
Let’s learn how to automatically create a breadcrumb-based segmentation with Oncrawl and Python 3.
What is segmentation in Oncrawl?
Oncrawl uses segmentations to split a set of pages into groups. This makes it very easy to analyze data from crawl reports, log analysis and other cross-analysis reports that blend crawl data with Google Analytics, Google Search Console, AT Internet, Adobe Analytics, or Majestic for backlinks.
Why is it important to create segmentations?
Once your crawl is complete, creating a custom segmentation is the most important thing to do. This allows you to read analyses from the perspective that best fits your site and its structure.
There are many ways to segment the pages of your site, and there is no right or wrong way to do it. For example, it is possible to track the structure of your site based on URL structure.
For example, this kind of URL “https://www.mydomain.com/news/canada/politics“, could easily be segmented like this:
- A group to isolate the Homepage
- A group for all the news
- A sub-group for the Canada directory
- A sub-subgroup for the Politics directory
As you can see, it is possible to create up to 3 levels of depth for your segmentations. This allows you to focus on certain groups or sub-groups in your SEO analysis, without having to switch segmentations.
How do I create a basic segmentation?
You should know that Oncrawl takes care of creating the first segmentation, all by itself. This is based on the “First path” or the first directory encountered in the URLs.
This allows you to have an analysis available as soon as your crawl is complete.
It may be that this segmentation does not reflect the structure of your site, or that you want to analyze things from a different angle.
So you’re going to create a new segmentation using what we call OQL, which stands for Oncrawl Query Language. It’s kind of like SQL, only much simpler and more intuitive:
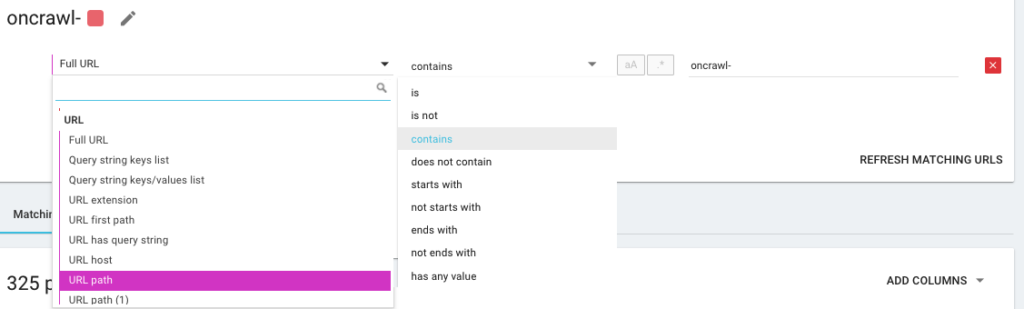
It is also possible to use AND/OR condition operators to be as precise as possible:
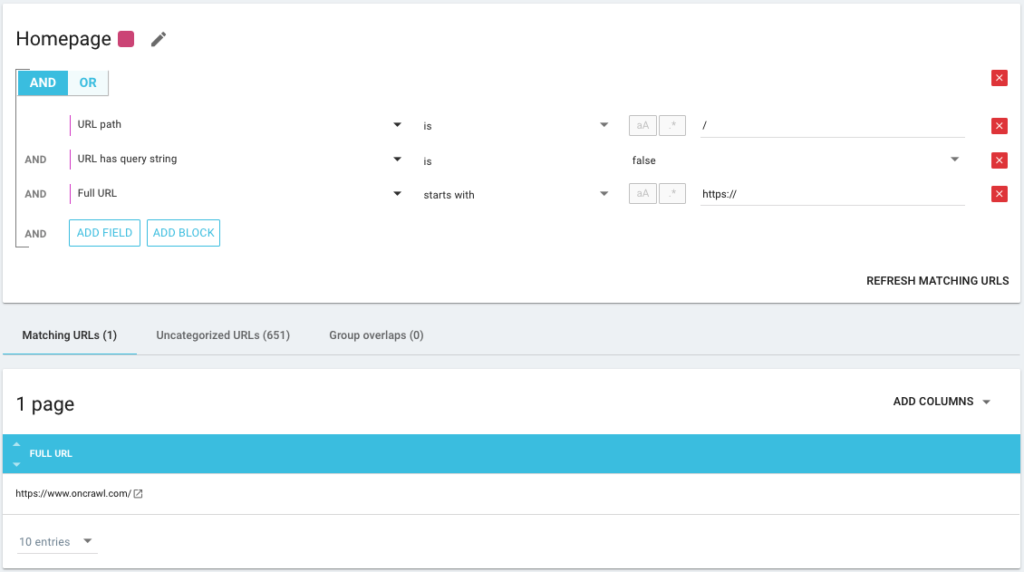
Segmenting my pages using different methods
Using other KPIs
Segmentations based on URLs are good, but it would be perfect if we could also combine other KPIs, such as grouping URLs starting with /car-rental/ and whose H1 has the expression “Car rental agencies” and another group where the H1 would be “Utility rental agencies“, is that possible?
