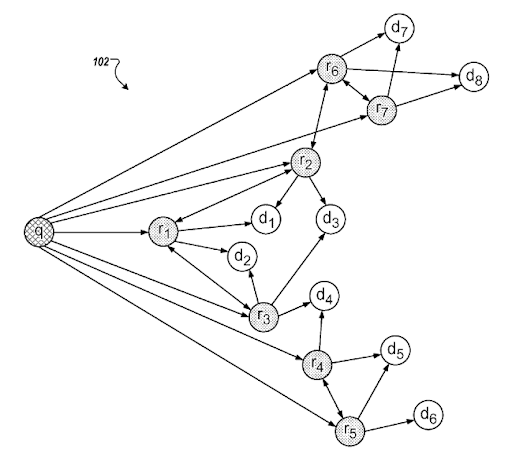
A section from Google’s “Query Refinements based on Inferred Intent”. It works through query clusters and intent templates with semantic connections. You can experience it over different phrase taxonomy levels.
Before moving on to some concrete examples, and suggestions for helping you to create a better semantic content network, I must tell you that even the simple version of this SEO Case Study requires high-level of search engine understanding and communication skills. Thus, even though I feel that I give high-level information, I know that the Semantic SEO course that I will create will show you some more and better concrete examples.
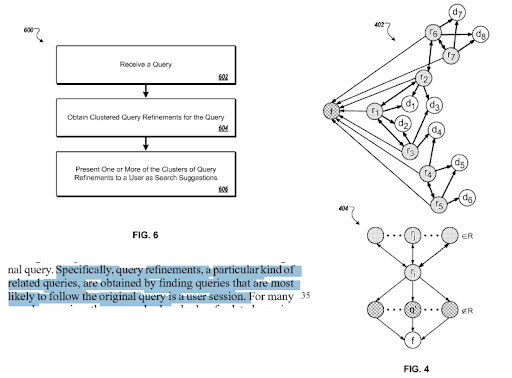
Same patent explains the proper connections between different “query paths” and “context shifts”.
What you should know about leveraging Semantic Content Networks?
To create a Semantic Content Network, sometimes even a simple semantic content brief and design can take one hour, if you put all of the relevant details based on the lexical semantics, or the relation types between entities, and phrases. Using multiple angles at the same time such as phrase-based indexing, and the word vectors, or context vectors for calculating the contextual relevance of a content overall to a contextual domain, or its relevance as based on the individual sub-content types, it requires high-level of semantic search engine understanding.
Thus, using a generative methodology will make everything easier with the concepts that I have explained to you above, because even if you prepare every semantic content network part perfectly, the authors and writers won’t be able to write it, or the content managers won’t be able to follow your vision. Thus, it might tire you for nothing, and make you leave a project as I did for some of these SEO Case Study Projects after I prove the concept in a enough, lively and auditable way.
The suggestions below will be only for easy executable and brief steps that will help you.
1. Do not use Fixed Sidebar Links from Every Semantic Content Network Nets
Every link should have a connection description between two hypertext documents like every word within a web page. The Semantic HTML Usage can help to specify the position and the function of a document on a web page while helping search engines to weight the sections differently in terms of context.
In the Vizem.net example, I didn’t use the same sidebar design. The sidebar didn’t show the latest posts, or most critical ones. The sidebars only show the attributes of the central entities, and they are not fixed, they are dynamic. In other words, based on the hierarchy within the topical map, the semantic content network nets change even if they are in the sidebar.
Thinking about the Reasonable Surfer and Cautious Surfer Models can help an SEO to create a better relevance between different hypertext documents.
Additionally, the link flows in terms of prominence, and the popularity should follow the source’s context from the best possible connections. Below, you can see the sidebar sections with adjusted Semantic HTML codes.

