One of the advantages of Oncrawl for enterprise SEO is having full access to your raw data. Whether you’re connecting your SEO data to a BI or a data science workflow, carrying out your own analyses, or working within the data security guidelines for your organization, raw SEO and website audit data can serve many purposes.
Today we’ll look at how to use Oncrawl data to answer complex data questions.
What is a complex data question?
Complex data questions are questions that can’t be answered by a simple database look up, but require data processing in order to obtain the answer.
Here are a few common examples of “complex” data questions that SEOs often have:
- Creating a list of all links pointing to pages that redirect to other pages with a 404 status
- Creating a list of all links and their anchor text pointing to pages in a segmentation based on non-URL metrics
How to answer complex data questions in Oncrawl
Oncrawl’s data structure is built to allow almost all sites to look up data in near real time. This involves storing different types of data in different datasets in order to ensure that the look-up times are kept to a minimum in the interface. For example, we store all data associated with URLs in one dataset: response code, number of outgoing links, type of structured data present, number of words, number of organic visits… And we store all data related to links in a separate dataset: link target, link origin, anchor text…
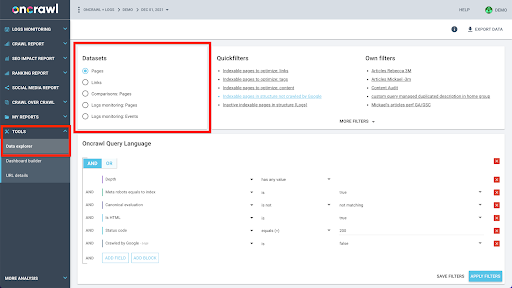
Joining these datasets is computationally complex, and not always supported in the interface of the Oncrawl application. When you’re interested in looking something up that requires filtering one dataset in order to look something up in another, we recommend manipulating the raw data on your own.
Since all Oncrawl data is available to you, there are many ways to join datasets and express complex queries.
In this article, we’ll look at one of them, using Google Cloud and BigQuery, which is appropriate for very large datasets like many of our clients encounter when examining data for sites with high-volumes of pages.
What you’ll need
To follow the method we’ll discuss in this article, you’ll need access to the following tools:
- Oncrawl
- Oncrawl’s API with the Big Data Export
- Google Cloud Storage
- BigQuery
- A Python script to transfer data from Oncrawl to BigQuery (We’ll be building this during the article.)
Before you start, you’ll need to have access to a completed crawl report in Oncrawl.
How to leverage Oncrawl data in Google BigQuery
The plan for today’s article is as follows:
- First, we’ll make sure that Google Cloud Storage is set up to receive data from Oncrawl.
- Next, we will use a Python script to run Oncrawl’s Big Data exports to export the data from a given crawl to a Google Cloud Storage bucket. We’ll export two datasets: pages and links.
- When this is done, we will be creating a dataset in Google BigQuery. We will then create a table from each of the two exports within the BigQuery dataset.
- Finally, we will be experimenting with querying the individual datasets, and then both datasets together to find the answer to a complex question.
Setting up within Google Cloud to receive Oncrawl data
To run this guide in a dedicated, sandbox environment, we recommend you to create a new Google Cloud project to isolate that from your existing ongoing projects.
Let’s start at the home of Google Cloud.
From your Google Cloud homepage, you have access to many things in addition to the Cloud Storage. We’re interested in the Cloud Storage buckets, which are available within the cloud storage tier of Google Cloud Platform:
You can also reach the Cloud Storage browser directly at https://console.cloud.google.com/storage/browser.
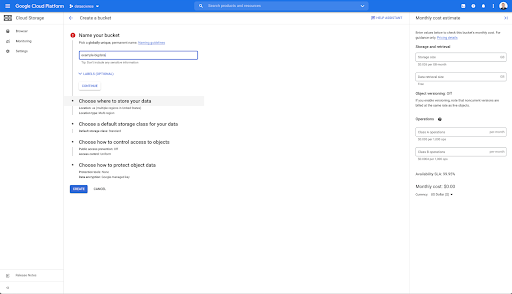
You then need to create a Cloud Storage bucket, and to grant the correct permissions so that Oncrawl’s Service Account is allowed to write into it, under the prefix of your choice.
The Google Cloud Storage bucket will serve as a temporary storage to hold the Big Data exports from Oncrawl prior to loading them into Google BigQuery.
