
How long after publication does it take Google–and organic visitors–to visit a page? Are this month’s pages really more popular than last month’s pages? Is it worth it to keep archives stretch over more than ten years?
These questions and more were at the heart of our Customer Success team’s analysis of multiple news and media sites based on article publication date. Here’s how they did it, and what they learned.

How to segment a site by publication date
How you segment your site will depend on how and where you display the publication date for your articles.
Using data in the URL
If you use the publication date in your URL, it can be used to create a segmentation. The advantage of this is that your segmentation will be based on a URL, and can therefore be used in all reports, even those that don’t have access to indexed custom data.
- Create a segmentation, and build page groups based on your URL structure.
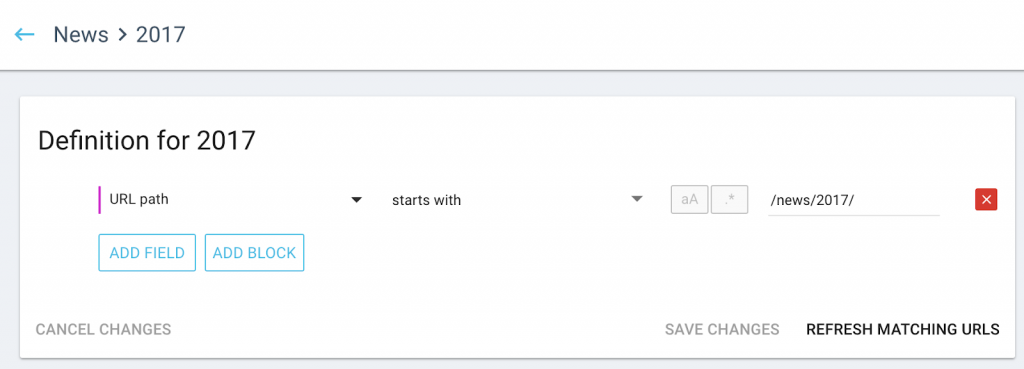
Here is an example using years:
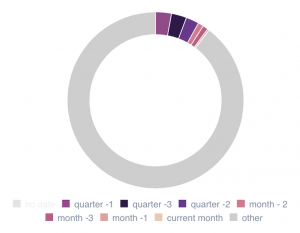
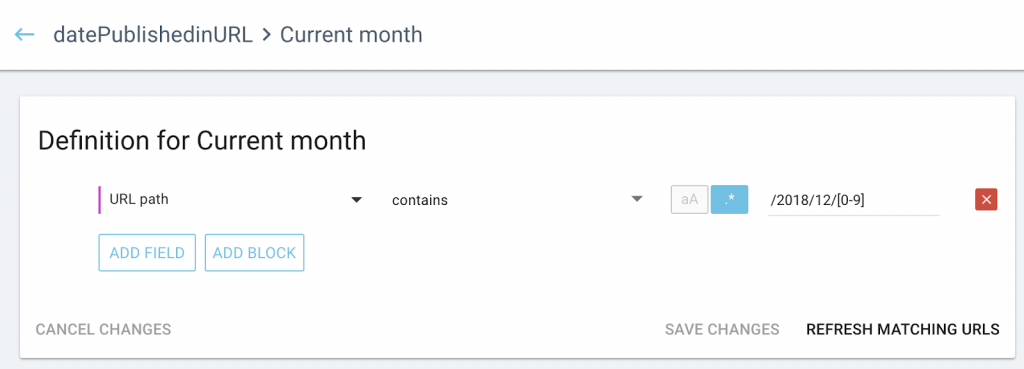
And here is another using months, quarters, and archives:
Using scraped data from the page
If you publication date is not part of the page’s URL, you can scrape it from the page source at the same time as the crawler obtains other information about the page. The advantage of this method is that it will allow you to create sliding segmentations relative to today’s date, which can be reused from month to month without modification.
- In the crawl settings, set up your scraping rule to create a custom field called “datePublished”. The name is important.