According to the hierarchy of the article that is active on the session of the user, the tabs, the order of the tabs, the links within the tabs will change. The example above is from the breadcrumb hierarchy below.
![]()
![]()
2. Support the Semantic Content Networks with PageRank
Even if the external PageRank is not a must from the external sources, if you are able to use it, you will realize that the initial ranking and the re-ranking will be better. For both of these projects, I didn’t use them, but this time, it wasn’t the purpose. For Vizem.net, there were economical problems, and I didn’t want to spend the budget on digital PR and outreach. For İstanbul BoğaziçiEnstitusu, I arranged a couple of “locally inter-connected sources” to support the authenticity of the source for the specific topic, but again, the company was unable to implement this due to budget and organizational discipline issues.
Detecting Query-specific Duplicate Documents is an important perspective from Search Engines, because the PageRank can help a document to be filtered as valuable even if it is duplicated. Since, the highly organized semantic content networks can be similar to each other, the PageRank flow, and historical data is useful.
When it comes to choosing the external PageRank flow point for these types of semantic content networks, use the sources with historical data. In my case, I had arranged these PageRank endpoints earlier, before I launched and published the first semantic content network. This way, I was able to take external references from direct competitors, but when I published the semantic content network, the competitors gave up linking the source because they have seen the mass increase of the source as a competitor.
This situation brings us to the third suggestion. If we would be able to use the PageRank flow from external references, the process of re-ranking would be faster, and initial ranking would be higher.
3. Use Different Anchor Texts from Footer, Header and Main Content for the Prominent Semantic Content Network Parts
Anchor texts or the “link text” from the point of view of the search engine signals the relevance of a hypertext document to another. According to the original document of the PageRank, the link count is proportional to the PageRank flow. But, later Google changed this to prevent “link stuffing” and limited the links that can actually pass the PageRank. Based on this, the TrustRank, Cautious Surfer, Hilltop Algorithm, or the Reasonable Surfer Models are developed.

These are two links to the two different semantic content networks for the BogaziciEnstitusu, but since I didn’t implement technical SEO, or UX improvements, you can realize the “cheapness” of the button designs.
According to Google, the same link can’t pass PageRank a second time to another web page, while the PageRank will be passed only from the first link. And, in the original form of the PageRank algorithm, a hypertext document can link itself to improve its PageRank, or 301 redirects can be used to take PageRank of the link target document. Both of these situations created old Black Hat Techniques such as redirecting a web page to another one temporarily for just taking its PageRank. This was from the days that the SEOs were able to see the PageRank of a web page from Google Search Console or the SERP. Later, Google started to dampen the PageRank with every redirect while Danny Sullivan explained that 301 redirects will pass PageRank fully. Besides all these changes, the important thing here is that even if the second link doesn’t pass the PageRank, still it passes the relevance of the link text.

Prominent sections of the Semantic Content Network have been linked from the HomePage based on the “middle query refinements” which include the “verbs, predicates”, or “activities of searcher”.
Thus, the prominent sections of the Semantic Content Network should be linked from the header and footer menu with the higher taxonomy sections, and the link texts should be different from each other. In these examples, I have used the header links with the prominent but short link texts while I kept the footer examples longer.

A section of the “Anchor Tag indexing in a web crawler system”, it summarizes the importance of an anchor text, and annotation text to position a web page within the query clusters, and web page clusters.
If the Semantic Content Network section is too prominent, to pass the PageRank and crawl priority properly, I have linked the most important sections with proper link texts, and explanatory paragraphs that include the prominent attributes with different variations of relevant N-Grams.

This is the second linked area from the homepage of the Vizem.net, it is behind an accordion, and it focuses on the countries within the queries, and it links the middle section of the semantic content network.
Note: Around the Anchor Texts, always, a planned “annotation text” has been used to improve the precision of the purpose of the link.
4. Limit the Link Count Restriction and Matching the Desktop and Mobile Links and Main Content
Both of the projects are restricted to have less than 150 internal links per web page. With the help of the Semantic HTML, the places of the links, and functions of the links are made clear to the crawlers. The İstanbulBogazici Enstitusu had more than 450 links per web page, and some of these were self-links (a link from the same page to the same page). The worst part is that half of these links didn’t exist within the mobile version of the content.