Yes, it’s possible! During the creation of your segmentations, you have at your disposal all the KPIs that we use, and not only those from the crawler, but also ones from connectors. This makes the creation of segmentations very powerful and allows you to have totally different angles of analysis!
For example, I love creating a segmentation using the average position of URLs thanks to the Google Search Console connector.
This way, I can easily identify URLs deep in my structure that are still performing, or URLs close to my home page that are on page 2 of Google.
I can see if these pages have duplicate content, an empty title tag, if they receive enough links… I can also see how the Googlebot behaves on these pages. Is the crawl frequency good or bad? In short, it helps me prioritize and make decisions that will have a real impact on my SEO and my ROI.
Using Data Ingest
If you are not familiar with our Data Ingest feature, I invite you to read this article on the subject first. This is another very powerful tool that allows you to add external data sources to Oncrawl.
For example, you can add data from SEMrush, Ahrefs, Babbar.tech… The advantage is that you can group your pages according to metrics taken from these tools and carry out your analysis based on the data that interests you, even if it is not natively in Oncrawl.
Recently, I worked with a global hotel group. They use an internal scoring method to know if the hotel records are filled out correctly, if they have images, videos, content, etc… They determine a percentage of completion, which we used to cross-analyze the crawl and log file data.
The result allows us to know if Googlebot spends more time on pages that are correctly filled, to know if some pages with a score of more than 90% are too deep, do not receive enough links… It allows us to show that the higher the score, the more visits the pages receive, the more they are explored by Google, and the better their position in the Google SERP. An unstoppable argument to encourage hoteliers to fill out their hotel listing!
Create a segmentation based on the SEO breadcrumb trail
This is the subject of this article so let’s get to the heart of the matter. It is sometimes difficult to segment the pages of your site, if the structure of the URLs do not attach pages to a certain directory. This is often the case with e-commerce sites, where the product pages are all at the root. It is therefore impossible to know from the URL which group a page belongs to.
In order to group pages together, we have to find a way of identifying the group they belong to. We therefore had the idea of retrieving the breadcrumb seo trail of each URL and categorizing them based on the values in the breadcrumbs seo, using the Scraper function offered by Oncrawl.