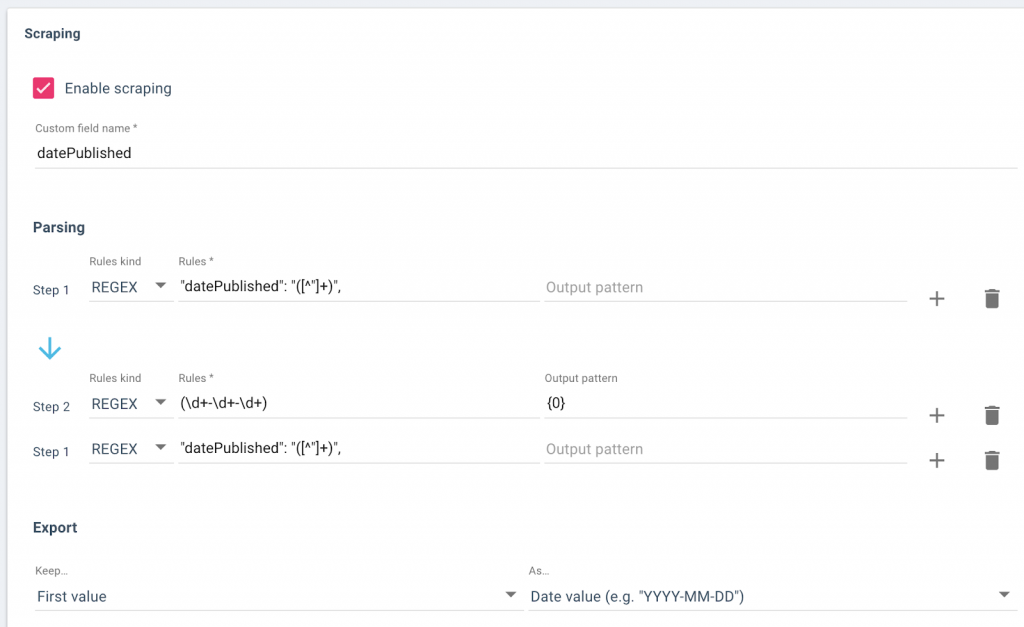

- Run a crawl to create the custom field.
- Create a segmentation by uploading our datePublished segmentation, and modify it if necessary.
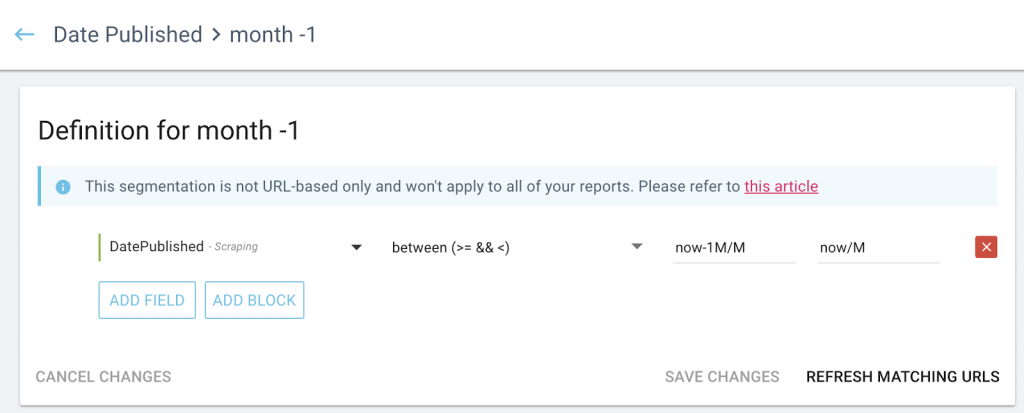
What you can learn from looking at crawl and user behavior vs publication date
The recency or freshness of a page affects crawl frequency and the probability that the page will be indexed if crawled.