URL Keep Score, the Crawl Score, and other types of scores can be used to determine a link’s prominence within the internal URL Map, and document identification tags within the different tiers can be used to sort the index based on query-independent relevance scores.
Since Google uses mobile-only indexing, if the content doesn’t exist within the mobile version, it will be ignored, and not used for relevance evaluation and ranking purposes. Thus, the mobile and desktop content has been configured to be matched with each other. Even if Google tolerates the content mismatches between the desktop and mobile versions, it still makinges understanding and ranking a web page harder for the search engines.
A search engine can generate a sitemap for the website, and this sitemap can be re-generated in a loop, if the links, and URL metadata are not matched between user-agents, or timelines. Thus, keeping the crawl path short, crawl queue brief, and internal links consistent is important.
Along with the links between different web pages, also links for the subsections of the web pages are used with the “table of the content”, and the “URL Fragments”. These URL Fragments target a specific sub-section of the web page while naming it properly, and the specific section has been put into a section tag with a h2. With the help of URL Fragments with the “in-page navigation links”, landing a user from SERP to the specific section of the web page was easier, while the bottom sections of the content have been made more prominent for satisfying the need behind the query.
5. Have a Military Level Discipline for Your SEO Projects
This is entirely another topic and another article can be written to define what the military-level discipline means, or why it is useful for an SEO Project. But, I must tell you that during these last 2 months, I have trained lots of CEOs, and SEOs from other agencies along with their teams to see whether my course design will work well or not.
Whenever I see success, and a high level of grasping for the education sessions that I perform, there is a strong will and perseverance. The main problem is that Semantic SEO is way much harder than the other SEO Verticals. Technical SEO is universal, and it has even written guides for every step. The OnPage SEO, or WUX and Layout Design can be tracked with numeric measurements. When it comes to Semantics, it is the practice of uniting the perspective of a machine that works based on a complex adaptive system with homo-sapiens that do not understand how the machine works.
This distinction requires a concrete base ground that should be put from the first day of the project. Most of the time, I use the rules below.
- The content designs and the semantic content network doesn’t have to be logical to an author, or writer.
- The task of the content manager is to audit the content’s compatibility with the content design.
- The task of the author is writing the content with the related information that includes a high level of accuracy and detail.
- The links, definitions, evidence, comparisons, propositions, references should be made with concrete examples, not with fluff.
- Every unnecessary word is a dilution for the context and the concept.
When you read, it might sound easy to implement, but it is not so easy. Thus, I can tell that I even was about to fire some of my own employees. I am glad that I didn’t, at least for now. In normal conditions, there will be lots of questions that you will be asked, if the question owner is not an SEO or owner of the company, do not answer. Save your energy to the search engine’s data storage that will store your positive feedback, not the redundant and irrelevant feedback to the rankings.
6. Expand the Source with Contextual Relevance
This section is totally about understanding Google’s need for creating the MuM. When you design a Topical Map, it will include lots of Semantic Content Networks that will provide a better site-level Knowledge Base. Thus, while publishing these sub-sections, they should be able to connect to the source’s context, or it can change how the search engine sees the source, and the theme of the website can switch to another knowledge domain. For example, connecting things around concepts and interest areas with possible actions require understanding complicated meanings’ connections to each other. Making these connections clear to a user, a writer and also a machine at the same time is the process of Semantic Content Network creation.

