
Technical SEO matters because it’s the starting point of any project. From an SEO’s expert point of view, every website is a new project. A website should have a solid foundation in order to get good results and reach the most important KPI in SEO like rankings.
Each time that I start with a new project, the first thing that I do is a technical SEO audit. Most of the time fixing technical issues can get astonishing results as soon as the website is recrawled.
It is funny for me when people talk about content and more content, but they don’t say a word about technical SEO. One thing is for sure, website health and Technical SEO are two important things that will be crucial in 2020. I don’t mean to say that content is not important. It is, but without fixing the technical issues on a website, I don’t think content can bring results.
I have seen cases where important pages have been blocked by directives in robots.txt file, or the most important category or services pages are broken or blocked by meta robots like noindex, nofollow. How it is possible to be successful without prioritizing by fixing these issues?
It can be surprising to see the number of SEOs that don’t know how to identify tech issues to report to web development specialists to be fixed. I remembered once while working in the corporate field, I created a Tech SEO audit checklist sheet to be used by my team. At that time, I realized that having at hand a quick fix sheet like this one can immensely help a team and generate a quick boost for a client. That’s why I consider the utmost importance to invest in a tool/software that can help you with technical SEO diagnostic and recommendations.
Let’s start the hands-on process on how to conduct a quick tech SEO audit which will make a big difference. This is a quick exercise that will take you about one hour to do even if you are not a pro. For me using a Tech SEO tool like Oncrawl to fast forward all the things in five minutes without having to do all the manual work makes my life easy.
