
Oncrawl was built around the SEO needs of the n°1 French ecommerce player back in 2015. This meant we had to scale our analysis and deal with a website with more than 50M URLs in a short period of time. Tough, you would say, for a new player? Actually, our infrastructure, on which we spent 1,5M€ just in R&D and which had previously supported different data projects, has made it easy. As the distinction between desktop and cloud-based crawlers is still sometimes unclear, we thought it might be useful to explain why Oncrawl has much more to offer than a simple desktop crawler – from high scaling capabilities to third-party integrations and speed of analysis.
Scaling to infinity and beyond
Desktop crawlers are limited in crawling capacity due to the resources and memory of the computer they are running on. It’s most likely they’ll be limited to crawling only a few thousands URLs per crawl. While this can be ok for small websites, it can still take more time to crawl these URLs compared to a SaaS (Software as a Service) crawler. Cloud-based crawlers are distributed across many servers so you aren’t limited by the speed and size of your machine.
This means that there is no crawl we can’t handle. We’ve been working for small websites as well as for very large websites, including some of the Fortune 500 companies. As said in the intro, we developed our SEO crawler after Cdiscount, the largest ecommerce website in France, asked us to build them a custom solution to handle their 50M+ URLs and SEO needs in one single crawl. Plus, our scaling capabilities have made us two years in a row the Best SEO Tool at the European Search Awards, the leading ceremony in the search industry. Currently, we collect up to 25 millions of URLs per day and per website, or approximately 1 billion web pages and 150 billions of links per month. You can learn more about our technology and how we handle GDPR policies here.
Custom speed, extensive capabilities
Since our application is cloud-based, you don’t need to think about your machine’s resources and speed capabilities. It also means there is no restriction regarding timing or the number of crawls that can be launched. You can launch as many crawls as your subscription allows and do other things while it’s crawling. Using a cloud-based solution also means you can close your application window and wait for the crawl to be done – it’s working on its own and doesn’t need your surveillance. Oncrawl lets you schedule crawls based on your SEO needs, whether you need to crawl your site once a week or every month. You can also decide to speed up your analysis if you need them faster.
Since the Oncrawl app can be used to crawl any website, our bot will follow the Crawl-Delay directive expressed in the robots.txt file found on the target website, if any.
Otherwise, we limit the crawl rate at the speed of 1 page per second, so our bot is not too aggressive against the targeted website.
When a website has a Crawl-Delay directive higher than 1, our application emits a warning to tell you that the crawl will be slower than the requested speed.
If the Crawl-Delay is higher than 30, we display an error. We will simply not allow you to configure a crawl with such an high crawl delay.
The only way to set up a crawl under those circumstances is to use a virtual robots.txt file.
To do so, you must first validate the project with your Google Analytics account, so we can make sure that you have some kind of ownership on the domain you want to crawl.
We have a few different parameters that let you take control of your crawl:
- Speed up your crawl
- Pause, stop, relaunch or abort a crawl
- Schedule a crawl to avoid peak traffic times and ease stress on your server when our bots come to your site
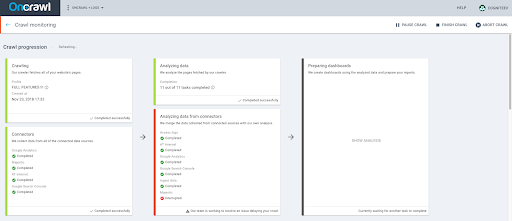
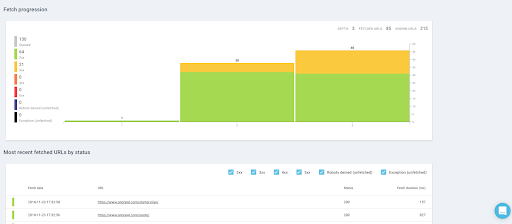
- See in real-time the pages that have been fetched, the number of URLs we retrieved so far and see if there is any issue slowing your crawl down.
Log files analysis made easy
Oncrawl is so much more than a simple SEO crawler. Over the past years, we’ve also released a powerful log files analyzer tackling issues that no other SEO solution has found.
Complete log files are a perfect reflection of the life of your site. Whether it is visitors or bots, pages displayed or calls to resources, any activity on your site is written in it.
With information such as IP address, status code, user-agent, referrer and other technical data, each line of logs (server-side data) can help you complete your site’s analysis, which is most often based on analytics (more client-side oriented).
Our log files analyzer supports any type of log formats, from standard ones like IIS, Apache on Ngnix to more custom formats. There’s no analysis we can’t do. We also let our users directly retrieve their logs data from third-party solutions like Splunk, ELK / Elastic Stack, Amazon S3, OVH (ES) or Cloudflare.
This means you won’t be stuck with an additional third-party log files manager any more, the way you are with some of our competitors.