To accomplish this, every new section for the website should be able to be connected to the central section of the topical map. These contextual bridges can be seen from Google’s own LaMDA design and explanation.
I encounter lots of questions such as “should I write about another topic”, “if I have two different niches, will it harm?”. If you connect all these sub-sections, web-site segments as strongly-connected components, these semantic content networks will support each other for better rankings instead of dividing the brand identity, and topical authority for two different and irrelevant topics.
7. Create Actual Traffic and audit with Google Analytics Custom Segmentation
Actual Traffic is connected to the RankMerge in the same way that the Knowledge-based Trust is connected to the PageRank. Soon, I am thinking of writing another article with the title of “When the PageRank Lies…” to explain why the search engine tries to affect the PageRank with side-signals. In fact, PageRank is not a definitive signal that shows the authority, expertise and trustworthiness of a source. It can be a signal for ranking, and a factor, but it can’t be trusted alone. RankMerge is the process of uniting the website traffic and the PageRank in a way that the website can make sense to the search engine. High PageRank and low traffic can signal the “unpopular traffic”, or the “PageRank manipulation”.
Thus, to improve the historical data of the source, I have used the seasonal SEO Events, and I have increased the “brand + generic term” queries. The direct traffic, and the bookmarked web pages are increased with actual and authentic traffic.
These types of data help a search engine to trust it for ranking it higher and higher on the SERP.
To be able to audit these actual traffic that come from the Semantic Content Network, an SEO can create a custom segment from Google Analytics to see how they come as direct traffic. Also, custom Goals can be created such as creating a possible search journey from the first Semantic Content Network to the Second Content Network. This is the proof of concept that the semantic network is constructed around the interests, concepts and possible search related actions.
Below, you will find only one example for the one of the web pages that are placed within the first Semantic Content Network for demonstrating the acquired direct traffic via organic traffic.
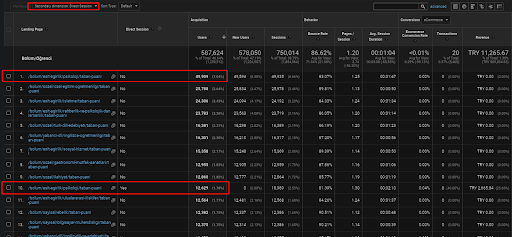
In the last 3 months, only one web page from the first semantic content network has been used by the 49.000 organic users. And, 12.900 extra users came as direct traffic which was acquired by organic search for the first time. And, the session/page metrics and the average session duration is higher for these user segments.
As said before, a search engine can cluster queries, documents, intents, concepts, interests, actions, but also it can cluster users. If a user group leaves positive feedbacks while creating a brand value by adding these web pages to the bookmarks, typing the address bar directly, and searching the generic terms along with the brand name, it shows that the source improves its authority, and search engine is able to recognize everything from the SERP, Chrome, and its own DNS addresses.
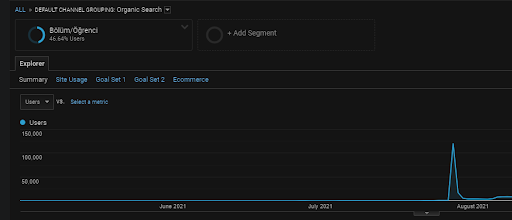
Above, you can see the First Content Network’s user-segment. You can create a user-segment for every Semantic Content Network with custom goals, and you can add sub-user segments for the Semantic sub-content networks as well.
8. Support Semantic Content Networks with Sub-sections based on Search Activities
This section is also about entity attribute resolution, and analysis which is another topic. But, simply put, some attributes of these entities based on contextual domains should be put in a lower hierarchy, not into the upper hierarchy. In this case, the “Vizem.net” can give a better example, while for the Boğaziçi Enstitusu, it can be demonstrated with “Salaries of Occupations”, and “Exam Points of Universities”. These two prominent attributes have been placed based on the query and document templates to the semantic sub-content networks.

The Identification of Semantic Units from within a search query is another Google patent that divides the phrases into different semantic categories, and aggregates the relevance of a document based on its closeness to the all variations of the query.
In a previous SEO Case Study, I didn’t follow this type of a structure, I created a crawl path based on the “chronology” and the internal links that are strictly limited. In these articles the main-content placed internal link amount is higher than the previous one.
9. Use Thematic Words within the URLs
If Google encounters two different URLs with the same content without any canonicalization signal, it chooses the short one as the canonical one. Because, short URLs are easier to parse, resolve and request. When you have trillions of web pages that you refresh billions of times everyday, even the letters in URLs can show the “cost/quality balance” of a website. As I said before, “cost of retrieving” should be lower than the “cost of not retrieving”. If you want to be understood by a search engine, you should put the “ordered and complementary context signals” to every level, including the URLs.