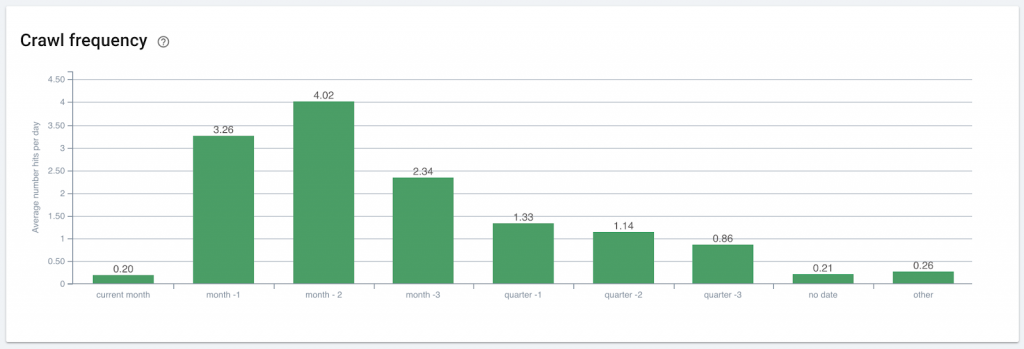
Most sites show a pattern of increasing crawl frequency, when then trails off over time. In this case, the crawl frequency for the current month is sufficient to crawl each new page shortly after publication. Within the next month, Google returns multiple times per day to crawl the page again.
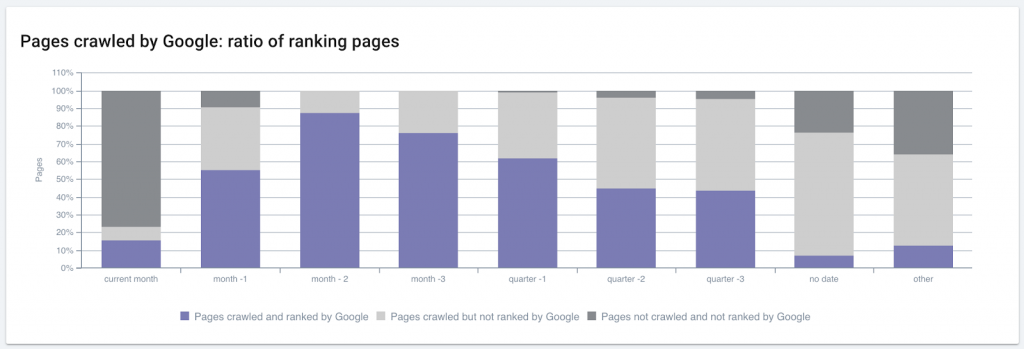
When pages published this month don’t rank on some sites, it’s often because they haven’t yet been crawled (dark gray). Managing crawl waste for a site like this one can get new pages crawled faster and will help rank these pages.
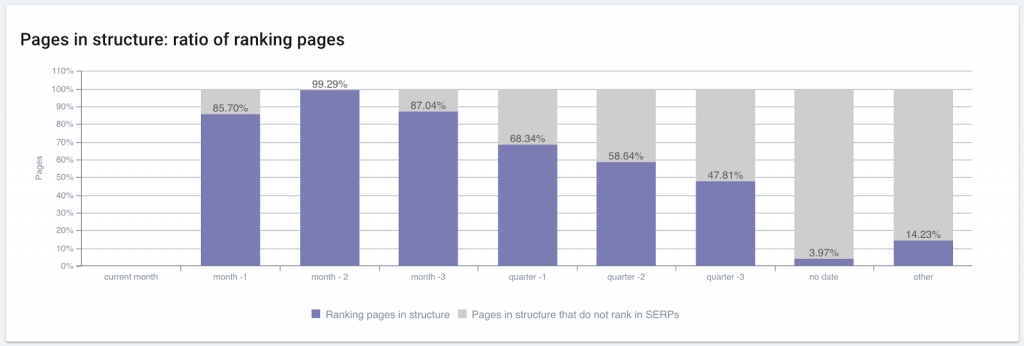
The percentage of ranking pages in a site often follows a curve similar to that of crawl frequency. (Note that this particular site had not yet published any articles during the month when this capture was taken.)