In this bucket, I’ve also created two folders: “links” and “pages”:
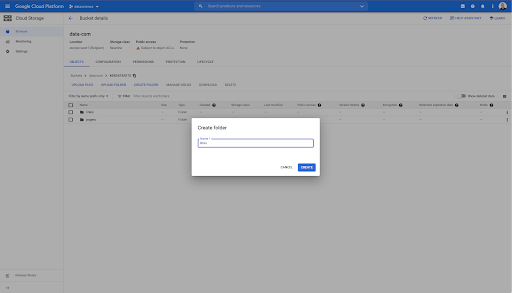
Exporting Datasets from Oncrawl
Now that we have set up the space where we want to save the data, we need to export it from Oncrawl. Exporting to a Google Cloud Storage bucket with Oncrawl is particularly easy, since we can export data in the right format, and save it directly to the bucket. This eliminates any extra steps.
Creating an API key
Exporting data from Oncrawl in the Parquet format for BigQuery will require the use of an API key to act on the API programmatically, on behalf of the owner of the Oncrawl account. Oncrawl application allows users to create named API keys so that your account is always well organized and clean. API keys are also associated with different permissions (scopes) so that you can manage the keys and their purposes.
Let’s name our new key ‘Knowledge session key’. The Big Data export feature requires write permissions in the account, because we are creating the data exports. To perform this, we need to have read access on the project and read and write access on the account.
Now we have a new API key, which I will copy to my clipboard.
Note that, for security reasons, you have the ability to copy the key only once. If you forget to copy the key, you will need to delete the key and create a new one.
Creating your Python script
I built a Google Colab notebook for this, but I’ll be sharing the code below so that you can create your own tools or your own notebook.
1. Store your API key in a global variable
First, we bootstrap the environment and we declare the API key in a global variable named “Oncrawl Token”. Then, we prepare for the rest of the experiment:
#@title Access the Oncrawl API
#@markdown Provide your API token below to allow this notebook to access your Oncrawl data:
# YOUR TOKEN FOR ONCRAWL API
ONCRAWL_TOKEN = "" #@param {type:"string"}
!pip install prison
from IPython.display import clear_output
clear_output()
print('All loaded.')
2. Create a drop down list to choose the Oncrawl project you want to work with
Then, using that key, we want to be able to pick the project we want to play with by getting the list of the projects and creating a drop down widget out of that list. By running the second code block, carry out the following steps:
- We will call the Oncrawl API to get the list of the projects on the account using the API key that was just submitted.
- Once we have the list of the project from the API response, we format it as a list using the name of the project as well as the start URL of the project.
- We store the ID of the project that was provided in the response.
- We build a drop down menu and show it below the code block.
#@title Select the website to analyze by choosing the corresponding Oncrawl project
import requests
import prison
import ipywidgets as widgets
import json
# Get list of projects
response = requests.get("https://app.oncrawl.com/api/v2/projects?limit={limit}&sort={sort}".format(
limit=1000,
sort='name:asc'
),
headers={ 'Authorization': 'Bearer '+ONCRAWL_TOKEN }
)
json_res = response.json()
#prepare dropdown to let user select a project
projects = []
for item in json_res['projects']:
projects.append(('{} - {}'.format(item['name'], item['start_url']), item['id']))
output = widgets.Output()
dropdown_purpose = widgets.Dropdown(options = projects, description="Project: ")
def dropdown_project_eventhandler(change):
output.clear_output()
with output:
display(projects)
dropdown_purpose.observe(dropdown_project_eventhandler, names='value')
display(dropdown_purpose)From the drop down menu that this creates, you can see the complete list of the project that the API key has access to.
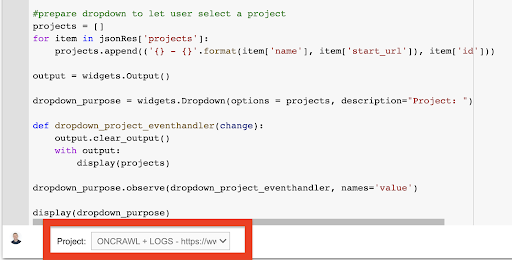
For the purpose of the demonstration today, we’re using a demo project based on the Oncrawl website.
3. Create a drop down list to choose the crawl profile within the project that you want to work with
Next, we will decide which crawl profile to use. We want to choose a crawl profile within this project. The demo project has a lot of different crawl configurations:
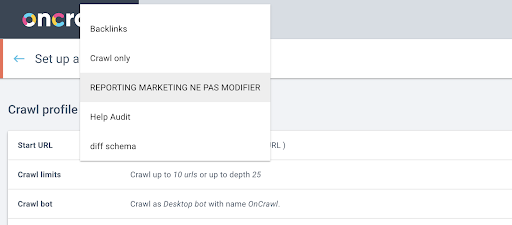
In this case, we’re looking at a project that the Oncrawl teams often use for experiments, so I’m going to choose the crawl profile used by the marketing team to monitor the performance of the Oncrawl website. Since this is supposed to be the most stable crawl profile, it’s a good choice for the experiment today.