SEO Breadcrumb Scraping with Oncrawl
As we saw above, we will set up a scraping rule to retrieve the breadcrumb trail. Most of the time it’s pretty simple because we can go and retrieve the information in a div, then the fields of each level are in
ul and li lists:
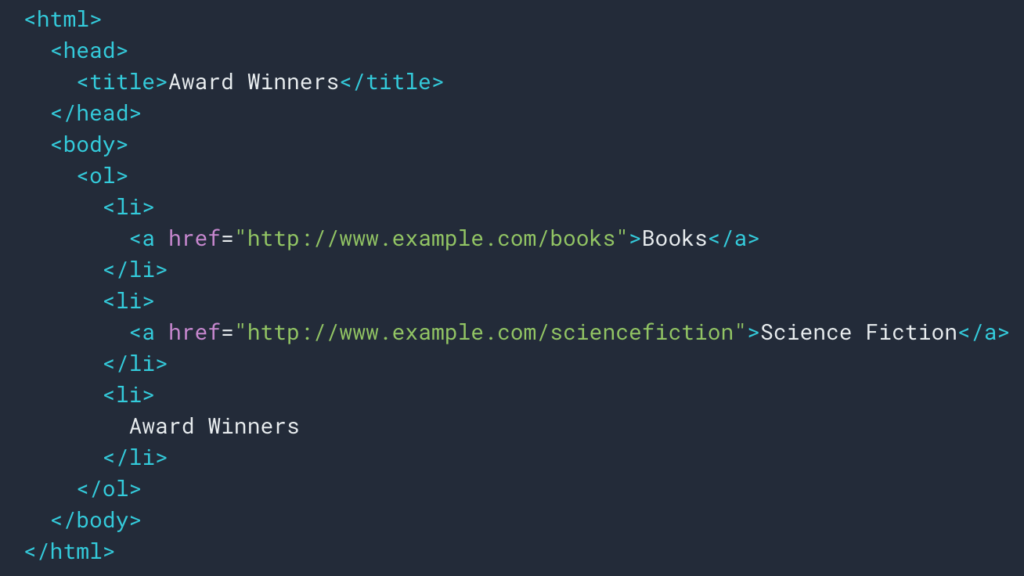
Sometimes also we can easily retrieve the information thanks to structured data type Breadcrumb. So it will be easy to retrieve the value of the “name” field for each position.
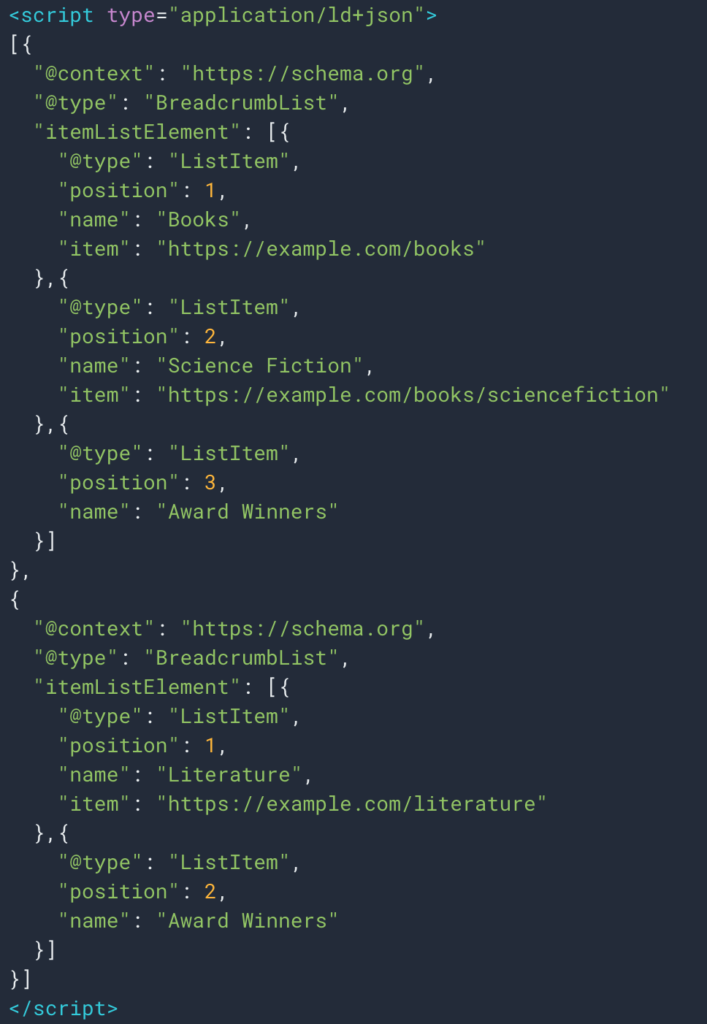
Here is an example of a scraping rule I use:
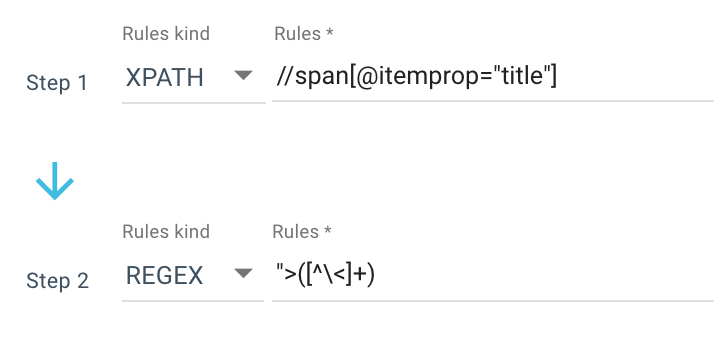
Or this rule: //li[contains(@class, "current-menu-ancestor") or contains(@class, "current-menu-parent") or contains(@class, "current-menu-item")]/a/text()
So I get all the span itemprop=”title” with the Xpath, then use a regular expression to extract everything after “> that is not a > character. If you want to know more about Regex, I suggest you read this article on the subject and our Cheat sheet on Regex.
I get several values like this as the output:
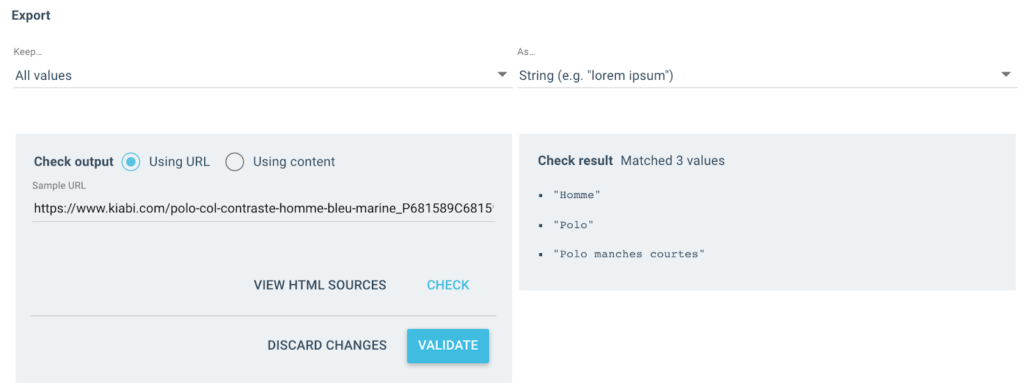
For the tested URL, I will have a “Breadcrumb” field with 3 values:
- Man
- Polo shirt
- Short sleeve polo
import json
import random
import requests
# Authent
# Two ways, with x-oncrawl-token than you can get in request headers from the browser
# or with api token here: https://app.oncrawl.com/account/tokens
API_ACCESS_TOKEN = ' '
# Set the crawl id where there is a breadcrumb custom field
CRAWL_ID = ' '
# Update the forbidden breadcrumb items you don't want to get in segmentation
FORBIDDEN_BREADCRUMB_ITEMS = ('Accueil',)
FORBIDDEN_BREADCRUMB_ITEMS_LIST = [
v.strip()
for v in FORBIDDEN_BREADCRUMB_ITEMS.split(',')
]
def random_color():
random_number = random.randint(0, 16777215)
hex_number = str(hex(random_number))
hex_number = hex_number[2:].ljust(6, '0')
return f'#{hex_number}'
def value_to_group(value):
return {
'color': random_color(),
'name': value,
'oql': {'or': [{'field': ['custom_Breadcrumb', 'equals', value]}]}
}
def walk_dict(dictionary, level=0):
ret = {
"icon": "dashboard",
"transposable": False,
"name": "Breadcrumb"
}Now that the rule is defined, I can launch my crawl and Oncrawl will automatically retrieve the breadcrumb values and associate them with each URL crawled.