A section from the “evidence-based” ranking via evidence aggregation. It explains how an answer can be matched with a question.
In this context, most of the time, I use a single word within the URL. These can reflect the hierarchy and structure of the semantic content network. Some still think that the “layer count” within the URL affects the crawl frequency, before 2019, it was true. But, as long as the content makes sense, and satisfies the users from a popular or prominent topic, it won’t be affected by such a situation.
To demonstrate it, you can follow the example below.
- Root-domain/semantic-content-network-1/type-1/sub-content-network-part-for-type-1
- Root-domain/semantic-content-network-2/type-2/sub-content-network-part-for-type-2
These two semantic content networks can link each other from the same hierarchy, and they can link themselves based on the relevance as well. There are more things here we can talk about such as the “Entity Grouper Contents – Hub Type Content”, but another day’s topic.
Note: The planned Third Semantic Content Network can be processed as a “Conceptual Grouper Content Network” as well. And, if it is published, with the effect of the Second Semantic Content Network, the overall Organic Traffic can be over 3 millions sessions per month.
10. Understand the Difference between Nesting and Connecting
As a practical methodological difference, the connecting is the connecting similar things to each other based on a contextual domain, while nesting is grouping the similar content with the same purpose together. This clustering will help a search engine to find similar content to each other faster and creating a source quality score for these groups, or these nested contents based on a semantic network will be easier.
Imagine there are two different crawl paths as below.
- Crawl Path 1: Encounters URLs randomly, without a template, similarity and contextual relevance.
- Crawl Path 2: Encounters URLs that make sense even from the URL’s itself, with a template, high-level of similarity and relevance based on context.
If even from the crawl path, the content makes sense, the “initial-ranking” and the “re-ranking” will be better thanks to the “re-ranking triggering based on coverage understanding of the search engine”.
Note: Using internal links with phrase-taxonomy in a proper way is important for nesting and connecting.
This brings us to the last two practical methodology sharing briefly. And, this section is again related to the high-level of discipline and organizational sufficiency.