To get the crawl profile, we’ll use the Oncrawl API, to ask for the last crawl within every single crawl profile in the project:
- We prepare to query the Oncrawl API for the given project.
- We’ll ask for all the crawls returned by descending order according to their “created at” date.
import requests
import json
import ipywidgets as widgets
project_id = dropdown_purpose.value
# Get projects details (include all the crawls in the project)
project = requests.get("https://app.oncrawl.com/api/v2/projects/{}".format(project_id),
params=dict(include_nested_resources=True, sort="created_at:desc"),
headers={ 'Authorization': 'Bearer '+ONCRAWL_TOKEN }).json()
# Group crawls by crawl profile (crawl name)
crawls_by_config = {}
try:
for crawl in project['crawls']:
if crawl['status'] in ["done"]:
if crawl['crawl_config']['name'] not in crawls_by_config.keys():
crawls_by_config[crawl['crawl_config']['name']] = {'crawl_ids' : [], 'is_crawl_archived' : False}
if len(crawls_by_config[crawl['crawl_config']['name']]['crawl_ids']) == 0:
crawls_by_config[crawl['crawl_config']['name']]['crawl_ids'].append(crawl['id'])
if crawl['status'] == "archived":
crawls_by_config[crawl['crawl_config']['name']]['is_crawl_archived'] = True
except Exception as e:
raise Exception("error {} , {}".format(e, project))
# Build the list for the dropdown select
list = [("{} ({})".format(k, len(v['crawl_ids'])), k) for k, v in crawls_by_config.items()]
dropdown_crawl_configs = widgets.Dropdown(options = list, description="Crawl configs: ")
def dropdown_cc_eventhandler(change):
output.clear_output()
with output:
display(crawls_by_config)
if len(crawls_by_config.values()) == 0:
print('No live crawl found in this project')
dropdown_crawl_configs.observe(dropdown_cc_eventhandler, names='value')
display(dropdown_crawl_configs)When this code is run, the Oncrawl API will respond to us with the list of the crawls by descending “created at” property.
Then, since we only want to focus on crawls that are finished, we will go through the list of the crawls. For every single crawl with a status of “done”, we will save the name of the crawl profile and we will store the crawl ID.
We will keep at most one crawl by crawl profile so that we don’t want to expose too many crawls.
The result is this new drop down menu created from the list of crawl profiles in the project. We’ll choose the one we want. This will take the last crawl run by the marketing team:
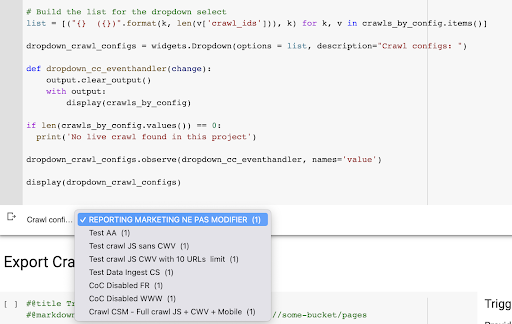
4. Identify the last crawl with the profile we want to use
We already have the crawl ID associated with the last crawl in the chosen profile. It’s hidden in the “crawl_by_config” object dictionary.
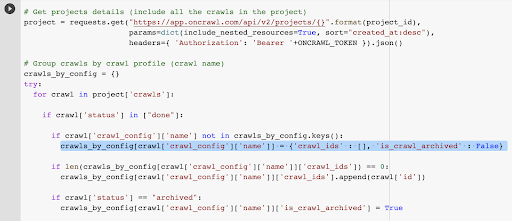
You can check this easily in the interface: Find the last completed crawl in this profile analysis.
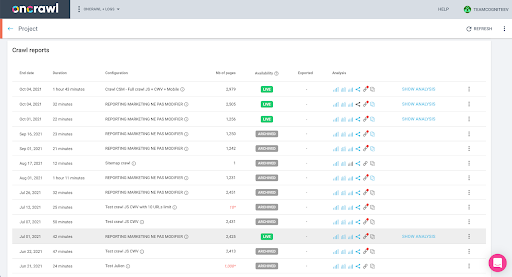
If we click to view the analysis, we will see that the crawl ID ends with E617.
Let’s just take note of the crawl ID for the purpose of the demonstration today.
Of course, if you already know what you are doing, you can skip the steps we just covered to call the Oncrawl API in order to get the list of projects and the list of crawls by crawl profile: you already have the crawl ID from the interface, and this ID is all you need to run the export.
