
Bots, also known as Crawlers or Spiders, are programs that “travel” across the Web automatically from website to website using the links as the road. Although they have always presented certain curiosities, robot.txt files can be very effective tools. Search engines such as Google and Bing use bots to crawl the web’s content. The robots.txt file provides guidance to the different bots as to which pages they shouldn’t crawl on your site. You can also link to your XML sitemap from the robots.txt so that the bot has a map of every page it should crawl.
Why is robots.txt useful?
robots.txt limits the amount of pages that a bot needs to crawl and index in the case of search engine bots. If you want to avoid Google from crawling admin pages, you can block them on your robots.txt in order to try and keep a page out of Google’s servers.
Besides keeping pages from getting indexed, robots.txt are great for optimizing for crawl budget. Crawl budget is the number of pages that Google has determined it will crawl on your site. Usually websites with more authority and more pages have a larger crawl budget than websites with a low number of pages and low authority. Since we don’t know how much crawl budget is assigned to our site, we want to make the most of this time by allowing Googlebot to get to the most important pages instead of crawling pages that we don’t want to get indexed.
A very important detail you need to know about robots.txt is that while Google won’t crawl pages that are blocked by robots.txt, they can still get indexed if the page is linked from another website. To properly prevent your pages from getting indexed and appearing in Google Search results you need to password-protect the files on your server, use the noindex meta tag or response header, or remove the page entirely (respond with 404 or 410). For more information regarding crawling and controlling indexation you can read Oncrawl’s robots.txt guide.
[Case Study] Managing Google’s bot crawling

Correct Robots.txt Syntax
The robots.txt syntax can sometimes be a little tricky, since different crawlers interpret syntax differently. Also, some non-reputable crawlers see robots.txt directives as suggestions and not as a definite rule that they need to follow. If you have confidential information on your site, it is important to use password protection besides blocking crawlers using the robots.txt
Below I’ve listed a few things that you need to keep in mind when working on your robots.txt:
- The robots.txt file needs to live under the domain and not under a subdirectory. Crawlers don’t check for robots.txt files in subdirectories.
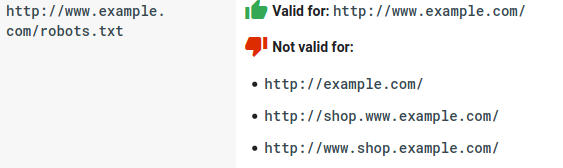
- Each subdomain needs its own robots.txt file:
- Robots.txt is case sensitive:
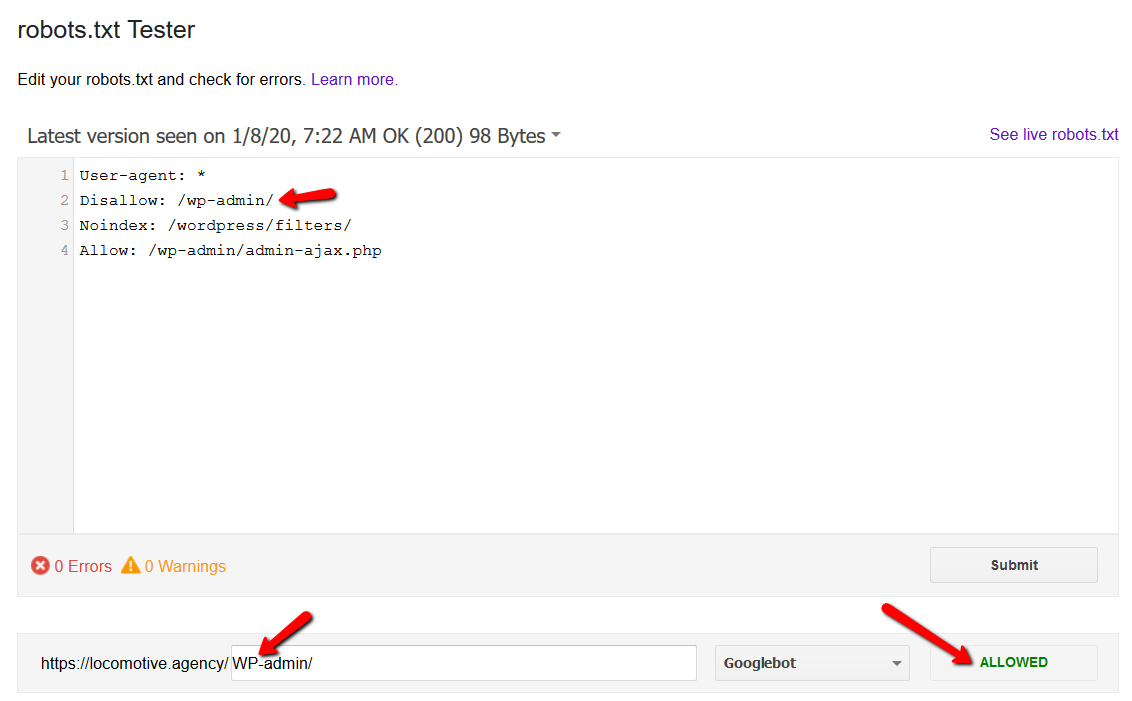