A patent from Trystan Upstill and Steven D. Baker for recognizing the co-occurring terms within the HTML Lists. The prominence of this patent is that it shows the value of a single HTML List to determine the co-occurring term lists for a topic, or a part of the phrase taxonomy.
11. Understand When to Publish a Semantic Content Network with a Adjusted Frequency
This has been explained before, but in one of these SEO Case Study Projects, I have published nearly 400 pieces of content in one day. When it comes to the other one, I have started to publish only 10-15 content suddenly, then I have increased the velocity over time with a steadiness until the Covid-related Economical problems start.
If a new source creates a new Semantic Content Network, publishing it on the first day might be a little bit harder than you think, checking all the internal links, grammars, and information on the web page is not so easy. But, if all of the content is just from a single topic, and a query template, and if the source doesn’t have any history on that topic, publishing most part of the semantic content network has advantages such as faster indexing, understanding and re-ranking.
In my situation, there was also a historical event with seasonality. So, my purpose was having enough level of average position until I will be able to be tested by the search engine for the specific entities and search activities against the older sources. Thus, I have published the first Semantic Content Network with a high-level of preparation before the 45 days from the seasonal event.
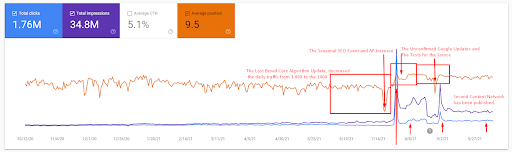
Then, you can see how the Search Engine tested the source repeatedly as below.
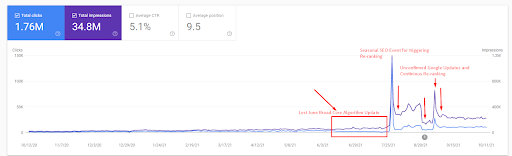
A more detailed explanation can be found below.
A quick fact check can be found below for the screenshot explanation above.
- The Broad Core Algorithm Update has decreased the traffic of the website more than 200%.
- The website also lost more than 15.000 queries.
- This affected the overall indexation of the source for the new semantic content network as in the detailed SEO Case Study article has been explained better.
- Thanks to the Seasonal SEO Event, the re-ranking happened earlier, and after the seasonal SEO Event, the search engine normalized the ranking of the source based on the actual traffic during the unconfirmed updates.
- The queries, and the rankings that are acquired thanks to the First Semantic Content Network and the Seasonal Event have been protected, and further improved.
- The first Semantic Content Network also supported the new and second Semantic Content Network.
The query loss and the average ranking loss also can be seen from Ahrefs as below. You can check the June 2021 Google Broad Core Algorithm Update (GBCAU) effect along with the unconfirmed update’s effect.
Thus, using a Semantic Content Network with multiple possible strategies is a necessity. Even if the GCBAU is lost, still, thanks to other factors related to the search engine natura can help an SEO. Thus, you might imagine why explaining these things to an author, or a client is harder than Technical SEO. Semantic SEO doesn’t use numeric values, it uses Theoretical Knowledge that comes from Search Engine Understanding via patents, research papers, experience, and historical announcements.
12. Use In-page Sentence Optimization for Better Factual Structure
To be honest, even the 10th listing is an entirely new topic and it can require even writing 20.000 words here. But, I will start with a simple example.
- X is Y.
- Y is X.
For the example sentences above, you can understand the things below.
- The sentences above are not duplicate content.
- The propositions above are duplicate.
- The relational explanations between two sentences are the same.
- The Semantic Role Labels are 100% different.
- The Named Entity Recognition output is 100% the same.
In-page Sentence Optimization is related to the Question Generation Algorithms and Question-answer pairing technologies. A question format requires a certain type of a sentence. And certain types of questions should be answered with certain types of sentences. The content format, the NER and Fact Extraction will be affected from the sentence structure optimization.
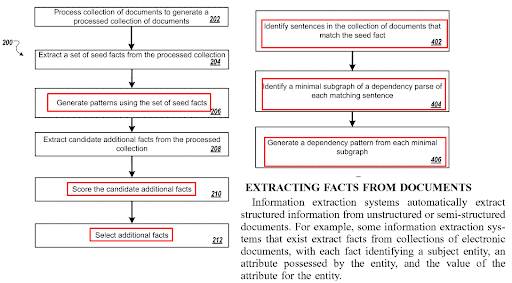
The triplets (one object, two subjects) can be extracted and checked in terms of accuracy faster. Two similar sentences don’t mean that they are duplicate, it means that they are close to each other in terms of the sentence structure. As long as the proposition is different, using similar sentences between similar document templates for different query-intent pairs is a necessity for semantic content network creation.

Clear sentence structures with a proper pattern is useful to make text pieces more relevant to each other while helping a search engine to recognize named entities, and subjects, attributes, along with their values to each other.
It will also help to see which section of an article can be made better, and in the Topical Nets, where your content ranks better for what types of word pairs, word vectors and intents. Because, if certain types of sentence structures for certain types of questions can be observed across multiple web pages, it will help for Advanced SEO A/B Tests with endless amounts of data samples, and test samples. You can create multiple in-page sentence designs to check how a search engine extracts the facts for comparing it.

When it comes to giving the facts, the “Knowledge Vault”, and the Luna Dong should be remembered.
13. Give Real World Information with Precision and Consistency not Opinions with Fluff
The precision here means being able to be compared with numeric values, or conceptual concrete relationships. The consistency means that you protect your stance for the specific proposition. For instance, do not say that “X product is best for Y” for every product review related to the Y. Do not give contradicting propositions site-wide. And, if the product is best, what is the proof of it? Material, the size, or the color and smell? Fluff within the text means that you use unnecessary bridge words, or do not tell things that are not possible to prove, or contradicting the truth.
In the context of these non-definitional instructions that are supported by some of the examples, you can check one of the Language Models of Google which is KeALM.
It is for generating text from a database with the data-to-text models, and it is for checking the accuracy of the content.