The steps that we have run through so far are simply to ease the process of obtaining the last crawl of the given crawl profile of the given project, given what the API key has access to. This can be useful if you’re providing this solution to other users, or if you’re looking to automate it.
5. Export crawl results
Now, we will look at the export command:
#@title Trigger bigdata export
#@markdown Provide your GCS Bucket and prefix gs://some-bucket/pages
# YOUR GCS BUCKET
gcs_bucket = #@param {type:"string"}
gcs_prefix = #@param {type:"string"}
# Get last crawl ID from given project / crawl profile
list_crawl_ids = crawls_by_config[dropdown_crawl_configs.value]['crawl_ids']
last_crawl_id = list_crawl_ids[0]
# Template payload for data export query
payload = {
"data_export": {
"data_type": 'page',
"resource_id": last_crawl_id,
"output_format": 'parquet',
"target": 'gcs',
"target_parameters": {
"gcs_bucket": gcs_bucket,
"gcs_prefix": gcs_prefix
}
}
}
# Trigger export
export = requests.post("https://app.oncrawl.com/api/v2/account/data_exports", json=payload, headers={ 'Authorization': 'Bearer '+ONCRAWL_TOKEN }).json()
# Display API response
display(export)
# Store export ID for future usage
export_id = export['data_export']['id']We want to export into the Cloud Storage bucket we set up earlier.
Within that we are going to export the pages for the last crawl ID:
- The last crawl ID is obtained from the list of crawl IDs, which is stored somewhere in the “crawls_by_config” dictionary, which was created in step 3.
- We want to choose the one corresponding to the drop down menu in step 4, so we use the value attribute of the drop down menu.
- Then, we extract the crawl_ID attribute. This is a list. We’ll keep the top 50 items in the list. We need to do this because in step 2, as you’ll remember, when we created the crawls_by_config dictionary, we only stored one crawl ID per configuration name.
I set up input fields to make it easy to provide the Google Cloud Storage bucket and prefix, or folder, where we want to send the export.

For the purpose of the demonstration, today, we will be writing to the “mixed dataset” folder, in one of the folders that I already set up. When we set up our bucket in Google Cloud Storage, you’ll remember that I prepared folders for the “links” export and for the “pages” export.
For the first export, we will want to export the pages into the “pages” folder for the last crawl ID using the Parquet file format.

In the results below, you’ll see the payload that is to be sent to the data export endpoint, which is the endpoint to request a Big Data export using an API key:
# Template payload for data export query
payload = {
"data_export": {
"data_type": 'page',
"resource_id": last_crawl_id,
"output_format": 'parquet',
"target": 'gcs',
"target_parameters": {
"gcs_bucket": gcs_bucket,
"gcs_prefix": gcs_prefix
}
}
}
This contains several elements, including the type of the data set you want to export. You can export the page dataset, the link dataset, the clusters dataset, or the structured data dataset. If you don’t know what can be done, you can enter an error here, and when you call the API you will get a message stating that the choice for data type must be either page or link or cluster or structured data. The message looks like this:
{'fields': [{'message': 'Not a valid choice. Must be one of "page", "link", "cluster", "structured_data".',
'name': 'data_type',
'type': 'invalid_choice'}],
'type': 'invalid_request_parameters'}
For the purpose of the experiment today, we will be exporting the page dataset and the link dataset in separated exports.
Let’s start with the page dataset. When I run this code block, I’ve printed the output of the API call, which looks like this:
{'data_export': {'data_type': 'page',
'export_failure_reason': None,
'id': 'XXXXXXXXXXXXXX',
'output_format': 'parquet',
'output_format_parameters': None,
'output_row_count': None,
'output_size_in_bytes: 1634460016000,
'resource_id': '60dd4c2b34d08a0f10a5e617',
'status': 'REQUESTED',
'target': 'gcs',
'target_parameters': {'gcs_bucket': 'data-cms',
'gcs_prefix': 'MIXDATASETS/pages/'}}}
This allows me to see that the export was requested.
If we want to check on the status of the export, it’s very simple. Using the export ID that we saved at the end of this code block, we can request the status of the export at any time with the following API call:
# STATUS OF EXPORT
export_status = requests.get("https://app.oncrawl.com/api/v2/account/data_exports/{}".format(export_id), headers={ 'Authorization': 'Bearer '+ONCRAWL_TOKEN }).json()
display(export_status)
This will indicate a status as part of the returned JSON object:
{'data_export': {'data_type': 'page',
'export_failure_reason': None,
'id': 'XXXXXXXXXXXXXX',
'output_format': 'parquet',
'output_format_parameters': None,
'output_row_count': None,
'output_size_in_bytes': None,
'requested_at': 1638350549000,
'resource_id': '60dd4c2b34d08a0f10a5e617',
'status': 'EXPORTING',
'target': 'gcs',
'target_parameters': {'gcs_bucket': 'data-csm',
'gcs_prefix': 'MIXDATASETS/pages/'}}}When the export is complete ('status': 'DONE'), we can return to Google Cloud Storage.
