
Oncrawl is excited to announce that all users have been progressively migrated to an all-new crawler during the months of February and March 2019. Our favorite aspect of the new Oncrawl crawl technology? The out-of-this-world speed.
We’ve also taken advantage of this core update to include a constellation of new elements, including real-time crawl monitoring details and expanded data for link analysis and non-indexable pages.
New crawler, identical crawl features
This major improvement to the Oncrawl crawler produces identical crawl results. All dashboards, features, and available data are fully supported by the new crawler.
This allows you to seamlessly compare new crawls to old ones without worrying about skewed data or requiring adjustments.
There are no differences in the Oncrawl dashboards and charts. Their appearance and the calculations used to produce them have not changed. The change in crawler does not produce different numbers in the charts.
Warp speed: faster crawling
Faster lift-off
Your crawls now get off the ground with a shorter countdown and a more powerful blast-off.
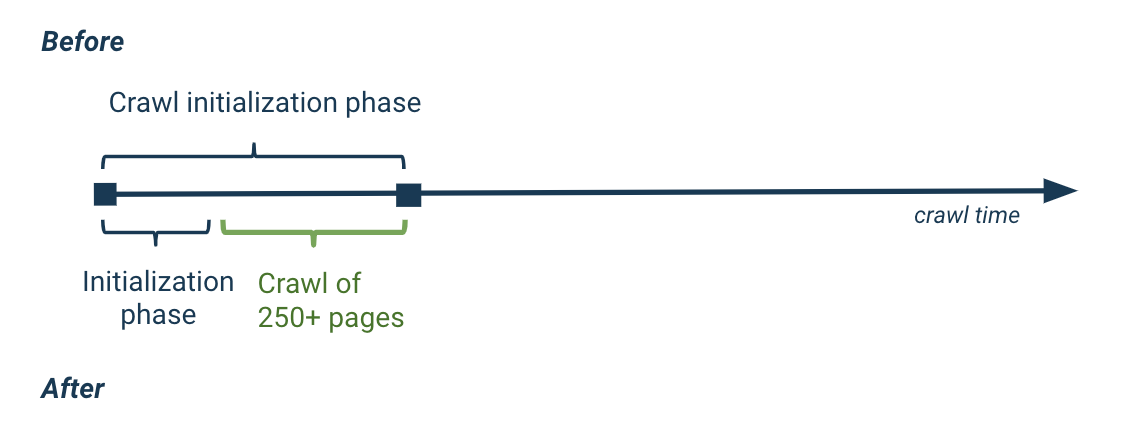

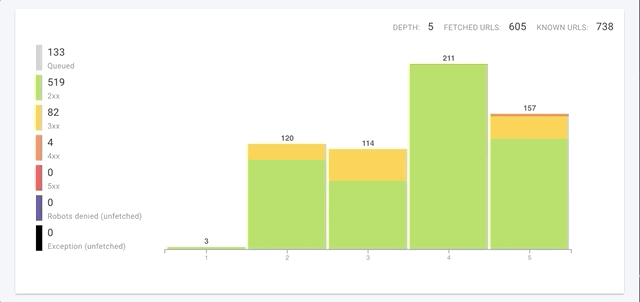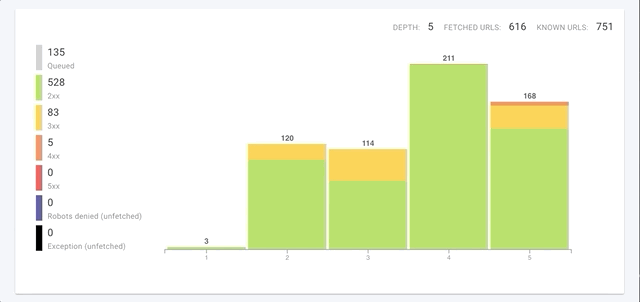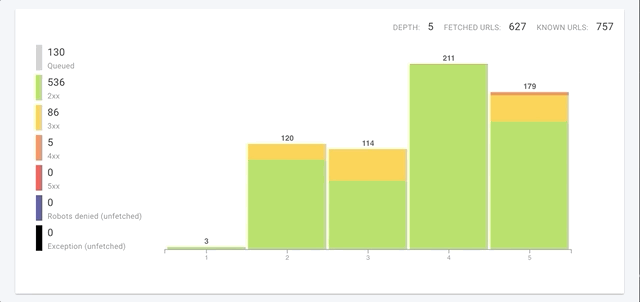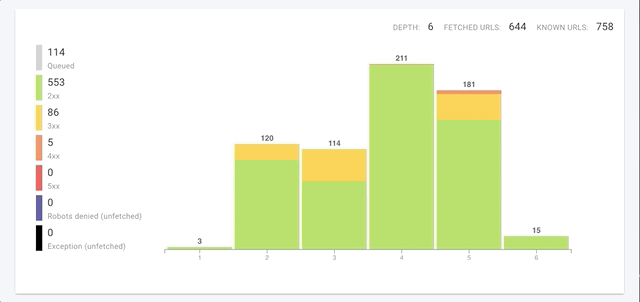
Not only does the crawl initialization phase take significantly less time, but you can also use the improved crawl monitoring page to see what’s happening during this period, even before the first pages are crawled.