I will go over the most important things to check when conducting a Technical SEO Audit. There are more things we can check for on-page problems, but I want to focus only on things that will create indexing issues and crawling waste of budget. Prioritizing this is the way to make sure that the most important pages will be crawled by Googlebot.
- Indexation
- Robots.txt file
- Meta robots tag
- 4xx errors
- Sitemaps
- HTTP/HTTPS (website security, mixed content and duplicate content issues)
- Pagination
- 404 page
- Site depth and structure
- Long redirect chains
- Canonical tag implementation
1) Indexing
This is the first thing to check. Many times indexing can be affected by a plugin configuration or any minor mistake but the impact on findability can be huge, as today there are over 6.16 billions of webpages indexed. You need to understand that any search engine is making an effort and even Google needs to prioritize the most relevant page for user experience. If you don’t consider making things easier to Googlebot, your competition will do it and gain much more trust that comes with a healthy website.
When there are indexing issues, your website health problems will reflect in loss of organic traffic. The process of indexing means that a search engine crawls a web page and organizes the information that later offers it in SERP. The results depend on relevance for user intent. If a web page can’t or has issues with crawling, this will favor other pages in the same niche to have an advantage.
Using search operators for example:
Site: www.abc.com
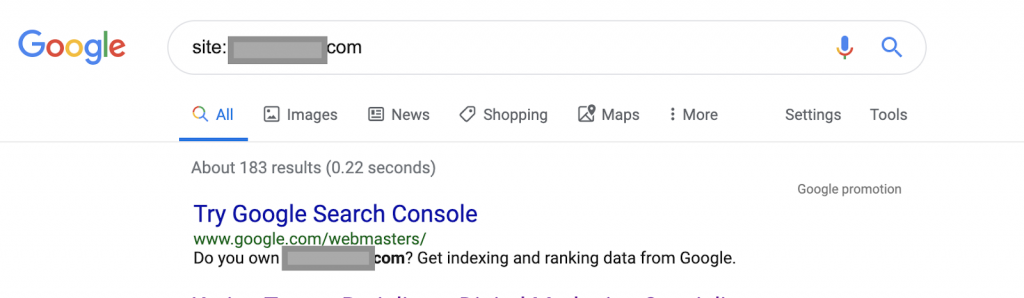
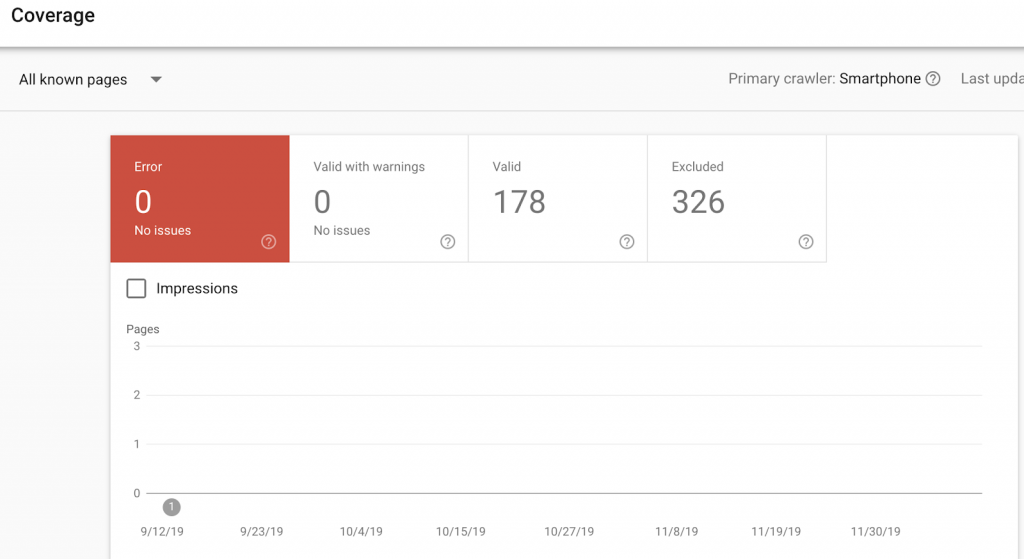
The query will return 183 pages indexed by Google. This is a rough estimation of the number of pages Google has indexed. You can check Google Search Console for the exact number.
You should also use a web crawler like Oncrawl to list all pages Google has access to. This shows a different number as you can see below:
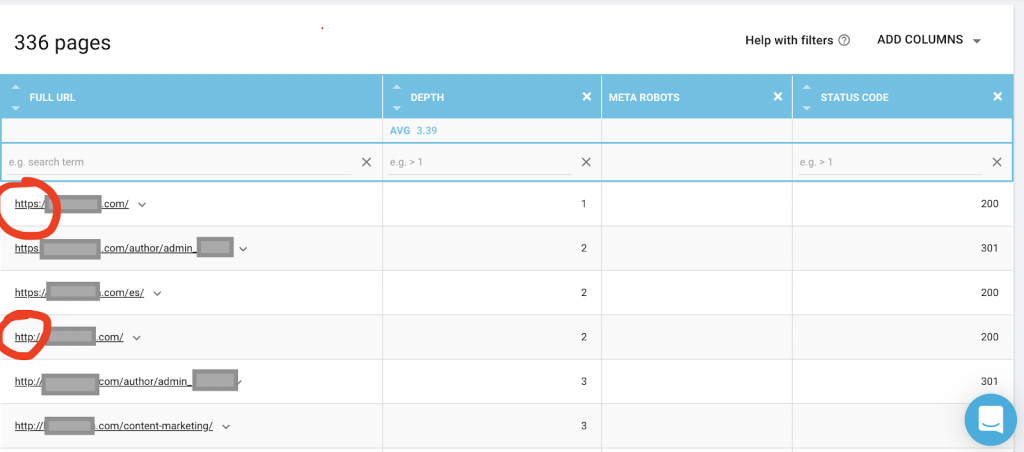
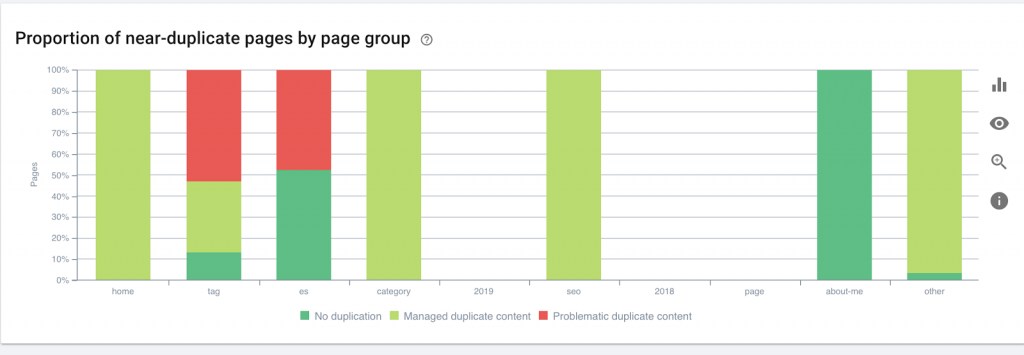
This website has nearly twice as many crawlable pages as it does pages that are indexed.