If we look in our bucket, and we go into the “links” folder, there isn’t anything here yet because we exported the pages.
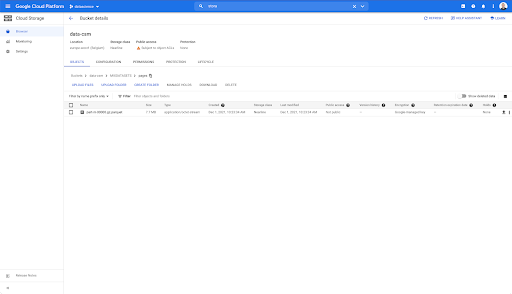
However, when we look in the “pages” folder, we can see that the export has succeeded. We have a Parquet file:
At this stage, the pages dataset is ready for import in BigQuery, but first we’ll repeat the steps above to obtain the Parquet file for the links:
- Make sure to set the links prefix.
- Choose the “link” data type.
- Run this code block again to request the second export.

This will produce a Parquet file in the “links” folder.
Creating BigQuery datasets
While the export is running, we can move forward and start creating datasets in BigQuery and import the Parquet files into separate tables. Then we will be joining the tables together.
What we want to do now is to play with Google Big Query, which is something available as part of the Google Cloud Platform. You can use the search bar at the top of the screen, or go directly to https://console.cloud.google.com/bigquery.
Creating a dataset for your work
We’ll need to create a dataset within Google BigQuery:
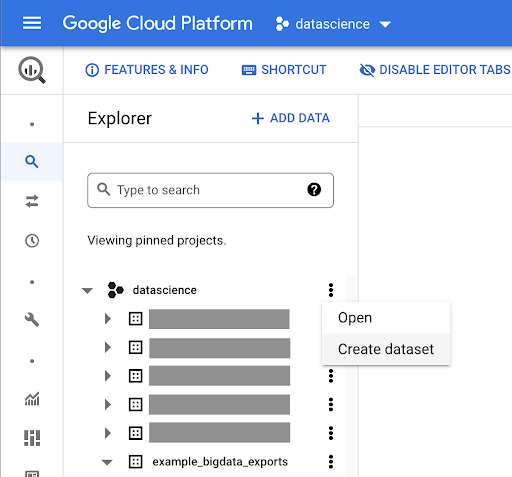
You’ll need to provide the dataset with a name, and choose the location where the data will be stored. This is important because it will condition where the data is processed, and cannot be changed. This can have an impact if your data includes information that is covered by the GDPR or other privacy laws.
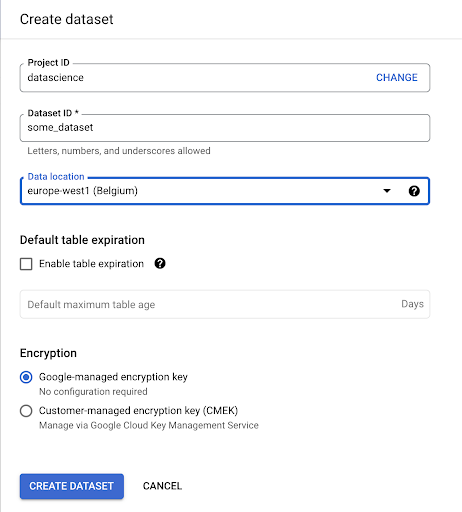
This dataset is initially empty. When you open it, you will be able to create a table, share the dataset, copy, delete, and so on.
Creating tables for your data
We’ll create a table in this dataset.
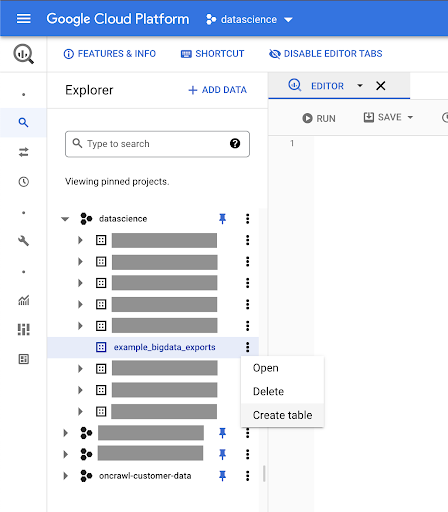
You can either create an empty table and then provide the schema. The schema is the definition of the columns in the table. You can either define your own, or you can browse Google Cloud Storage to choose a schema from a file.