On the crawl monitoring page, you can follow the progression of the different pre-crawl tasks, and then track precise numbers, refreshed in real time, that let you know exactly how (and what) the crawler is doing.
Faster crawl speed
Your crawls also get a continuous boost to their speed throughout the crawl. Larger sites will see enormous reductions in the time it takes to crawl a site, but even sites with under a thousand pages can see increases of 8x in crawl speed.
Not only do we crawl each page faster, but we’ve improved global crawl speeds through improvements in three key areas:
- We’ve parallelized crawl tasks.
Because multiple tasks can be carried out at the same time, the overall crawl speed is much faster. - We’ve removed the need for pauses during the crawl period.
Without pauses, the crawler is now able to respect the crawl speed you requested, for an overall shorter crawl time. (This means you may need to make adjustments if you’ve found the fastest possible speed that is just short of asking too much of your web server.) - We’ve rewritten the algorithms for incrementing depth during a crawl.
In very large websites, for example, deep crawls could take over an hour to progress from a depth of 10 (or N) to a depth of 11 (or N+1). With the new crawler, depth changes are smoother, even at the deepest levels of gigantic websites.
Faster reaction times
The new crawler benefits from an improved time required to pause or stop a crawl. Because of how data was treated and stored, pausing a crawl could take a while after you pressed the pause button. With the new crawler, it’s nearly instantaneous.