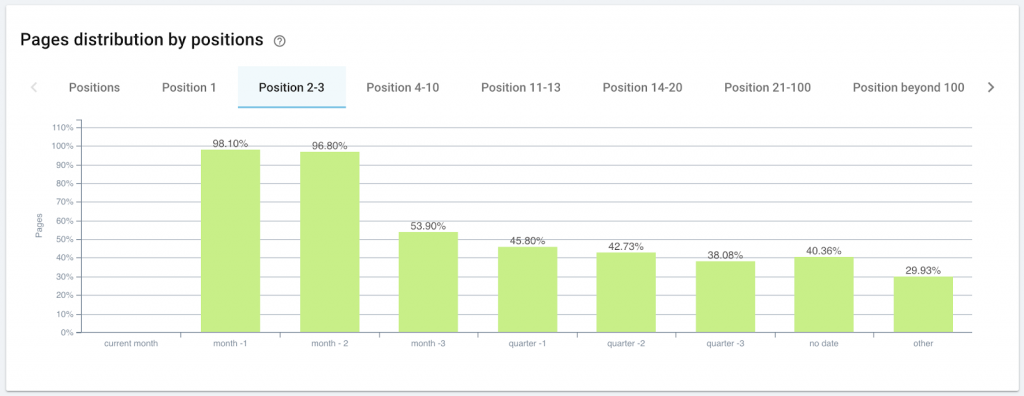
Publication date can influence ranking
A higher percentage of more recent pages rank in positions 1, positions 2-3 and 4-10. The percentage of pages ranking in these positions declines as the age of the page increases.
Publication date can correlates with the occurrence of page errors
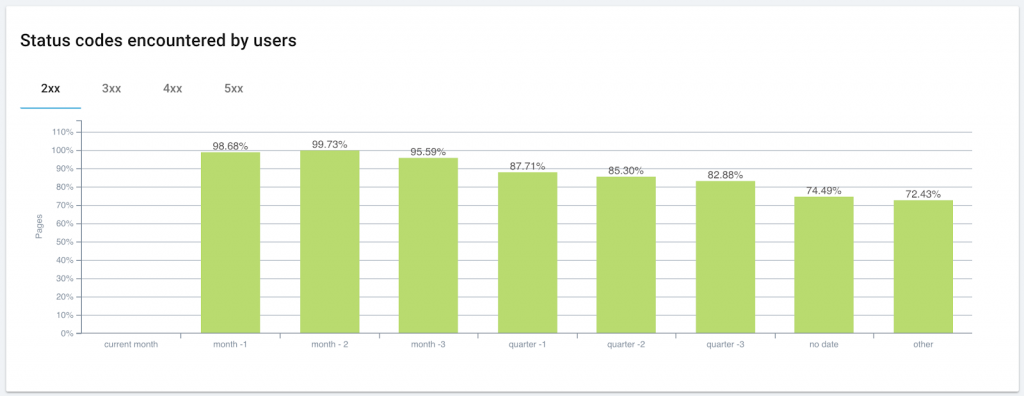
The fresher the page, the more likely a user is to get a 200 status code (an error-free page).
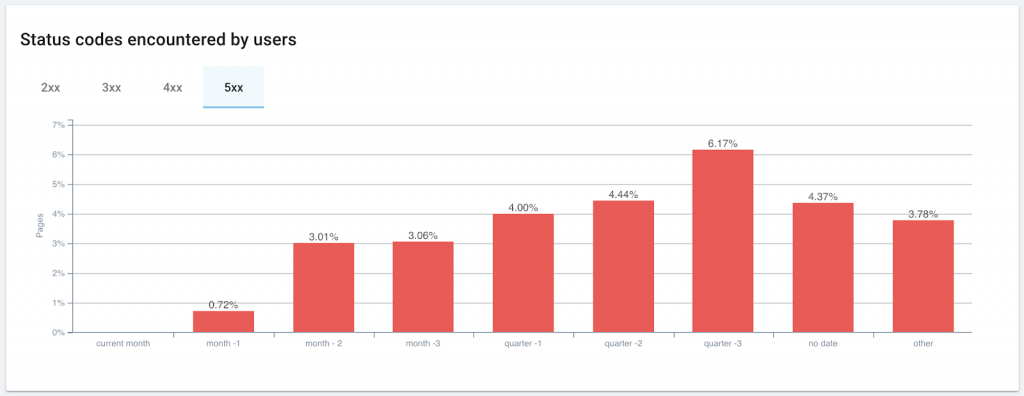
Users (and bots) are more likely to encounter server errors (5xx) and 4xx errors on older pages.