We’ll use this last option. We’ll navigate to our bucket, then to the “pages” folder. Let’s choose the pages file. There is only one file, so we can select only one, but if the export had generated several files, we could have chosen all of them.
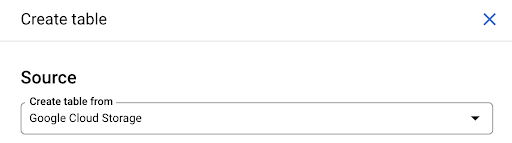
When we select the file, it automatically detects that it is in Parquet file format. We want to create a table named “pages”, and the schema will be defined by the source file.

When we load a Parquet file, it embeds a schema. In other words, the definition of the columns of the table we are creating will be inferred from the schema that already exists within the Parquet file. This is where actually a part of the magic happens.
Let’s just move forward and simply create the table from the Parquet file.
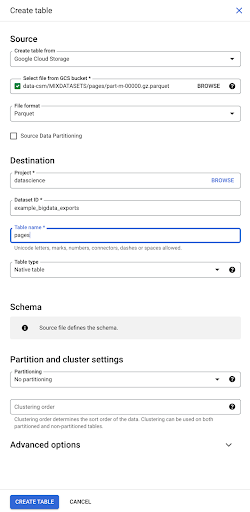
In the left-hand sidebar, we can see now that a table appeared within our dataset, which is exactly what we want:
So, we now have the schema of the pages table with all the fields that have been automatically inferred from the Parquet file. We have the Inrank, the depth of the page, if the page is a redirect and so on and so forth:
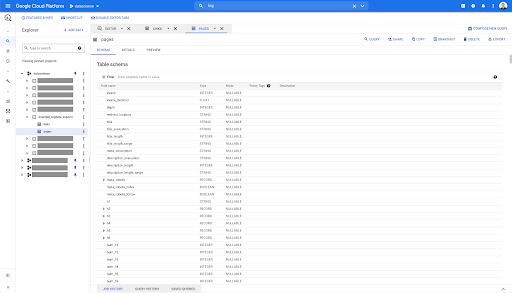
Most of these fields are the same as the ones made available within Data Studio through the Oncrawl Data Studio connector, and the same as the ones you see in the Data Explorer in the Oncrawl interface.
However, there are some differences. When we play with raw big data export, you have all the raw data.
- In Data Studio, some fields are renamed, some fields are hidden, and some fields are added, such as the status.
- In the Data Explorer, some fields are what we call “virtual fields”, which means that they may be a sort of shortcut to an underlying field. These virtual fields available in the Data Explorer will not be listed in the schema, but they can be re-created based on what is available in the Parquet file.
Let’s now close this table and do it again for the links.
For the links table, the schema is a bit smaller.
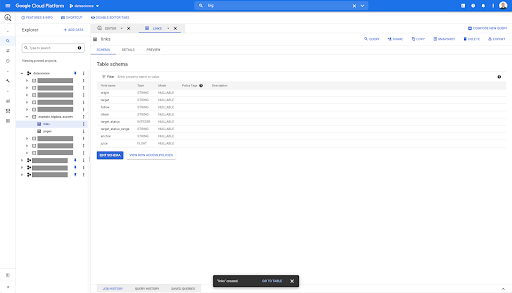
It only contains the following fields:
- The origin of the link,
- The target of the link,
- The follow property,
- The internal property,
- The target status,
- The range of the target status,
- The anchor text, and
- The juice or equity bought by the link.
On any table in BigQuery, when you click on the preview tab, you have a preview of the table without querying the database:
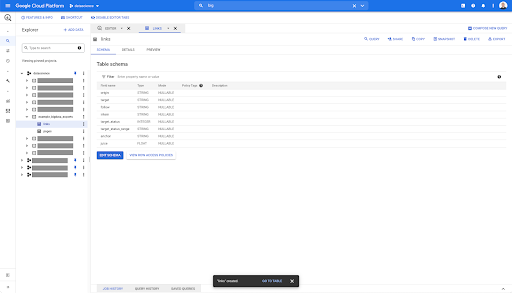
This gives you a quick view of what’s available in it. In the preview for the links table above, you have a preview of every single row and all the columns.
In some Oncrawl datasets, you may see some rows that span several rows. I don’t have an example for you, but if this is the case, it’s because some fields contain a list of values. For example, in the list of h2 headings on a page, a single row will span several rows in Big Query. We’ll look at that later on if we see an example.
Creating your query
If you’ve never created a query in BigQuery, now’s the time to play around with that to get familiar with how it works. BigQuery uses SQL to look up data.