Automate the creation of the multi-level segmentation with Python
Now that I have all the SEO breadcrumb values for each URL, we will use a seo automation python script in a Google Colab to automatically create a segmentation compatible with Oncrawl.
For the script itself, we use 3 libraries which are:
- json (To generate our segmentation written in Json)
- csv
- random (To generate hexadecimal color codes for each group)
Once the script is launched, it automatically takes care of creating the segmentation in your project!
Data preview in the analyses
Now that our segmentation is created, it is possible to have access to the different analyses with a segmented view based on my breadcrumb trail.
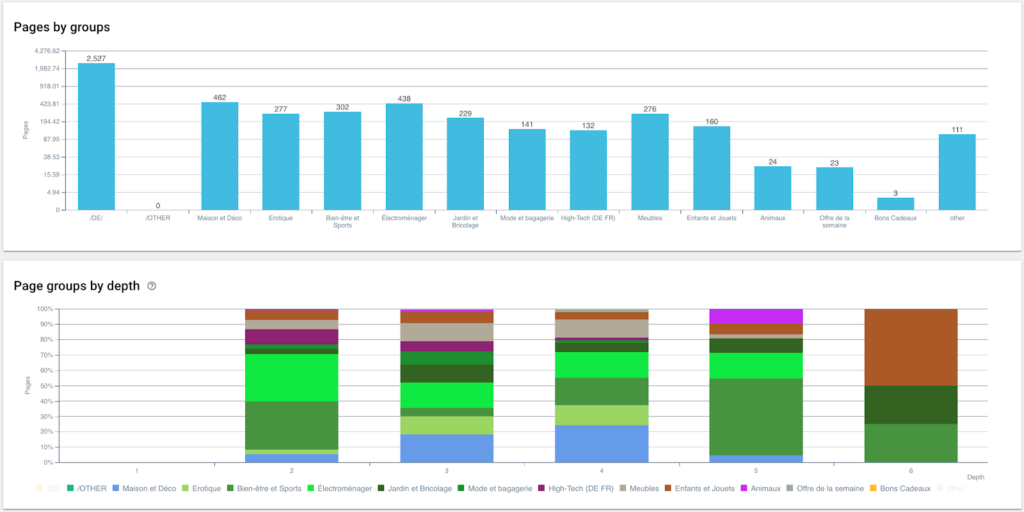
Distribution of pages by group and by depth