Publication date can correlate with server or technical issues
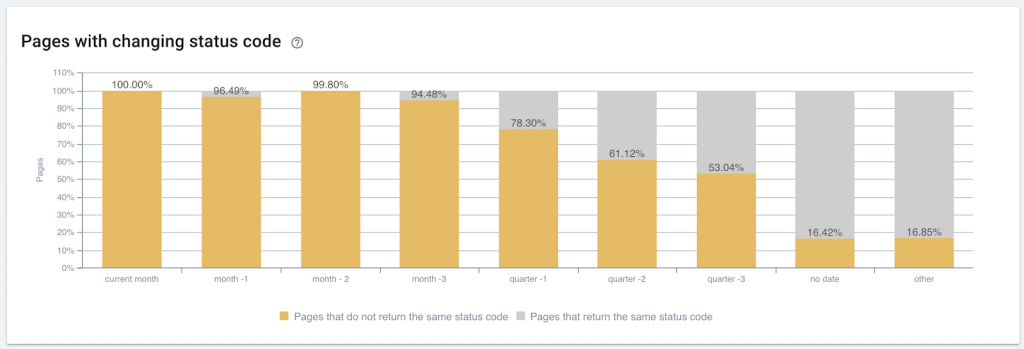
On this site, Oncrawl’s bot and googlebot received different status codes more frequently on newer content. To better promote fresh content, it’s worth looking into whether updates to the server or the CMS in the past few months could cause fluctuations in page status.
Publication date correlates with load time values
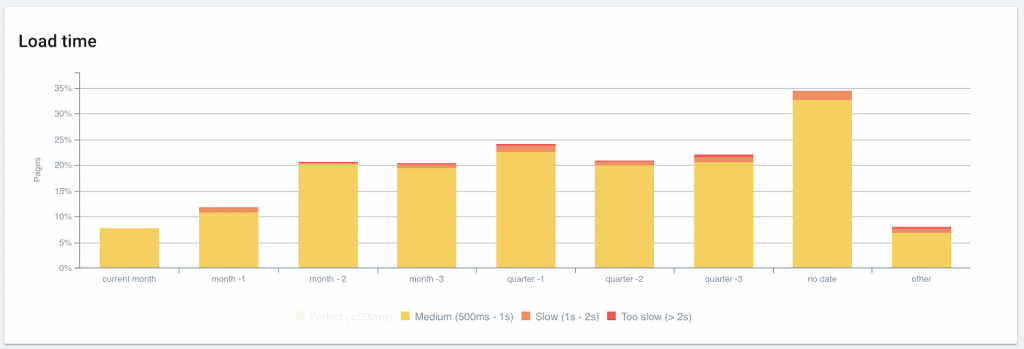
On this site, slow load times disproportionately affect older content. If legacy content still ranks well, it could be beneficial to reinforce its internal linking and review elements affecting page speed in order to improve its performance.
Publication date may correlate with depth on your site (and if it doesn’t, optimizing site structure may help rank new pages)
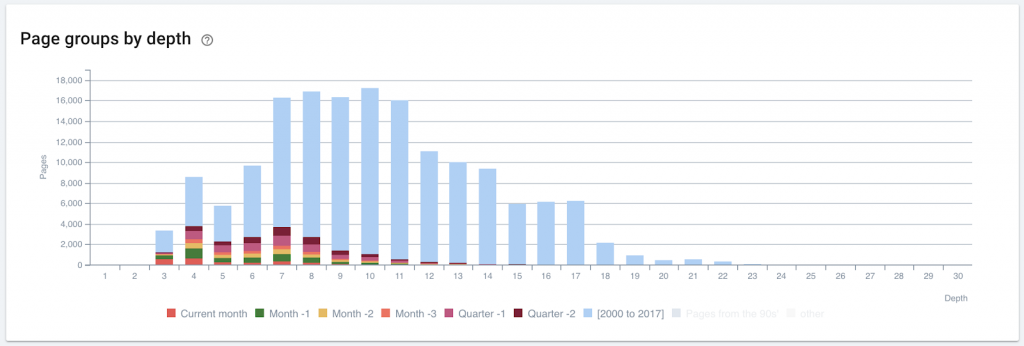
More recent pages occur more frequently closer to the home page. Older pages make up the bulk of deeper levels of this site.