If you need to pause or cancel a crawl, you can now do it in a matter of seconds at most.
Upgraded crawl monitoring
Oncrawl’s crawl monitoring interface received a facelift before the release of the new crawler. With the new crawler, however, there’s a galaxy of differences in crawl monitoring.
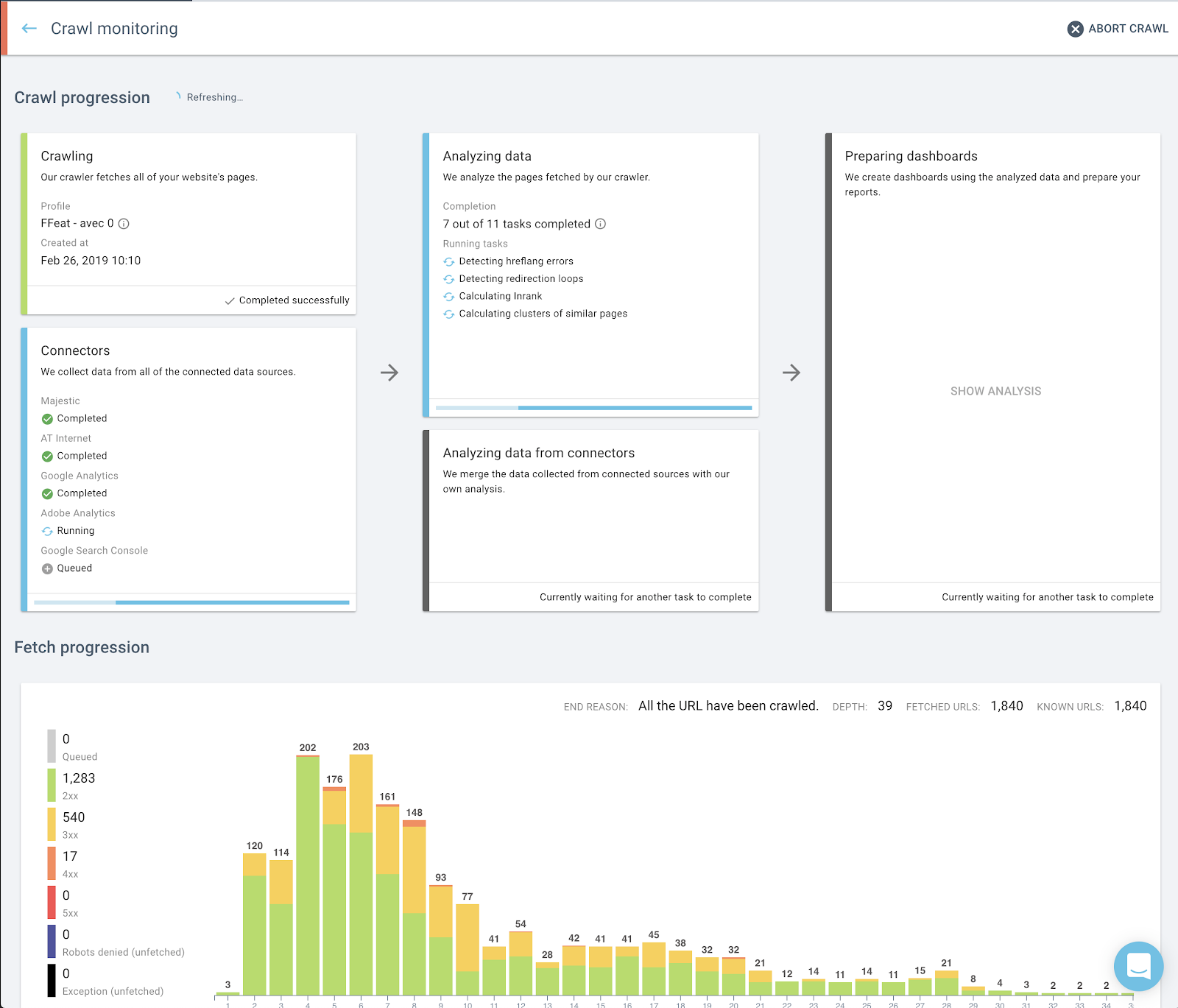

The upgrade includes:
- More information when connected accounts are slow to respond or when the information requested can’t be obtained. This can occur, for example, when you don’t have enough quota left on your connected third-party account.
- More real-time information on crawl errors on a page
- Ability to view the progression of a crawl during the analysis phase
What else is new?
More information for more URLs
The new Oncrawl crawler pulls information for all pages in HTML format, regardless of their indexability or their HTTP status code.
Previously, page data was only available for pages with a 200 status and for indexable pages. The new information is available in the Data Explorer and URL Details tools, as it generally concerns only pages that are not included in Oncrawl dashboards and charts. This includes the wordcount, title, meta description, headings (H1-HN), n-grams, Open Graph and Twitter cards–and more.
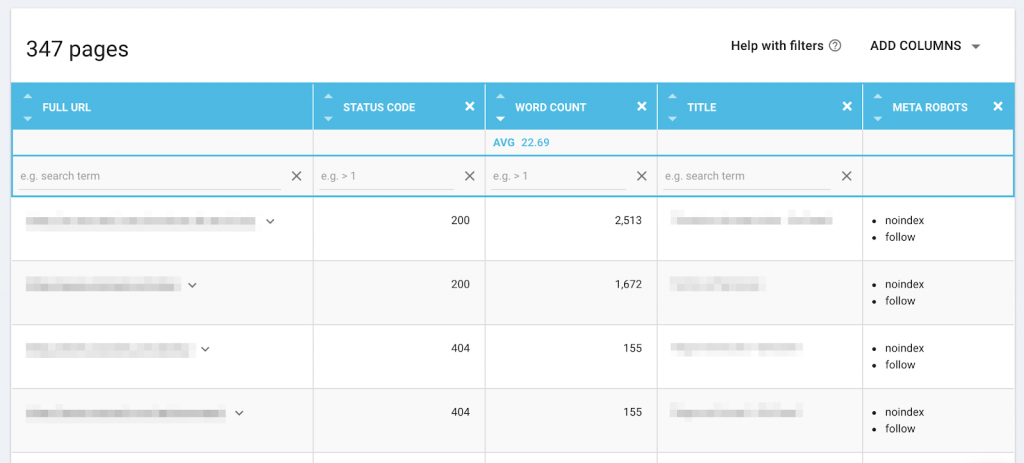
In the URL Details, under “View source”, the full source code, including the complete page headers, is available for all pages.