This might reveal a duplicate content issue or even a website security version problem between HTTP and HTTPS problem. I will talk about this later in this article.
In this case, website was migrated fromHTTP to HTTPS. We can see in Oncrawl that the HTTP pages have been redirected. Both the HTTP and the HTTPS versions are still accessible to Googlebot, and it may crawl all the duplicate pages, instead of prioritizing the most important pages that the owner wants to rank, causing a waste of crawl budget.
Another common issue among neglected websites or large websites like e-commerce sites are mixed content issues. To make a long story short, the issues come around when your secured page has resources like media files (most frequently: images) loaded from unsecured version.
How to fix it:
You can ask a web developer to force all HTTP pages to HTTPS version, and redirect HTTP addresses to HTTPS once using a 301 status code.
For mixed content issues you can manually check the source of the page and search for resources loaded as “src=http://example.com/media/images” which is almost insane to do it especially for large websites. That’s why we need to use a technical SEO tool.
2) Robots.txt file:
The robots.txt file tells crawling agents what pages they should not crawl. Robots.txt specifications guide indicates that the file format must be plain text with a maximum size of 500KB.
I will recommend adding the sitemap to robots.txt.file. Not everyone does this, but I believe it’s a good practice. The robots.txt file has to be placed in your hosted server in public_html and goes after the root domain.
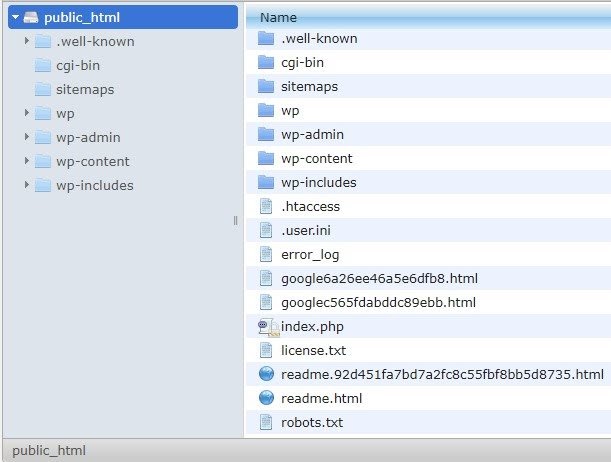
We can use directives in robots.txt file to prevent search engines crawling unnecessary pages or pages with sensitive information, such as the admin page, templates or shopping cart (/cart, /checkout, /login, folders like /tag used in blogs), by adding these pages on robots.txt file.
Advice: Make sure you will not block media file folder because this will exclude your images, videos or other self-hosted media from being indexed. Media can be very important for page relevancy as well as for organic ranking and traffic for images or videos.