KELM is an example of Accuracy Audit for the propositions with text-to-data methods.
This is also a little bit about the definition of the “Triplet ”, and “Open Information Extraction for Unknown Entities”, but as you know, this is the brief version, and I guess, I have told enough. Basically, when you give wrong information on your website, be sure that Google is able to understand it to decrease the Knowledge-based Trust of the source. Here, you might need to also know that, since you are able to expand the Knowledge-base, a search engine can change its own knowledge-base based on your information, if you have a Correlated Source with PageRank, and Knowledge-base Trust with high accuracy, and unique triplets.
14. Understand the Semantic Dependency Tree for Entities
Semantic Dependency Tree means that attributes that signal relationships with other entities have a hierarchical dependency between them. Semantic Dependency Tree can be observed by checking multiple entity profiles and angles such as a country can be a member to an organization, and as another entity, this organization can have some other attributes that can be attributed to the connected countries with inferred relationships.
Below, you will be able to see a simple example from the Search Engine, directly.

REALM is a method that uses Semantic Dependency Trees to extract information from ambiguous text.
On the open web, the open information extraction can recognize new named entities, and extract these same entities as co-occurring with other entities. These co-occurrences and mutual attributes within the article can assign a context and candidate relation type between entities. Based on the connections, and type of the entity, the semantic dependency tree can be created. The same logic occurs for Lexical Semantics as well. The word “boy” has some possible meanings and some exact other meanings. Such as, a boy is a male, and probably a teenager who is not married. It can be used close to the student as well. The word “Queen” on the other hand includes other side-and exact meanings such as “female”, and “being a governor”. Thus, having something to govern is a natural semantic dependency tree hierarchy that can signal some certain types of query templates such as “Queen of…”, or “For Quen”. These contextual layers with context qualifiers should be united naturally with contextual domains and knowledge domains for improving the topical and contextual coverage together.
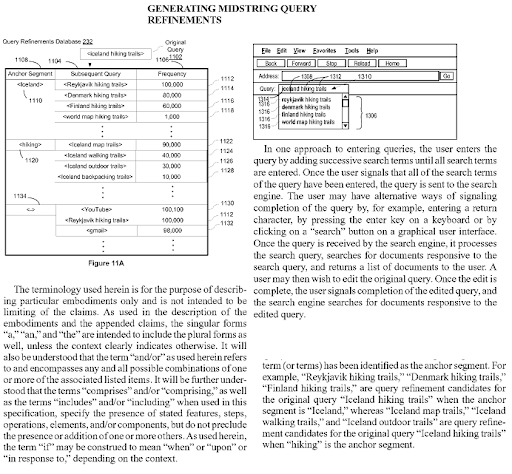
Generating Midstring Query Refinements is another Google Patent that shows the Semantic Content Network’s connections to each other. Every midstring query refinement is a part of the topic’s sub-topical net. A semantic content network that focuses on all these query refinement candidates with the correct semantic annotations will have the advantage of better re-ranking and initial ranking.
Last Thoughts on Semantic Content Network
I know that this content was highly technical in terms of Semantic SEO. And, before publishing my Semantic SEO Course, I still want to increase the knowledge, so that the first theoretical lessons can be digested by our minds faster than usual. The Semantic Content Networks can be defined as the sum of topical map, and individual content designs that include all of the headings, questions, heading levels, anchor texts, content hierarchy, and positions within the site-tree, or anything related to the content piece, including the featured images and in-page detailed images.
Here, besides the in-page sentence structure designs, or question-answer formats, or synonym sentence formats, we can also talk about the contextual vectors, contextual hierarchies, sequential sentences with bridged contexts, or evidence-based ranking by evidence aggregation. All these things would make this SEO Case Study and Guide more complicated but yet detailed. Thus, like in the previous, Importance of Topical Authority SEO Case Study and Guide, explaining Semantic Networks would make that article more complicated but yet detailed.
The future SEO Case Studies will include more and more details by supporting the previous ones. Lastly, I have gotten lots of screenshots and thank you messages from all of you that show the positive results that you have gotten thanks to Topical Authority understanding. I hope, Initial-ranking, and Re-ranking along with the Semantic Content Network understanding help you further.
See you in the next SEO Case Studies.
“The acquisition of knowledge is always of use to
the intellect, because it may thus drive out useless
things and retain the good. For nothing can be
loved or hated unless it is first known.”
– Leonardo da Vinci.