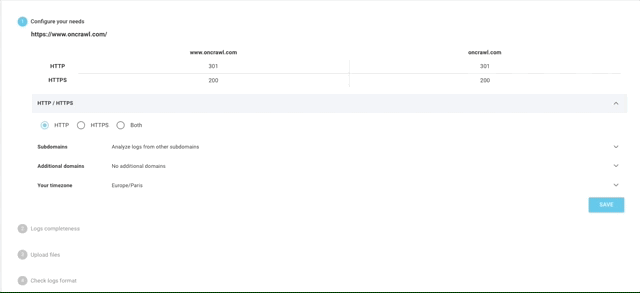
Our interface makes it easy to automatically upload your log files through a secure and private FTP. It only takes a few steps to complete your log files analysis.
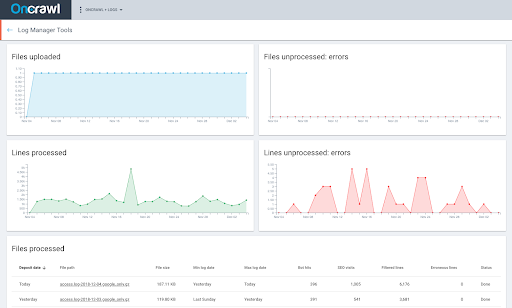
You can also monitor your files being processed in real-time and see if there’s any error blocking their upload.
Unlimited third-party integrations
Oncrawl has worked on developing built-in connectors with leading search marketing solutions that SEOs can’t live without: Google Search Console, Google Analytics, Adobe Analytics or Majestic, just to name a few. Integrating these solutions into your audit process isn’t redundant: it provides a more comprehensive view of your website’s performance and health on search engines and clarifies how bots and visitors really behave on your website. You’re also saving time and effort as you don’t need to manually crunch these data later in Excel spreadsheets.
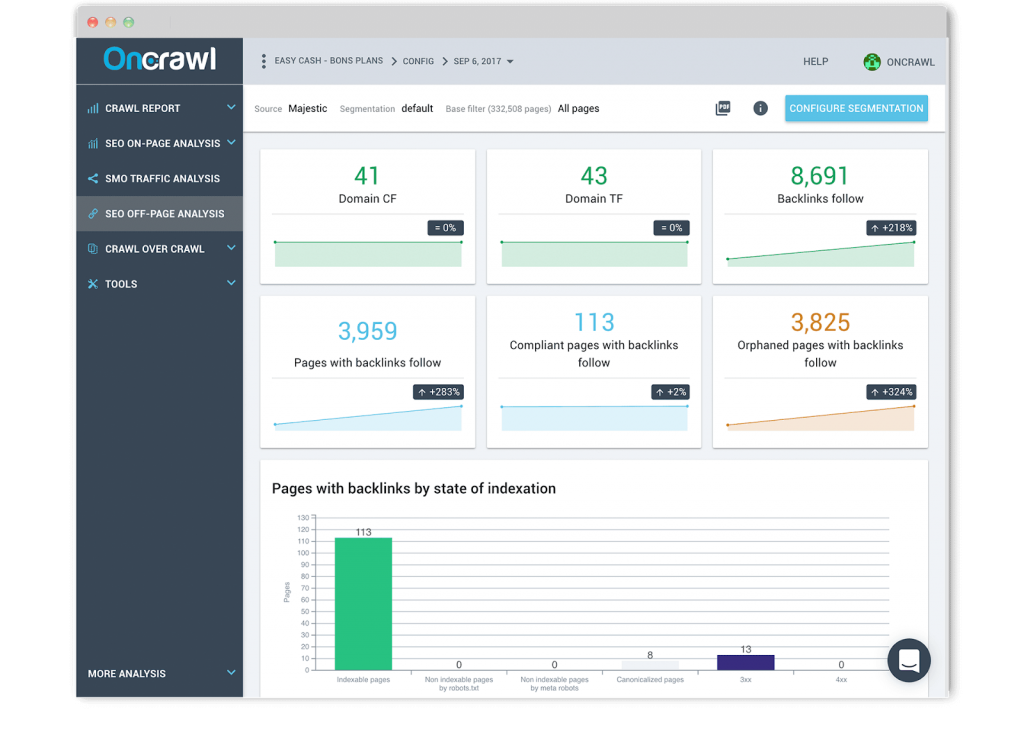
Backlink report
We’ve built a trustworthy relationship with Majestic, the leading link intelligence solution. Our cross-data analysis lets you combine your crawl data and logs data with your backlink data to understand the influence of backlinks on your SEO traffic and crawl frequency. Once you’ve set up a site-wide segmentation of custom groups of pages based on your most important KPIs. You can also, visualize the number of backlinks in relation to page click depth level or examine whether the number of backlinks has an influence on Google’s behavior.