How queries work
As an example, let’s look at all the URLs and their inrank…
SELECT url, inrank ...
from the pages dataset…
SELECT url, inrank FROM `datascience-oncrawl.example_bigdata_exports.pages` ...
where the page’s status code is 200…
SELECT url, inrank FROM `datascience-oncrawl.example_bigdata_exports.pages` WHERE status_code = 200 ...
and only keep the first 10 results:
SELECT url, inrank FROM `datascience-oncrawl.example_bigdata_exports.pages` WHERE status_code = 200 LIMIT 10
When we run this query, we will get the first 10 rows of the list of pages where the status code is 200.
Any of these properties can be modified. f I want 1000 rows instead of 10, I can set 1000 rows:
SELECT url, inrank FROM `datascience-oncrawl.example_bigdata_exports.pages` WHERE status_code = 200 LIMIT 1000
If I want to sort, I can do that with “order-by”: this will give me all the rows ordered by descending Inrank order.
SELECT url, inrank FROM `datascience-oncrawl.example_bigdata_exports.links` ORDER BY inrank DESC LIMIT 1000
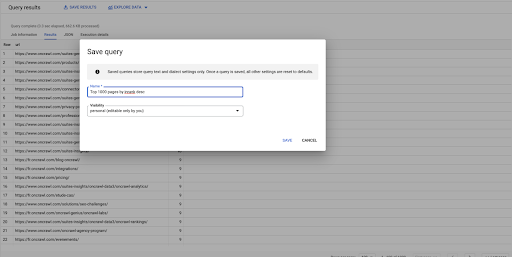
This is my first query. I can save it if I want, which will give me the ability to reuse this query later on if I want:
Using queries to answer simple questions: Listing all internal links to pages with a 301 status
Now that we know how to compose a query, let’s go back to our original problem.
We wanted to answer data questions, whether simple or complex. Let’s start with a simple question, such as “what are all of the internal links that point to pages with a 301 (redirected) status, and where can I find them?”
Creating a new query
We’ll start by exploring how this works.
I’m going to want columns for the following elements from the “links” database:
- Origin
- Target
- Target status code
SELECT origin, target, target_status FROM `datascience-oncrawl.example_bigdata_exports.links`
I want to limit these to internal links only, but let’s imagine that I don’t remember the name of the column or the value that indicates whether the link is internal or external. I can go to the schema to look it up, and use the preview to view the value:
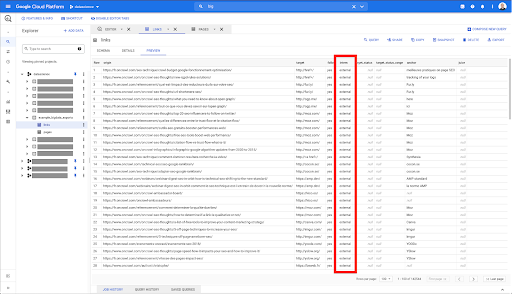
This tells me that the column is named “intern”, and the possible range of values is “external” or “internal”.
In my query, I want to specify “where intern is internal”, and limit the results to the first 100 for now:
SELECT origin, target, target_status FROM `datascience-oncrawl.example_bigdata_exports.links` WHERE intern LIKE 'internal' LIMIT 100
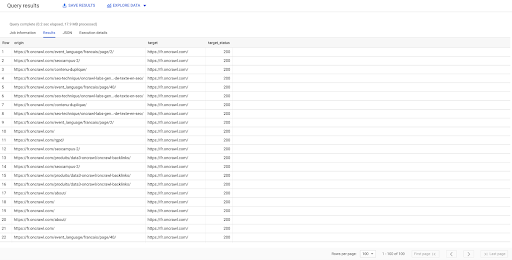
The result above shows the list of links with their target status. We have only internal links, and we have 100 of them, as specified in the query.
If we want to have only internal links to that point to redirected pages, we could say ‘where intern like internal and target status equals 301’:
SELECT origin, target, target_status FROM `datascience-oncrawl.example_bigdata_exports.links` WHERE intern LIKE 'internal' AND target_status = 301
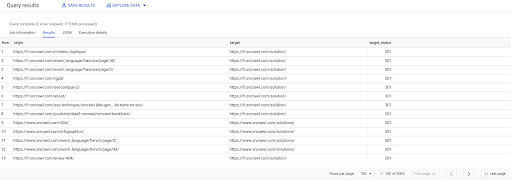
If we don’t know how many of them exist, we can run this new query and we will see that there are 3002 internal links with a target status of 301.
Joining the tables: finding final status codes of links pointing to redirected pages
On a website, you often have links to pages that are redirected. We want to know the status code of the page that they are redirected to (or the final target URL).
