
We recently released our crawl over crawl feature. This feature lets you compare two different crawls and stresses out crawl evolutions and SEO improvements.
We think this tool is really valuable for SEO experts as it can really ease your workflow. Separated between business expertises, you can thus automatically follow the evolution of your site – crawl after crawl, check improvements after a SEO audit or simply quickly detect issues comparing two crawls.
In this article, we will give you 10 use cases of how you could use our Crawl over Crawl feature to improve your SEO.
10 use cases using the Crawl over Crawl
If you have not read our guide about how to read a sunburst, it’s still time to catch up.
1# Check evolutions in terms of indexation
The crawl over crawl lets you compare indexability between two different crawls:
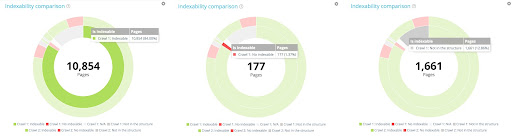
In this example, the first crawl contains 10 854 indexable pages and 177 no indexable pages. 1 661 pages have only been found in the second crawl.
Now have a look at the outside circle. For each segment of the first circle, we find the distribution of these pages in the second crawl.
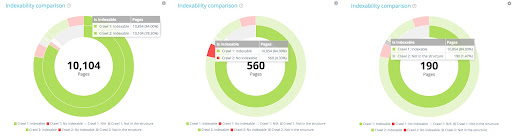 Within the 10 854 indexable pages in the first crawl, only 10 104 are still indexable in the second one, 560 are now non indexable in the second one and 190 are not in the second crawl anymore.
Within the 10 854 indexable pages in the first crawl, only 10 104 are still indexable in the second one, 560 are now non indexable in the second one and 190 are not in the second crawl anymore.
This is convenient to easily detect indexability movements between two crawls. Did you expect that result? If not, you now have the right data to take action. You can also click on any parts of the graph to identify the concerned URLs and export them in CSV:

 2# Get a clear view of depth movements
2# Get a clear view of depth movements
Also, you can analyze how your page depth has evolved crawl over crawl. In the graph below, you can see depth movements:

For example, if we look at depth 5, we can see pages that are gone to shallower or deeper depth or pages that come from shallower or deeper depth between crawl 1 and 2. Here, 264 pages that were in crawl 1 and in depth 5 have gone to a shallower depth (depth 4, 3 or 2).
If you are optimizing your internal linking, this is an interesting data to have in mind to check page’s movements.
3# Detect missing pages between two crawls
Crawl comparisons can also help you spot possible orphan pages. Let’s say you have a website with 500 pages. Looking at the Search Console you know that Google has indexed 390 pages. If I delete 250 pages from the structure after crawl 1, I can’t know if these 250 pages were part of the 390 pages known by Google.
In crawl 2, pages that were indexed in crawl 1 by Google but that are not in the structure anymore are going to be crawled in crawl 2 and seen as orphans.
4# Monitor the quality of editorial restructuration
Crawl comparison can also help you check if your editorial strategy is taking the right way. Let’s say you have detected too many pages with thin content and you have started to enrich those pages. With crawl comparison, you can monitor if all those pages have been optimized, if some still needs improvements or if you have forgotten some pages. It can help you adapt your plans. The same goes for main tags. You can analyze their quality crawl after crawl.
5# Monitor duplicate content removal
Internal duplicate content is really a pain and you need to be able to check if your content optimization has been done well. With the crawl over crawl, you can monitor your process and easily compare crawl 1 and crawl 2.
In the screenshot below, you can measure the gap between the first and the second crawl. In that case, there is a 61% decrease of duplicate content:
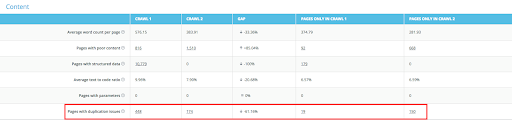 Same here, you can clearly identify your duplicate content ratio and evaluate the efforts remaining:
Same here, you can clearly identify your duplicate content ratio and evaluate the efforts remaining:

If we now focus on duplicate content comparison between crawl 1 and crawl 2, we can access further informations regarding pages with no duplicate, canonical matching or not and pages not in the structure:

Let’s now focus on canonicals not matching in crawl 1:

Within the 31 296 pages with canonical not matching in crawl 1, 2923 have no duplication issues in crawl 2:

25 684 pages still have no canonical matching in crawl 2:

And 2 687 pages have been removed from the structure:

You can now understand why pages have become duplicated on the second crawl or how they have been fixed:

 6# Monitor load time improvements
6# Monitor load time improvements
If you face load time difficulties, it is good to be able to have a quick view of what still needs to be improved.

In that case, I have only selected too slow pages from crawl 1. In crawl 2, we can see that there are only 42 pages that have been well optimized and take less than 500 ms to load.
For e-commerce websites, load time have a huge impact on conversions and sales. Pages that take more than 3 seconds to load face high bounce rate.
7# Check if new redirections are behaving the right way
Imagine you have 200 pages that you want to remove, you can choose to write regex to make redirections on those pages. With crawl comparisons, you can check that pages that have been redirected are the right ones. Sometimes, it can happen that regex redirect more pages than expected.
On the other hand, if you have 3xx or 4xx pages that you want to move in 200 you can have a first idea of the page’s volume through our Data Explorer and get an exhaustive list of the concerned pages.
8# Check if you have new 4xx status codes or new 200 pages
It is also interesting to understand if between two SEO optimizations you have generated 4xx errors not in purpose. With the crawl over crawl, you can clearly identify those kind of pages. You can also verify that pages that were in 404 in the first crawl have been well fixed and are now returning a 200 status code.
9# Analyze how your internal linking and your Inrank are behaving
Currently optimizing your internal linking? You can check your follow inlinks evolution between crawl 1and crawl 2. Again, you can click on the chart to see which pages have gained or loose inlinks.

You can also check which pages receive the more inlinks:
 But if you need to analyze how your internal linking optimization behaves, you can have a look at the Inrank evolution. It scores your page’s popularity using a 0 to 10 scale.
But if you need to analyze how your internal linking optimization behaves, you can have a look at the Inrank evolution. It scores your page’s popularity using a 0 to 10 scale.

In this example, the Inrank has slightly increased on pages at depth 6. Was it done in purpose? You can also see that the majority of the pages are located at depth 4. Should you optimize the internal popularity of these pages compared to shallower ones? These data can help you manage your internal linking strategy.
10# Get an overview of all newly created pages between 2 crawls
You can also identify pages that were not in the first crawl but appear in the second one. Those pages can be either indexable or not indexable. In the screenshot below, 262 pages that did not exist in the first crawl have been created in the second one and are indexable:

Do you have questions regarding our Crawl over Crawl feature? We would love to get your feedbacks, so don’t hesitate to drop us a line @Oncrawl_CS.