The analyses we provide, in which backlinks data are correlated and combined on a URL and bots hits level, are currently the only ones on the market.
Ranking report
We’ve also developed a unique connector to Google Search Console to understand how your site is found and indexed, and how your on-page optimizations have an impact on your traffic and indexing. We provide standard yet exhaustive insights regarding your keywords distribution, impressions, clicks and click-through rate over time, whether it is on desktop or mobile, for branded or non-branded keywords or regarding your groups of pages. More importantly, we also offer unique analysis that none of our competitors have achieved.
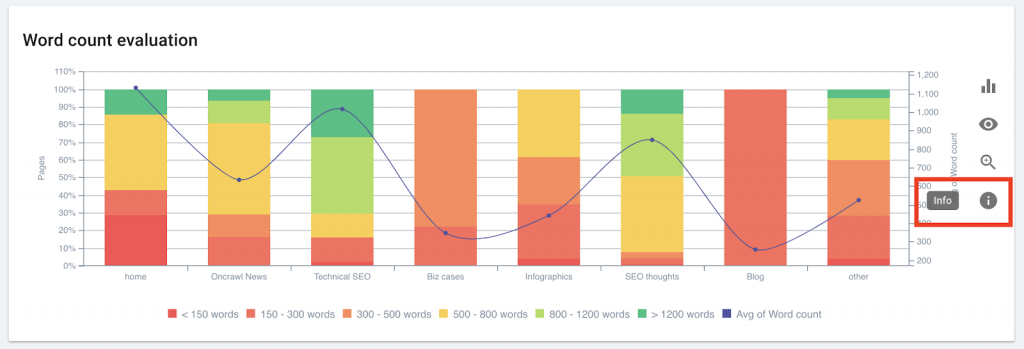
Oncrawl uses your segmentations and data from your log files to interpret your ranking data. You can thus identify the common characteristics of pages that rank and those which don’t regarding depth, internal popularity, word count, inlinks, load time and title evaluation. Not only that, but you can also examine the impact of description length and structured data on click-through rate.
Finally, Oncrawl Rankings lets you combine your crawl, log files and Search Console data at scale to highlight ranked pages and understand if crawl budget is influencing your positions. No other crawls, whether desktop or cloud-based, support such features.
Analytics report
We let you connect your Google Analytics or Adobe Analytics (ex-Omniture) to understand how on-page and technical SEO affect organic traffic performances from search engines. We help you monitor SEO traffic performance and user behavior regarding each section of your website.
CSV Ingest
While we’re constantly working on new integrations from third-party solutions, we didn’t want to leave you without a particular type of data you might need to run your technical SEO audits. That’s why we let you upload CSV files at scale (you can upload millions of rows) to add a new layer of data at a URL level. You can build your very own segmentations and filters based on these particular data (rankings, CRM, business, Google Ads data, etc.) to see whether your most strategic pages meet your objectives.
Open API, custom analysis
Oncrawl is based on a platform built around an API. The Oncrawl REST API is used for accessing your crawl data as well as managing your projects and your crawls. In order to use this API you need to have an Oncrawl account, an active subscription and an access token.
You can create your own application to request this API very easily. This can be done using an API token generated by the user account or by using an OAuth application to connect to Oncrawl using the user’s account.
Using our API, you can write applications that make the most of Oncrawl’s many features, deployed in your own environment, using the programming language and platforms that you prefer. This means that you can create custom dashboards, integrate our data into other platforms and automatically trigger a crawl whenever a site is updated.