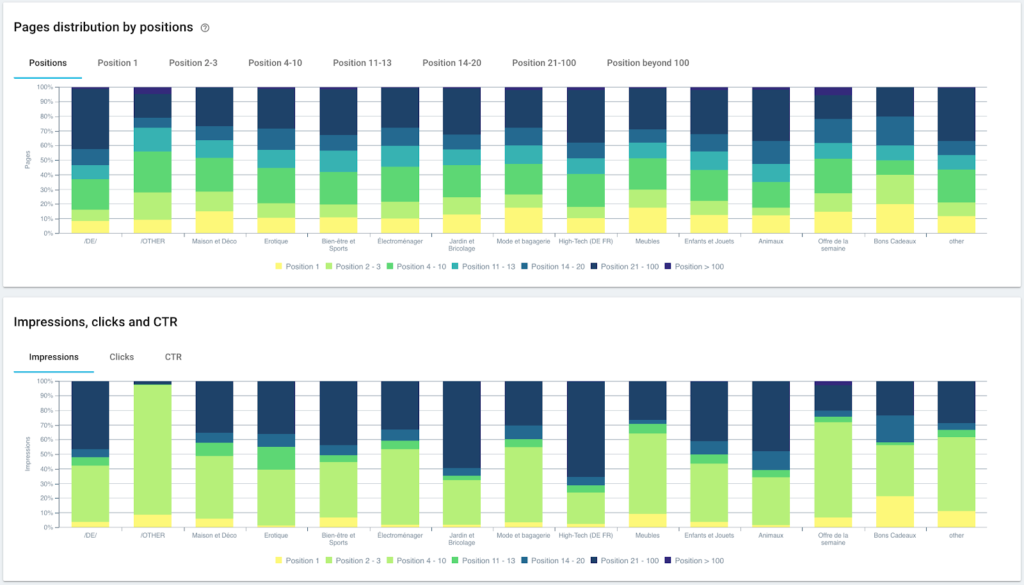
Ranking performance (GSC)
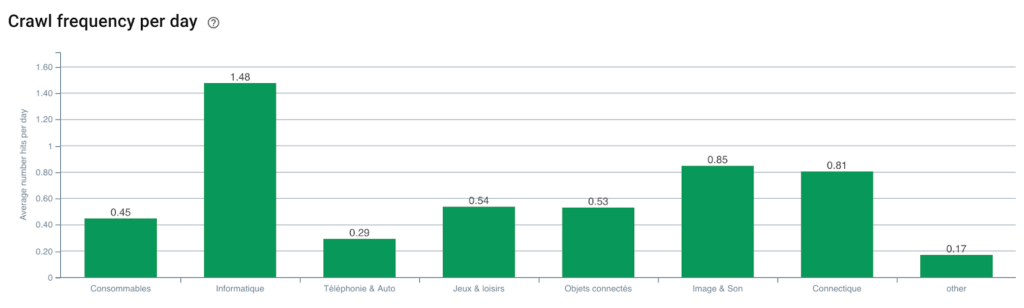
Googlebot crawl frequency
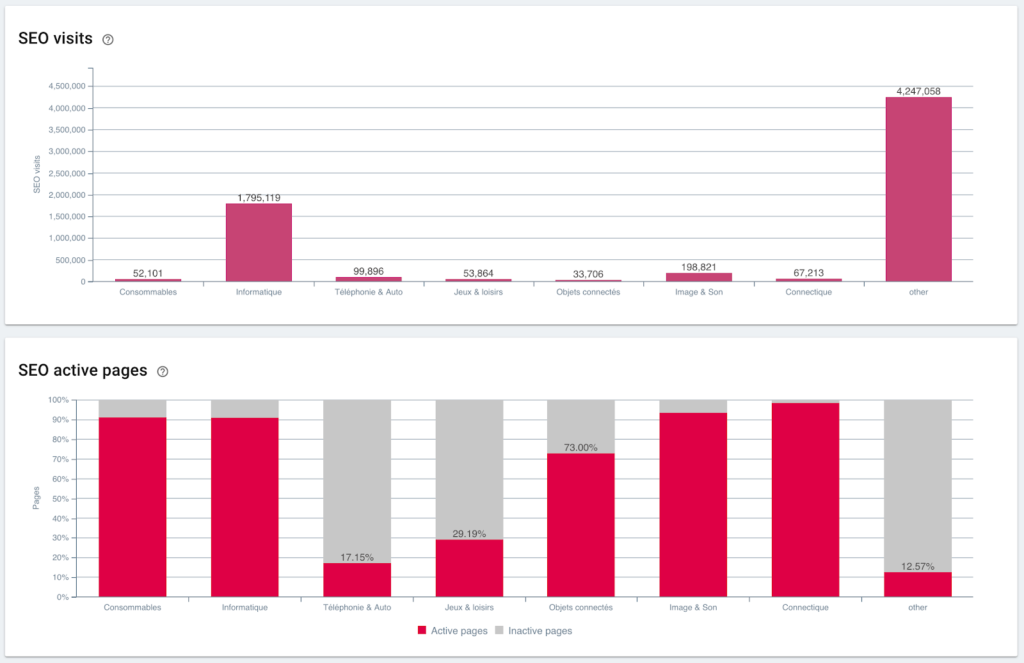
SEO visits and active page ratio
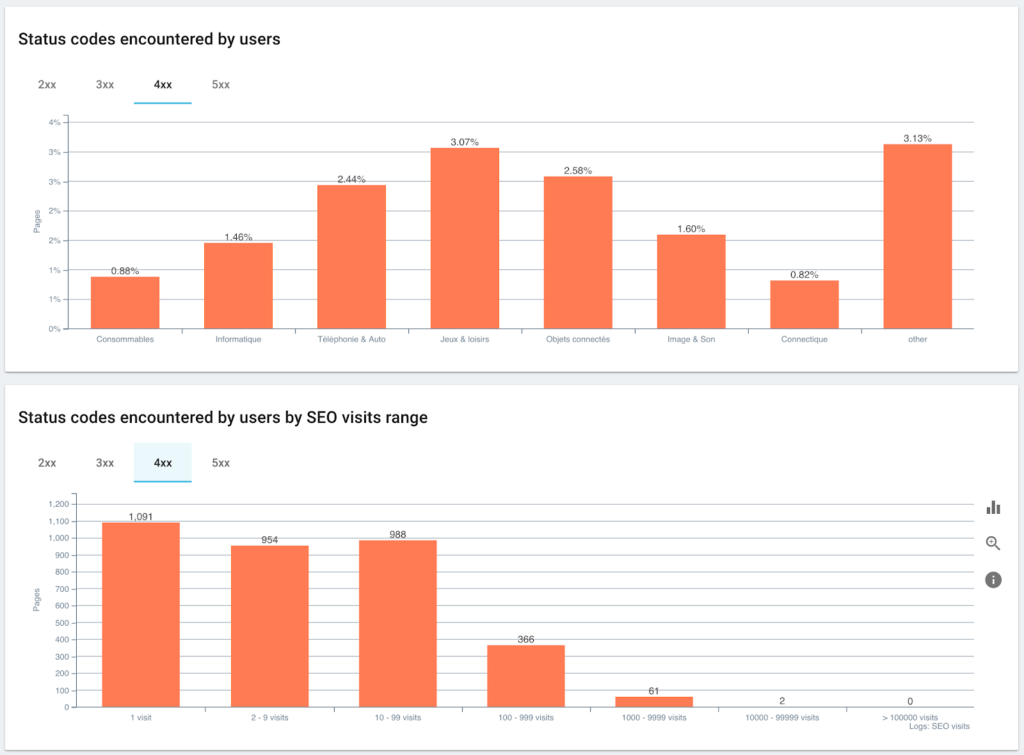
Status codes encountered by users vs. SEO sessions
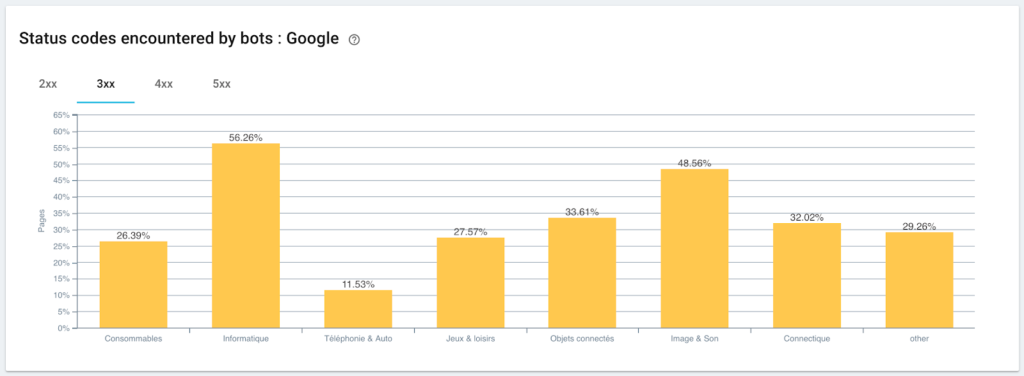
Monitoring of status codes encountered by Googlebot
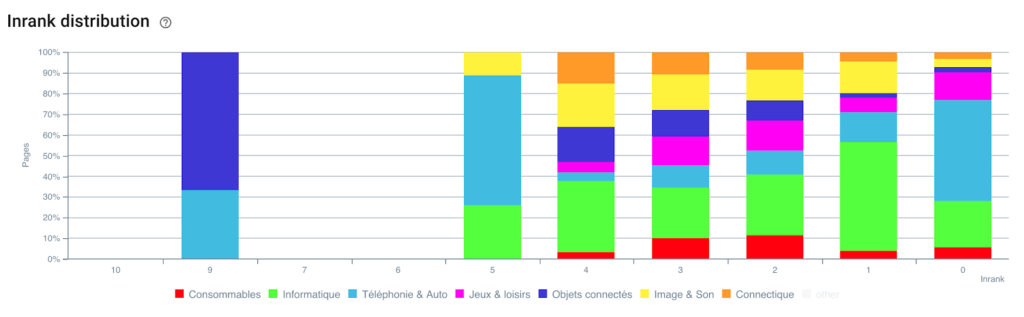
Distribution of the Inrank
And here we are, we have just created a segmentation automatically thanks to a script using Python and Oncrawl. All pages are now grouped according to the breadcrumb trail and this on 3 levels of depth:
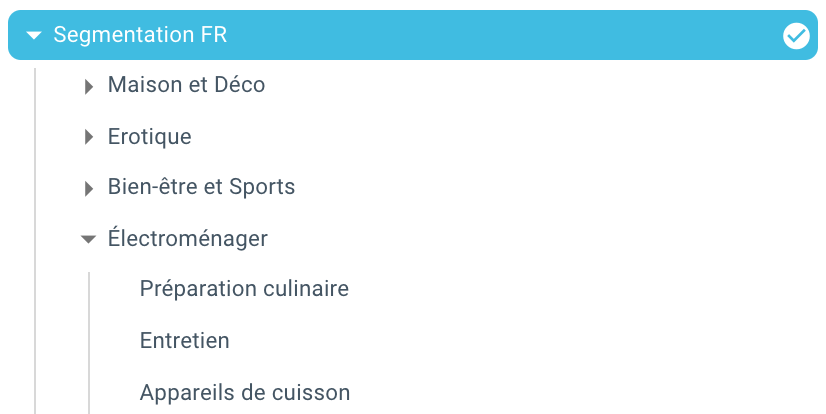
The advantage is that we can now monitor the different KPIs (Crawl, depth, internal links, Crawl budget, SEO sessions, SEO visits, Ranking performances, Load Time) for each group and sub-group of pages.
The future of SEO with Oncrawl
You’re probably thinking that it’s great to have this “out of the box” capability but you don’t necessarily have the time to do it all. The good news is that we’re working to have this feature directly integrated in the near future.
This means that you will soon be able to automatically create a segmentation on any scrapped field or field from Data Ingest with a simple click. And that will save you a ton of time, while allowing you to perform incredible cross-sectional SEO analysis.
Imagine being able to scrape any data from the source code of your pages or integrate any KPI for each URL. The only limit is your imagination!
For example, you can retrieve the sales price of products and see the depth, the Inrank, the backlinks, the crawl budget according to the price.
But we can also retrieve the names of the authors of your media articles and see who performs best and apply the writing methods that work best.
We can retrieve the reviews and ratings of your products and see if the best products are accessible in a minimum of clicks, receive enough links, have backlinks, are well crawled by Googlebot, etc…
We can integrate your business data such as turnover, margin, conversion rate, your Google Ads expenses.
Now it’s up to you to imagine how you can cross-reference the data to expand your analysis and make the right SEO decisions.
You want to test the auto segmentation on the breadcrumb trail? Contact us via the chatbox directly from within Oncrawl. ;)
🚀 Enjoy your crawling!