Crawler SEO Oncrawl

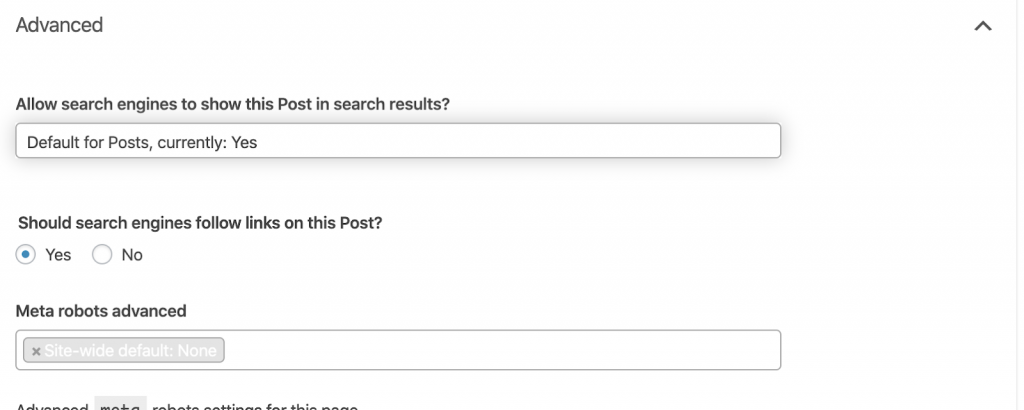
3) Meta Robots tag
This is a piece of HTML code that instructs search engines whether to crawl and index a page, with all the links within that page. The HTML tag goes in the head of your webpage. There are 4 common HTML tags for robots:
- No follow
- Follow
- Index
- No index
When there are no meta robots tags present, search engines will follow and index the content by default.
You can use any combination that best suits your needs. For example, by using Oncrawl I found that an “author page” from this website has no meta robots. This means that by default the direction is (“follow, index”)
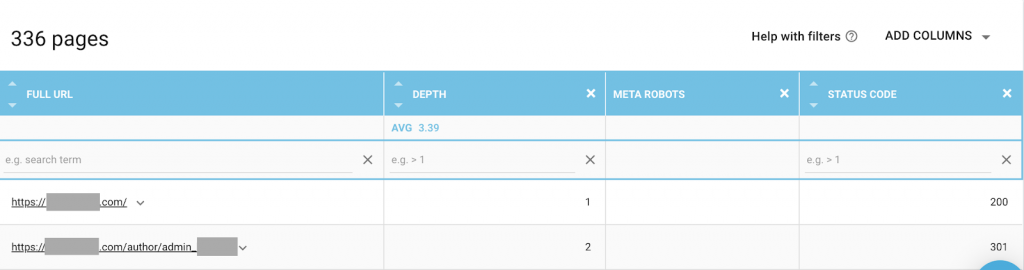
This should be (“noindex, nofollow”).
Why?
Each case is different, but this website is a small personal blog. There is only one author that publishes on the blog, and the domain is the name of the author. In this case, the “author” page provides no additional information even though it’s generated by the blogging platform.
Another scenario can be a website where categories on the blog are important. When the owner wants to rank for categories on his or her blog, then meta robots should be (“follow, index”) or default on category pages.
In a different scenario, for a big and well-known website where major SEO experts write articles that are followed by the community, the author name in Google acts as a brand. In this case you would probably want to index some author names.
As you can see, meta robots can be used in many different ways.
How to fix it:
Ask a web developer to change the meta robot tag as you need it. In the case above for a small website, I can do it myself by going to each page and changing it manually. If you are using WordPress, you can change this from RankMath or Yoast settings.
4) 4xx errors:
These are errors on the client-side, and they can be 401, 403, and 404.
- 404 Page Not Found:
This error occurs when a page is not available at the URL address indexed. It could have been moved or deleted, and the old address has not been properly redirected using web server function 301. The 404 errors are a bad experience for users and represent a technical SEO problem which should be addressed. It is a good thing to check often for 404s and to fix them, and not leaving them to be tried again and again for crawling agents wasting their budget.
How to fix it:
We need to find the addresses that return 404s and fix them using 301 redirects if the content still exists. Or, if they are images, they can be replaced with new ones keeping the same filename.
- 401 Unauthorized
This is a permission issue. The 401 error usually occurs when authentication is required such as username and password.
How to fix it:
Here are two options: The first one is to block the page from search engines using robots.txt.The second option is to remove the authentication requirement.