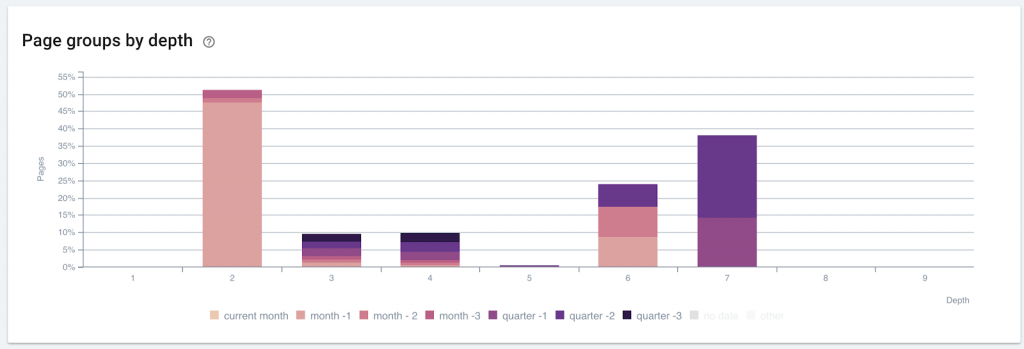
The overwhelming presence of newer pages at a depth of 2 is indicative of the effective promotion of fresh pages on this site.
Publication date often correlates strongly with user behavior
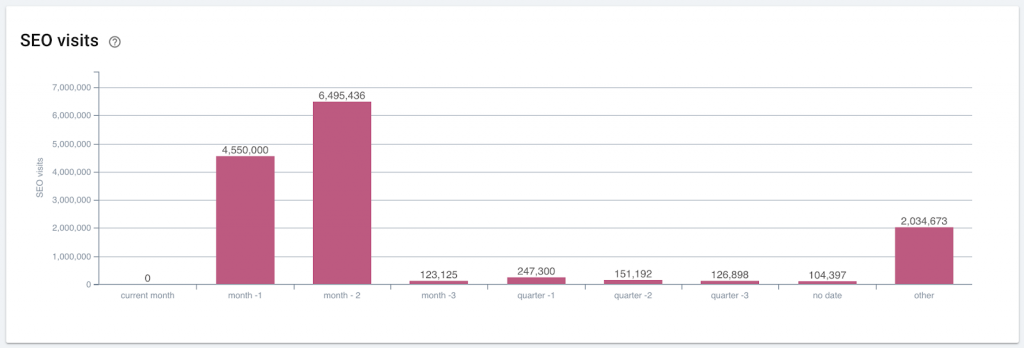
The vast majority of organic visits occur on recently published pages. (Note that this particular site had not yet published any articles during the month when this capture was taken.)
Publication date often influences CTR
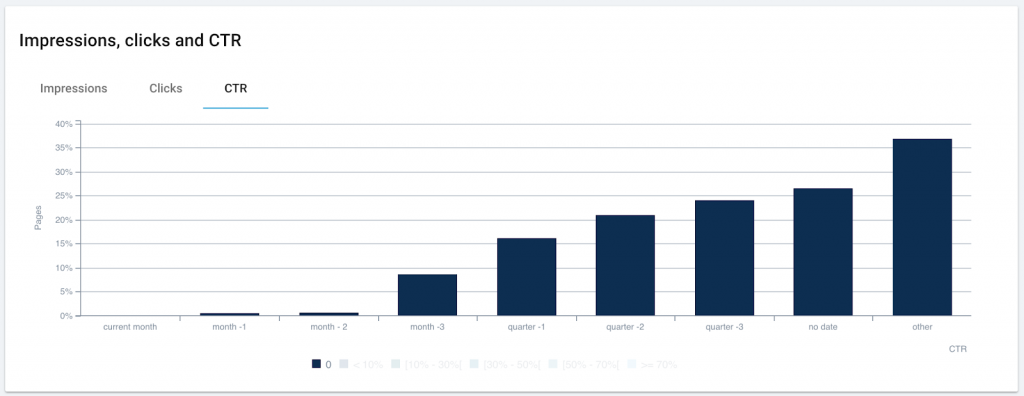
The older the page, the more probable that ranking pages have a CTR of zero.
However, well-promoted pages can also grow and maintain high click-through rates over time.