In one dataset, you have the information on the links: the origin page, the target page and its status code (like 301), but not the URL that a redirected page points to. And in the other, you have the information on the redirects and their final targets, but not the original page where the link to them was found.
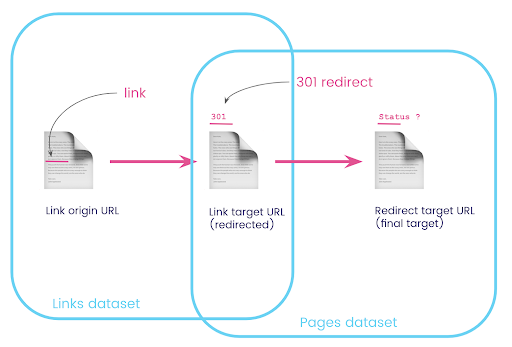
Let’s break this down:
First, we want links to redirects. Let’s write this down. We want:
- The origin.
- The target. The target must have a 301 status code.
- The final target of the redirect.
In other words, in the links dataset, we want:
- The origin of the link
- The target of the link
In the pages dataset, we want:
- All the targets that are redirected
- The final target of the redirect
This will give us a query like:
SELECT url, final_redirect_location, final_redirect_status FROM `datascience-oncrawl.example_bigdata_exports.pages` AS pages WHERE status_code = 301 OR status_code = 302
This should give me the first part of the equation.
Now I need all the links linking to the page that are the results of the query I just created, using aliases for my datasets, and joining them on the link target URL and the page URL. This corresponds to the overlapping area of the two datasets in the diagram at the beginning of this section.
SELECT links.origin, pages.url, pages.final_redirect_location, pages.final_redirect_status FROM `datascience-oncrawl.example_bigdata_exports.pages` AS pages JOIN `datascience-oncrawl.example_bigdata_exports.links` AS links ON links.target = pages.url WHERE pages.status_code = 301 OR pages.status_code = 302 ORDER BY origin ASC
In the Query results, I can rename the columns to make things more clear, but I can already see that I have a link from a page in the first column, which goes to the page in the second column, which is in turn redirected to the page in the third column. In the fourth column, I have the status code of the final target:
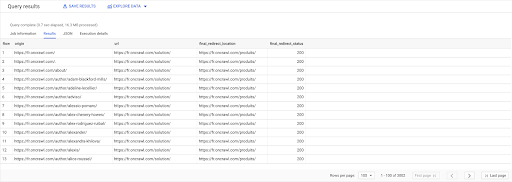
Now I can tell which links point to redirected pages that don’t resolve to 200 pages. Maybe they’re 404s, for example, which gives me a priority list of links to correct.
We saw earlier how to save a query. We can also save the results, for up to 16000 lines of results:
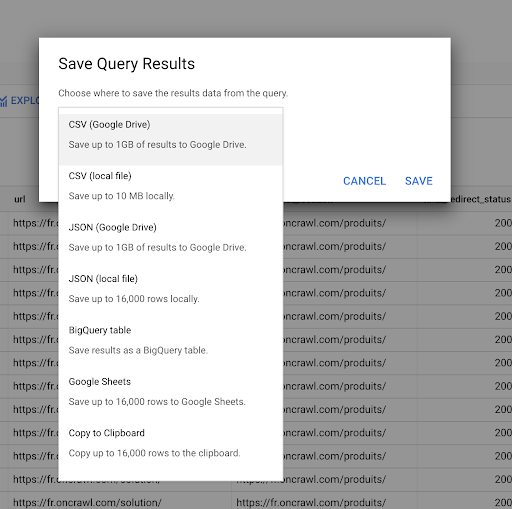
We can then use these results in many different ways. Here are a few examples:
- We can save this as a CSV or JSON file locally.
- We can save it as a Google Sheets spreadsheet and share it with the rest of the team.
- We can also export it directly to Data Studio.
Data as a strategic advantage
With all of these possibilities, using the answers to your complex questions strategically is easy. You may already have experience connecting BigQuery results to Data Studio or other data visualization platforms, or you might already have a process in place that pushes information to an engineering team or even into a business intelligence or data analysis workflow.
If you’ve included the steps in this article as part of a process, remember that you can automate all of the steps in BigQuery: all of the actions we performed in this article are also accessible via the BigQuery API. This means that they can be run programmatically as part of a script or custom tool.
Whatever your next steps, the first step is always access to raw SEO and website data. We believe that this access to data is the one of the most important parts of technical analysis: with Oncrawl, you will always have full access to your raw data.
Access to data also means that you can go beyond what’s possible in the Oncrawl interface, and explore all of the relationships between your data, no matter how complex the questions you’re asking.