- 403 Forbidden
This error is similar to the 401 error. The 403 error happens because the page has links that are not accessible to the public.
How to fix it:
Change the requirement in the server to allow access to the page (only if this is a mistake). If you need this page to be inaccessible, remove all internal and external links from the page.
- 400 Bad Request
This occurs when the browser can’t communicate with the webserver. This error commonly happens for bad URL syntax.
How to fix it:
Find links to these URLs and fix the syntax. If this is not fixable, you will need to contact the web developer to fix them.
Note: We can find 400 errors with tools or in Google Console
5) Sitemaps
The sitemap is a list of all the URLs that the website contains. Having a sitemap(s) improves findability because it helps crawlers to find and understand your content.
We have different types of sitemaps and we need to make sure all of them are in good condition.
The sitemaps that we should have are:
- HTML sitemap: This will be on your website and will help users to navigate and find the pages on your website
- XML sitemap: This is a file that will help search engines to crawl your website (as a best practice it should be included in your robots.txt file).
- Video XML sitemap: Same as above.
- Images XML sitemap: It’s also the same as above. It is recommended to create separate sitemaps for images, videos, and content.
For big websites, it’s recommended to have several sitemaps for better crawlability because sitemaps should not contain more than 50.000 URLs.
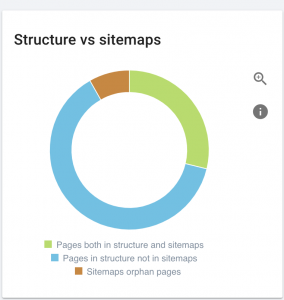
This website has sitemap problems.

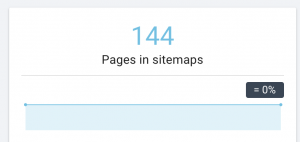
How we fix it:
We fix this by generating different sitemaps for: content, images, and videos. Then, we submit them via the Google Search Console and also create an HTML sitemap for the website. We don’t need a web developer for this. We can use any free online tool to generate sitemaps.
6) HTTP/HTTPS (duplicate content)
Many websites have these issues as a result of migration from HTTP to HTTPS. If this is the case, the website will be showing HTTP and HTTPS versions in search engines. As a consequence of this common technical issue, the rankings are diluted. These problems also generate duplicate content issues.
![]()
![]()

How to fix it:
Ask a web developer to fix this issue by forcing all HTTP to HTTPS.
Note: Never redirect all the HTTP to the HTTPS home page because it will generate a soft 404 errors. (You should say this to the web developer; remember they are not SEOs.)
7) Pagination
This is the use of an HTML tag (“rel = prev” and “rel = next”) that establishes relationships between pages, and it shows search engines that content which is presented in different pages should be identified or related to a single one. Pagination is used to limit the content for UX and weight of a page for the technical part, keeping them under 3MB. We can use a free tool to check pagination.
Pagination should have self-canonical references and indicate a “rel = prev” and “rel = next”. The only duplicate information will be the meta title and meta description, but this can be changed by developers to create a small algorithm so every page will have a generated meta title and meta description.
How to fix it:
Ask a web developer to implement pagination HTML tags with self-canonical tag.
8) Custom 404 Not Found Page
A 404 response is as we discussed before is a “Not Found” error that brings users to a broken link or a nonexistant page. This is an opportunity to redirect users to the right place. There are great examples of custom 404 pages. This is a must-have.
Here is an example of a great 404 custom page:

How to fix it:
Create a custom 404 page: think about something amazing to add on it. Make this error into an opportunity for your business.
9)Site depth/structure
Page depth is the number of the clicks that your page is located from the root domain. John Mueller from Google said “pages closer to the home page have more weight”. For example, let’s imagine that the page here requires the following navigation in order to be reached:

The page “rugs” is 4 clicks away from the home page. It is recommended to not have pages located more than 4 clicks away from the home, as search engines have a hard time crawling deeper pages.
This graphic shows the page group by depth. It helps us to understand if a website’s structure needs to be reworked.