- The noindex directive: When you use noindex in the robots.txt it will work the same way as disallow. Google will stop crawling the page but will keep it in its index. @jroakes and I created a test where we used the Noindex directive on the article /wordpress/filters/ and submitted the page in Google. You can see on the screenshot below that it shows the URL has been blocked:
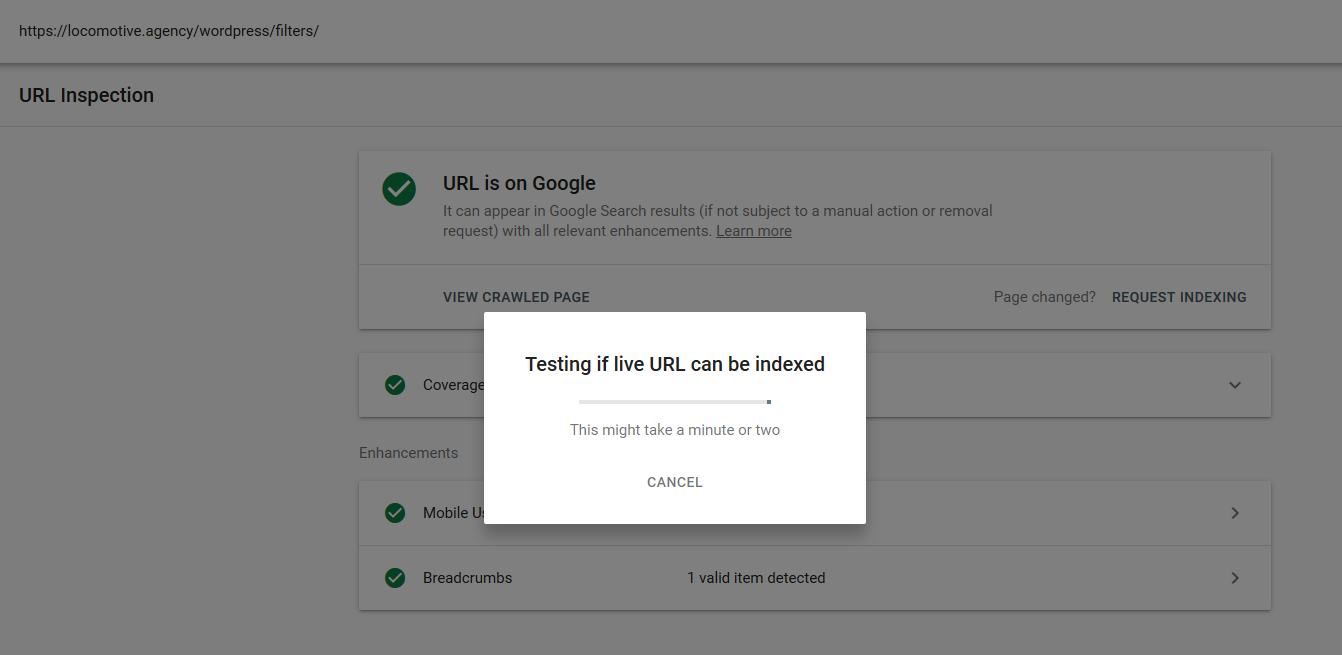
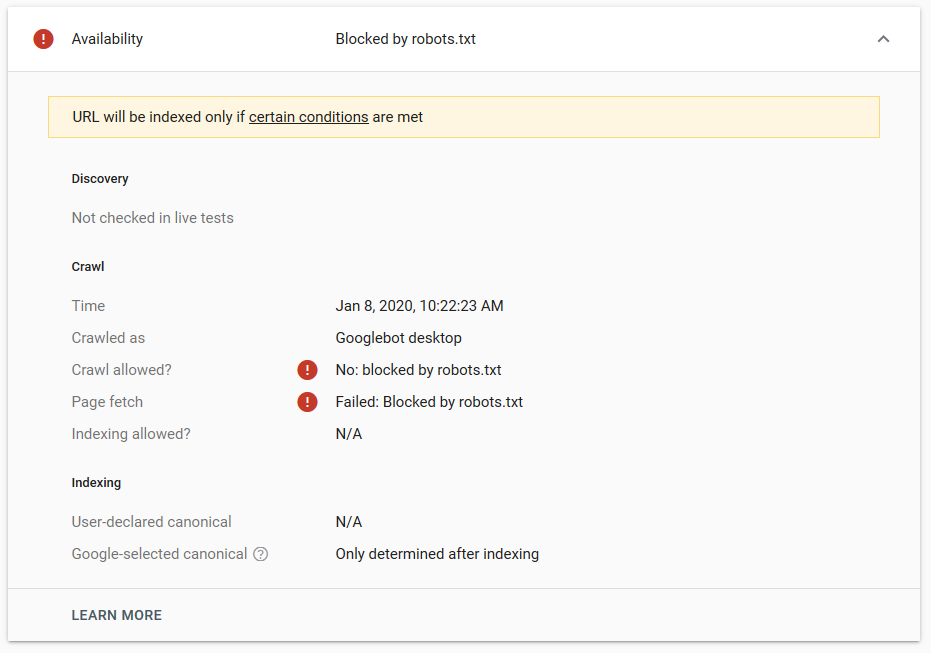
We did several tests in Google and the page was never removed from the index:
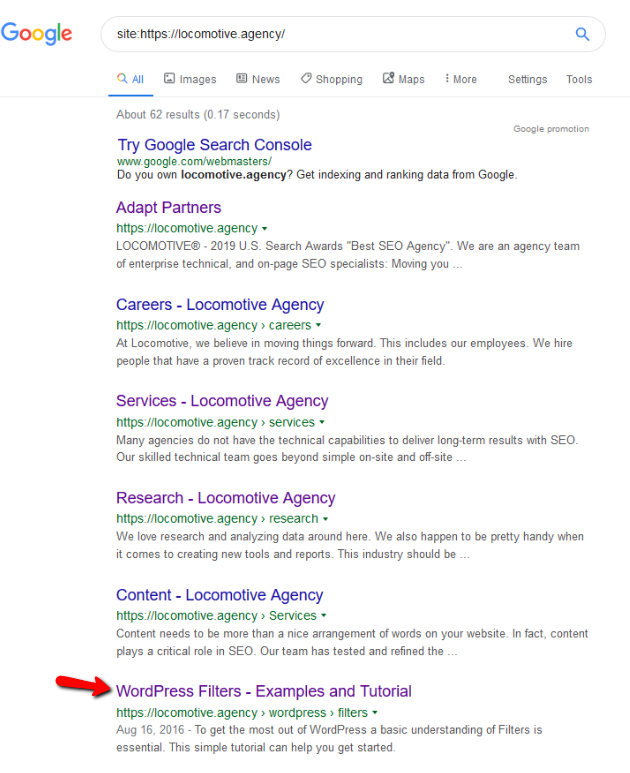
There was a discussion last year about the noindex directive working in the robots.txt, removing pages but Google. Here is a thread where Gary Illyes stated that it was going away. On this test we can see that Google’s solution is in place, since the noindex directive did not remove the page from the search results.
Recently, there was another interesting thread on twitter from Christian Oliveira, where he shared several details to take into consideration when working on your robots.txt.
- If we want to have generic rules and rules only for Googlebot, we need to duplicate all the generic rules under the User-agent: Google bot set of rules. If they are not included, Googlebot will ignore all of the rules:

- Another confusing behavior is that the priority of the rules (inside the same User-agent group) is not determined by their order, but by the length of the rule.