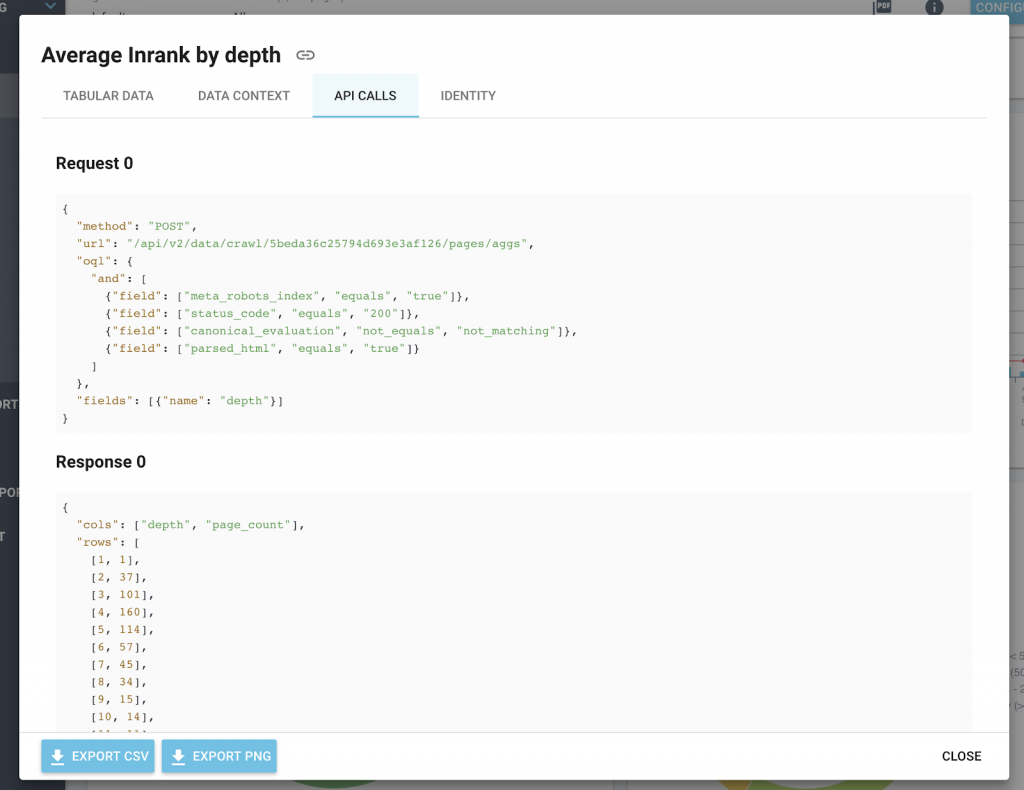
Also, to make integration easier for you, all our charts include the API calls and the response format in the information icon.
Trends and optimizations over time
Oncrawl organizes your crawls by date within your projects. We store your crawl data while your subscription is active, which means you can keep track of months or even years of analyses. Please note that if you use our Log Monitoring feature, the Oncrawl application handles personal data in the form of the IP addresses of visitors to your website. This information is required in order to distinguish reliably between Googlebots and other visitors. IP addresses are not stored in the Oncrawl application. This data only exists in the original file that you upload to your private, secure FTP.
We also offer extensive features that let you compare two crawls, based on the same crawl configuration, to spot trends and changes over time. This is a great way to compare a staging and a live version and check if everything has gone smoothly during the migration.
You can also share your projects with teammates or clients, which is a great way to prove the value of your optimizations and share results.
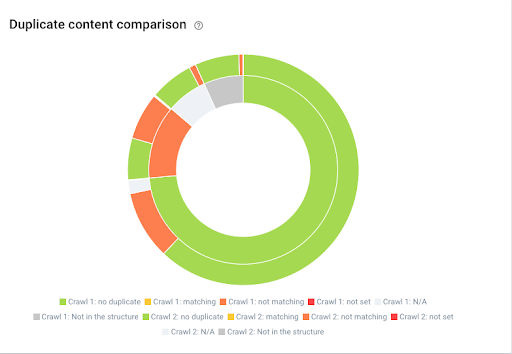
Showing the evolution of duplicate content between two crawl
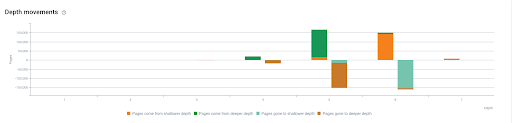
Showing the evolution of depth movements between two crawls
Semantics everywhere
Innovation is in our core DNA and we’ve been working on evangelizing technical SEO for years. With over 15 years working on natural language processing issues, Tanguy Moal, CTO at Oncrawl, has helped us merge semantic and Big Data technologies to make sense of the tremendous volume of data available on the web. We have achieved the first ever near duplicate content detector using the Simhash algorithm.
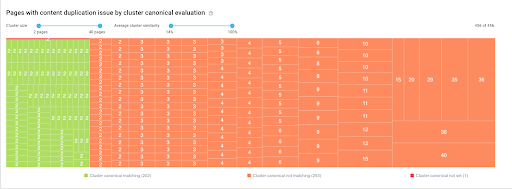
Cluster of similar pages with canonical evaluation – clusters can be filtered by number of pages or percentage of content similarity
We’ve also recently been working on a heatmap content detector that helps our users identify blocs of unique content and the percentage of duplication across web pages and a whole website. Semantics are part of our SEO crawler: n-grams analysis has been available from the start to help you understand how sequences of words are distributed within a website. We’re the only cloud-based crawler with such semantic capabilities. In an area where conversational search queries are rising, semantic SEO helps you improve the traffic to a website through meaningful metadata and semantically relevant content that can unambiguously provide an answer for a specific search intent.
Oncrawl is much more than a desktop crawler and offers unparalleled and cloud-based SEO analysis at scale. Oncrawl allows you to act to really understand how search engines behave on your website and to create a SEO strategy with confidence.