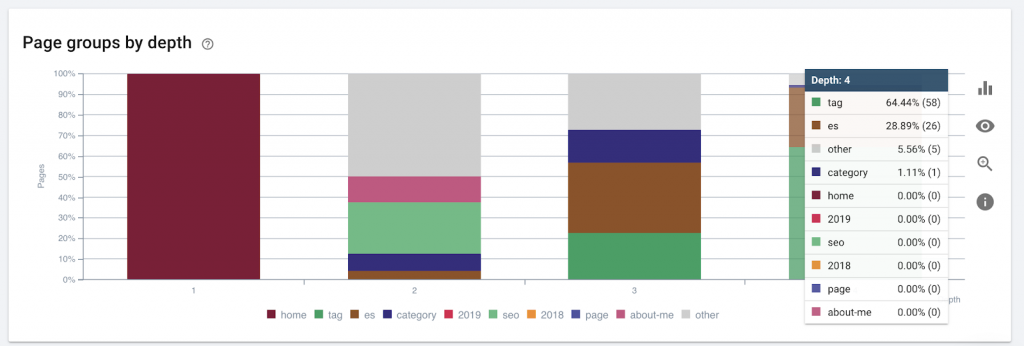
How to fix it:
The pages that are most important should be closest to the homepage for UX, for easy access by users and for better website structure. It is very important to take this into consideration at the time of creating a website structure or restructuring a website.
10. Redirect Chains
A redirect chain is when a series of redirects happens between URLs. These chains of redirection may also create loops. It also presents problems to Googlebot and wastes crawl budget.
We can identify chains of redirects by using the Chrome extension Redirect path, or in Oncrawl.
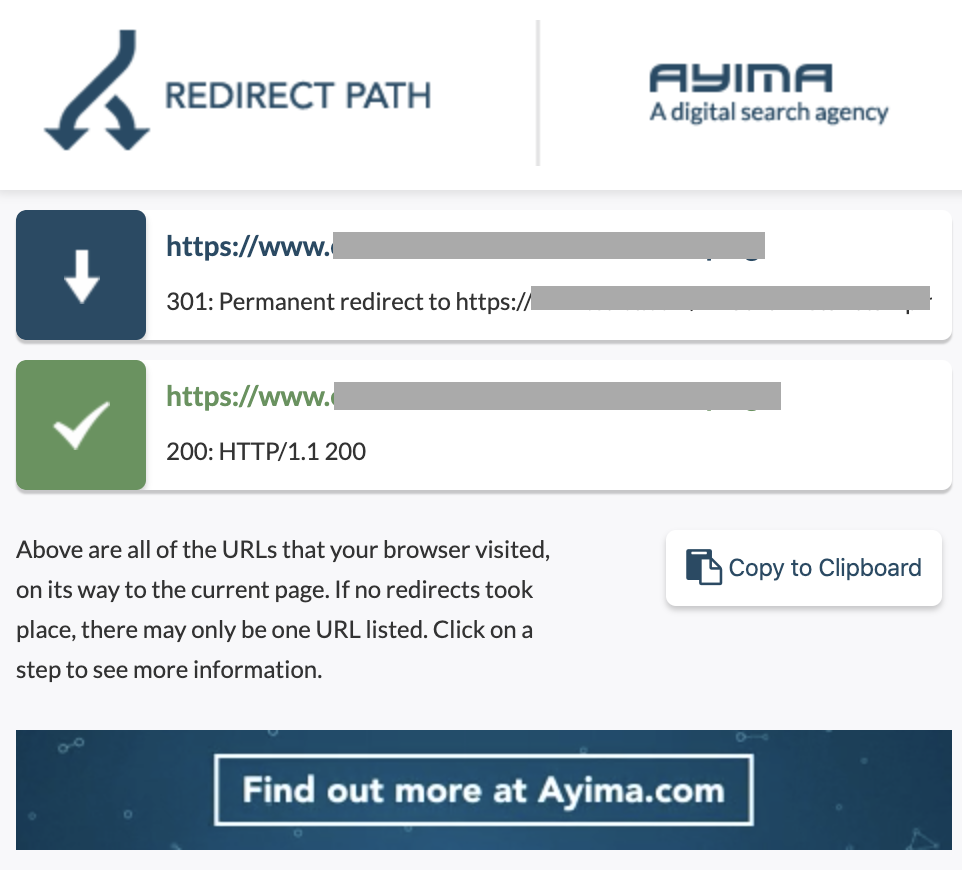
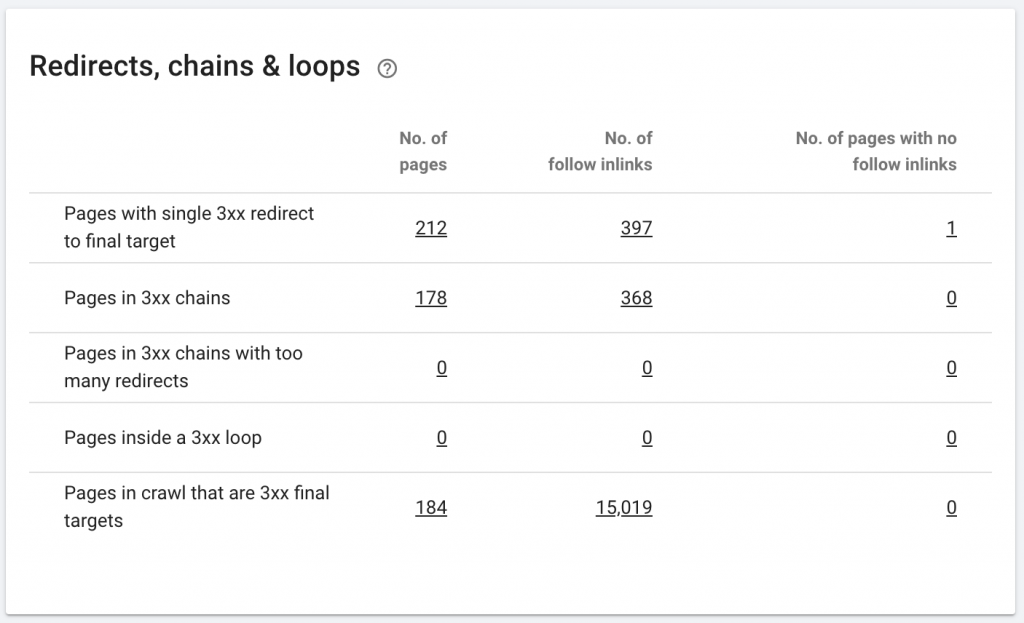
How to fix it:
Fixing this is really easy if you are working with a WordPress website. Just go to redirection and look for the chain- delete all the links involved in the chain if those changes happened more than 2-3 months back and just leave the last redirect to the current URL. Web developers can also help with this by making all the changes required in .htacces file, if needed. You can check and change the long redirect chains in your SEO plugins.
11) Canonicals
A canonical tag tells search engines that the URL is a copy of another page. This is a big issue that is present on many websites. Not implementing canonicals in the right way, or implementing them at all, will create duplicate content issues.
Canonicals are commonly used in e-commerce websites where a product can be found multiple times in different categories such as: size, color, etc.