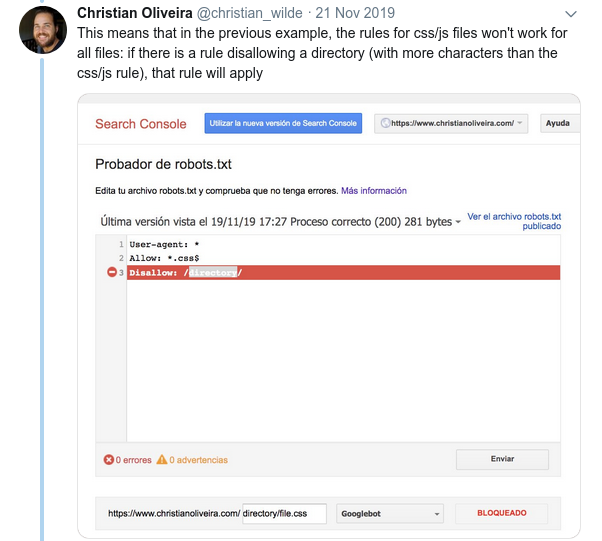
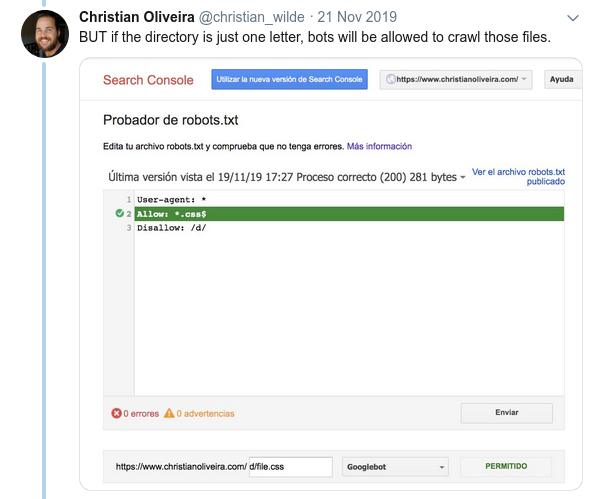
- Now, when you have two rules, with the same length and opposite behaviour (one allowing the crawling and the other one disallowing it), the less restrictive rule applies:
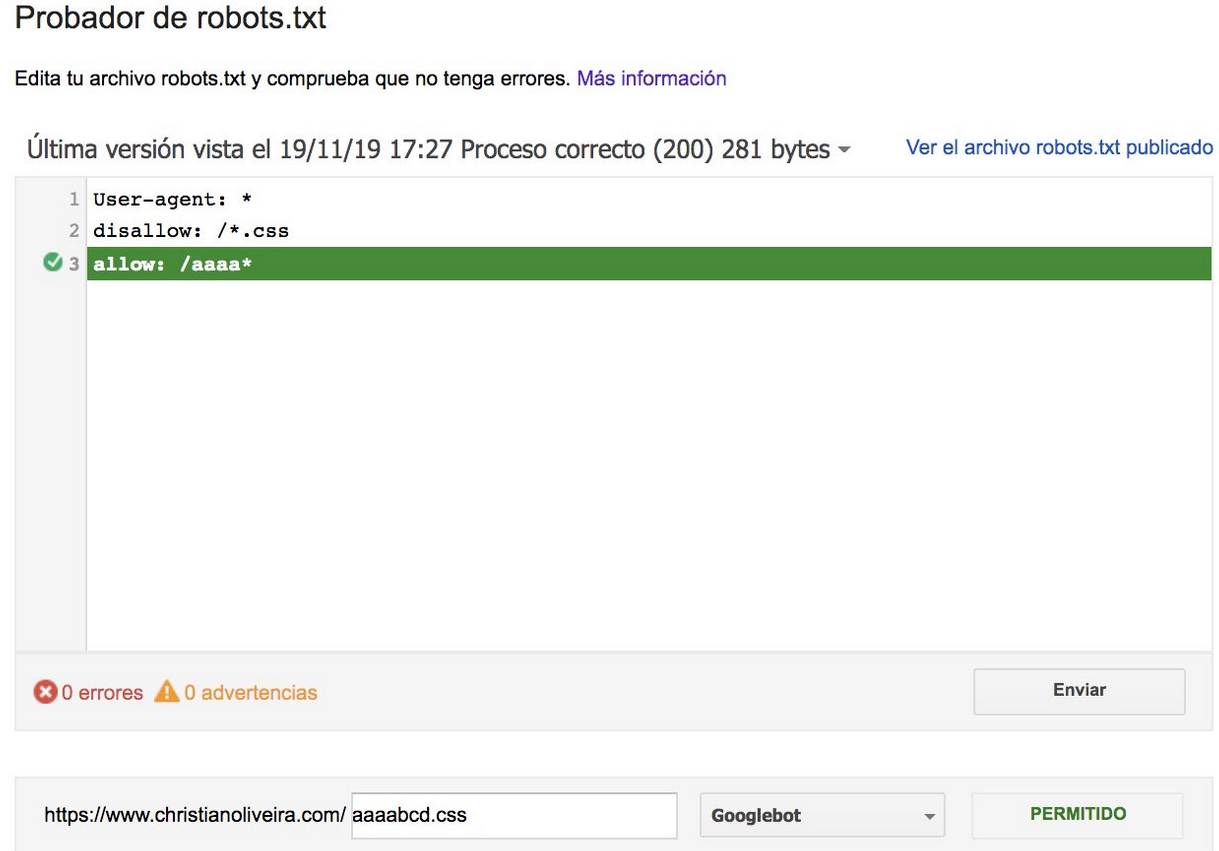
For more examples, please read the robots.txt specifications provided by Google.