Pulling data for additional pages also helps Oncrawl to find more links and to improve the similarity between our crawler and googlebot. For example, Oncrawl previously disregarded the content of pages with a 3xx status, despite evidence that Google may follow links on this type of page. Oncrawl is now able, like Google, to crawl links on pages with a status other than 200.
The fact that additional links are found and additional pages are analyzed means that the total number of pages in the Data Explorer may be higher than the numbers you previously saw for the same site. For example, on a redirected page, we might now discover links to new pages. Even if these new pages happen to be non-indexable, they’ll be counted in the total number of pages in the Data Explorer.
Expanded outlinks analysis
We’ve improved the crawler’s ability to identify and follow links leading away from a page. Oncrawl’s crawler now takes the following links into account:


New (and improved) Data Explorer fields
We’ve added fields related to the Oncrawl bot in the Data Explorer:
- Sources: How does Oncrawl know about this page? We’ll let you know if our bot found it, if it’s listed in your sitemap, and if connected datasets reference it.
- Fetch date: the date and time at which our bot requested the URL.
- Fetch status: the result of our bot’s attempt to fetch the page. The value “success” means that the Oncrawl bot received a response from the web server: even if the server response itself indicates a page or server error, our bot was successfully able to obtain this information from the server.
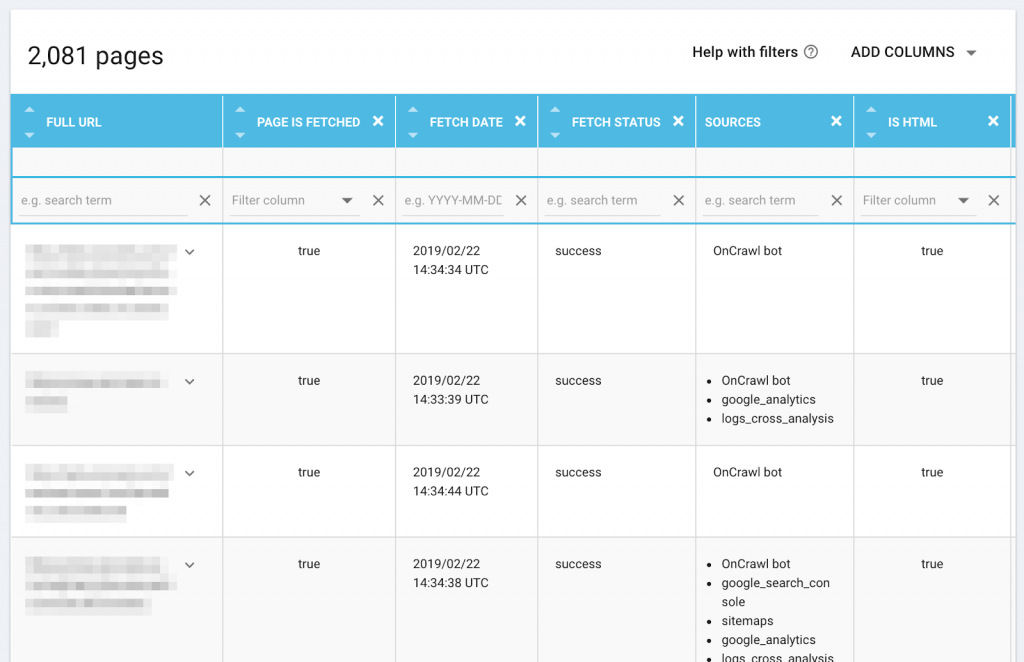
We’ve also improved reporting for certain fields that used to report default values. This gives you more precise information for all of your pages. For example, the Metarobots field in the Data Explorer defaulted to indicate that robots were authorized when no contradictory information was present. Now, the Metarobots field displays the actual value of the “meta robots=” property for the URL. If the property is missing, the field is left blank.
How to get the new hyperspeed crawling for your Oncrawl account
The new crawl scheme will be rolled out progressively to all new and existing users without any action required on your part.
If, however, you’re still using the old version and want to jump to the front of the upgrade line, please feel free to reach out to your account representative or to contact us via the blue Intercom button at the bottom right of the screen when you’re signed in to the application.