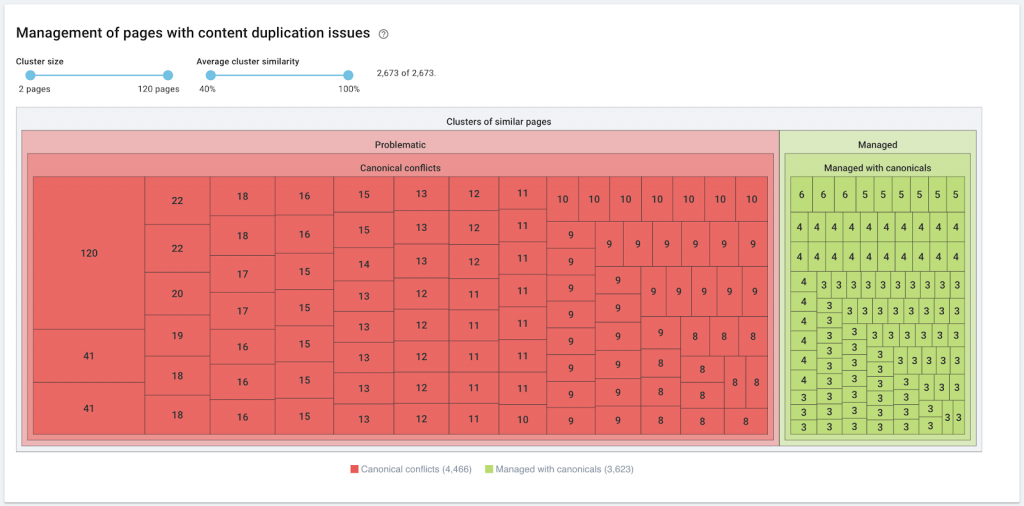
You can use Oncrawl to tell whether your pages have canonical tags, and whether or not they are implemented correctly. You can then explore and correct any problems.
How we fix it:
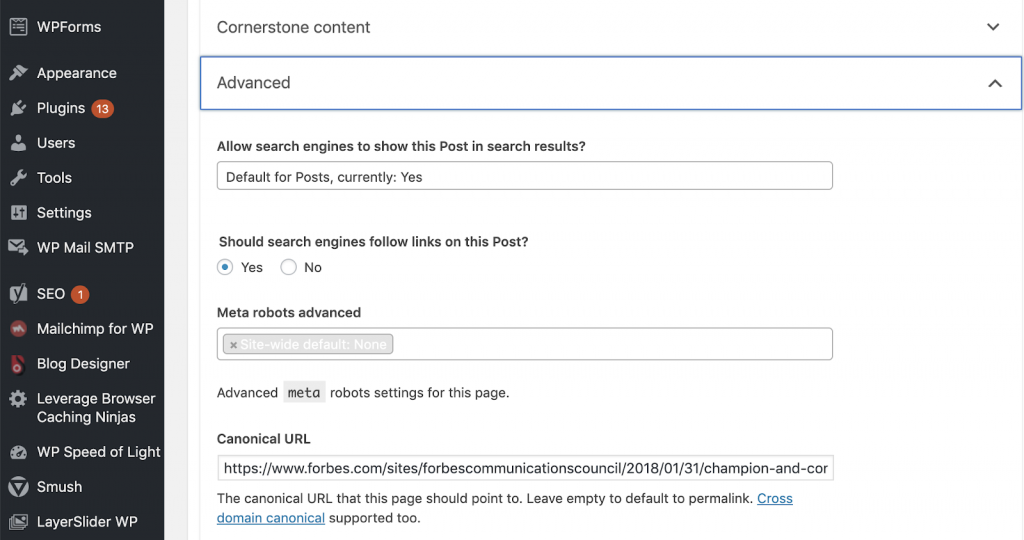
We can fix canonical problems by using Yoast SEO if we are working in WordPress. We go to the WordPress dashboard and then to Yoast -setting – advanced.
Running your own audit
SEOs that want to start diving on the technical SEO need a guide of quick steps to follow to improve SEO health. Talking about Technical SEO with John Shehata, the Vice President of Audience Grow at Conde Nast and founder of NewzDash on Global Marketing Day in NYC the past Oct 2019.
Here is what he said to me:
“A lot of people in the SEO industry are not technical. Now, not every SEO understands how to code and it’s hard to ask people to do this. Some companies, what they do is they hire developers and train them to become SEOs to fulfill the technical SEO gap.”
In my opinion, SEOs that don’t have the full code knowledge can still do great at Tech SEO by knowing how to run an audit, identifying key elements, reporting, asking web developers for implementation, and finally testing the changes.
Ready to get started? Download the checklist for these top issues.