Tools for testing your Robots.txt
If you want to test your robots.txt file, there are several tools that can help you and also a couple of github repositories if you want to make your own:
- Distilled
- Google has left the robots.txt tester tool from the old Google Search Console here
- On Python
- On C++
Sample Results: effective use of a Robots.txt for ecommerce
Below I’ve included a case where we were working with a Magento site that didn’t have a robots.txt file. Magento as well as other CMS have admin pages and directories with files that we don’t want Google to crawl. Below, we’ve included an example of some of the directories that we included in the robots.txt:
# # General Magento directories Disallow: / app / Disallow: / downloader / Disallow: / errors / Disallow: / includes / Disallow: / lib / Disallow: / pkginfo / Disallow: / shell / Disallow: / var / # # Do not index the search page and non-optimized link categories Disallow: /catalog/product_compare/ Disallow: /catalog/category/view/ Disallow: /catalog/product/view/ Disallow: /catalog/product/gallery/ Disallow: /catalogsearch/
The huge amount of pages that were not meant to be crawled was affecting their crawl budget and Googlebot wasn’t getting to crawl all of the product pages on the site.
You can see on the image below how indexed pages increased after October 25, which was when the robots.txt was implemented:
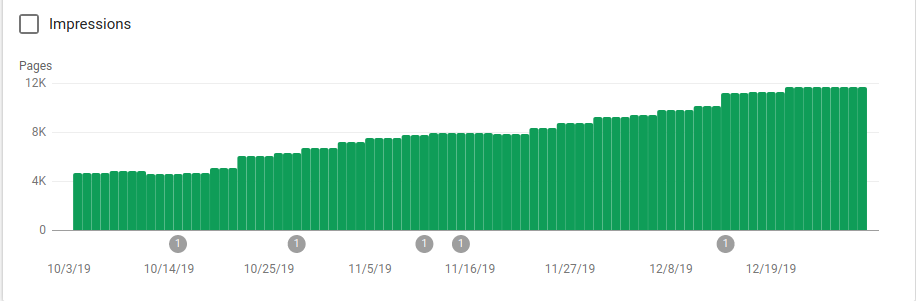
Besides blocking several directories that were not meant to be crawled the robots included a link to the sitemaps. On the screenshot below you can see how the number of indexed pages increased in comparison with the excluded pages:
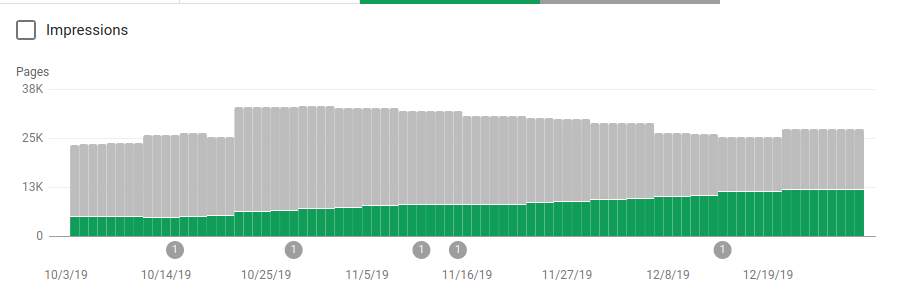
There is a positive trend on indexed valid pages as shown by the green bars and a negative trend on the excluded pages represented by the gray bars.
Wrapping up
The importance of robots.txt can sometimes be underestimated and as you can see from this post there are a lot of details that need to be considered when creating one. But the work pays off: I’ve shown some of the positive results you can obtain from setting up a robots.txt correctly.