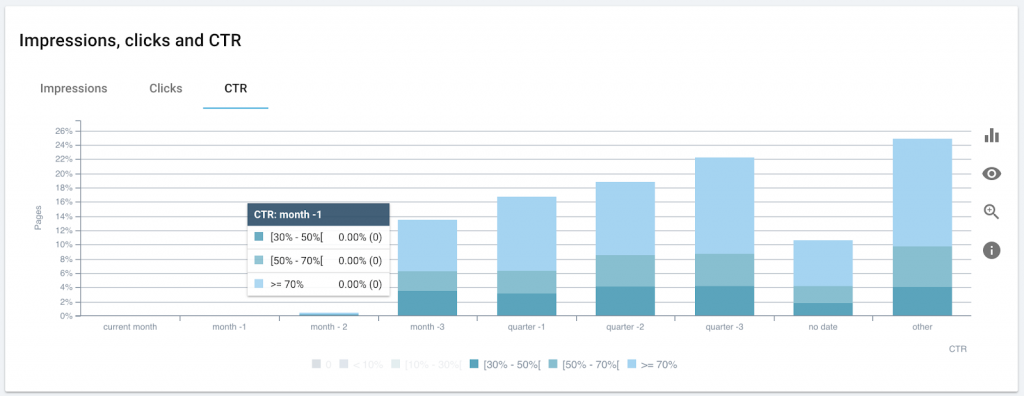
Appropriate linking and promotion of legacy pages allow this site to maintain CTRs for older content that surpass those of recent content.
Changing standards over time may create SEO issues for certain ranges of publication dates
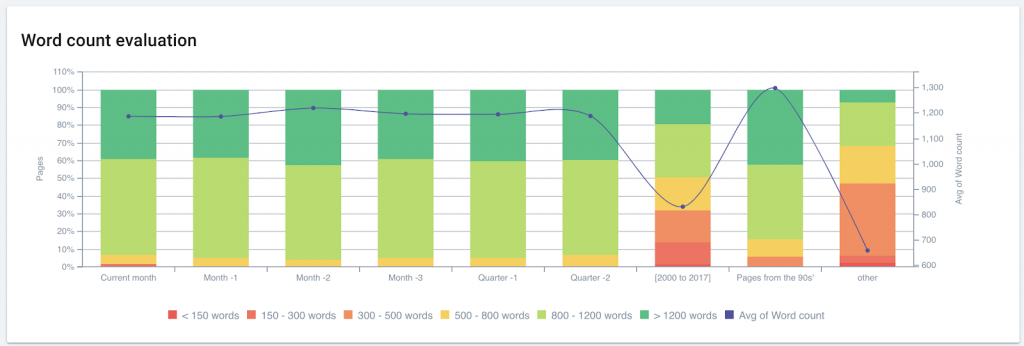
This site shows how copywriting and SEO efforts in the past few years have produced pages with optimized or identical profiles across on-page metrics (here: wordcount). However, older pages on this site have much more variation in word count and in on-page optimization in general.
Publication date may correlate with duplicate content or duplicate content management issues
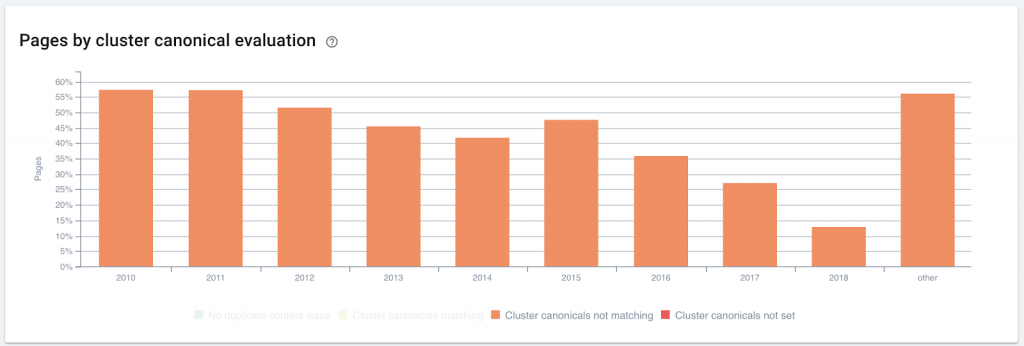
Increased SEO knowledge has allowed this site’s team to produce new content that is unique or correctly canonicalized, reducing the number of errors in duplicate content strategy by two thirds over the period 2015-2018.
