
If external links (backlinks) is one of the areas of improvement that is often mentioned to improve your SEO, internal linking is often overlooked, but is also important. In fact, a good internal linking structure can make all the difference in very competitive sectors.
If, for a small site, defining the most important pages to link first can be a relatively easy task, what about sites with thousands or even millions of pages?
In today’s article, I will explain a methodology you can apply to your project in order to determine the priority pages.
N-gram analysis of our keywords
First, we need to understand what keywords are most often used to search for our product or service. If you’ve ever opened a Google Search Console report, you’ll probably have noticed that many keyword structures can exist. For example, for the purchase of a flight between two different cities, let’s take Lyon and Barcelona, the searches may be :
- Flight lyon barcelona
- Flight lyon barcelona
- Cheap flight lyon barcelona
- Etc.
Having this type of plurality of keyword structures is not specific to the travel industry, and you probably have a similar situation in your own industry.
However, it is essential to know which structures are the most used in order to be able to carry out our analysis correctly. How can we do this? Simply by performing an n-gram analysis (sequence of N words used as a keyword) of our own Google Search Console data.
Before explaining how to do this, let me clarify one thing: unfortunately, Google Search Console data is not perfect.
[Case Study] How business-oriented SEO increases traffic and conversions

Limitations
Before we start our analysis, we need to be aware that the metrics displayed by the tool when you include the “query” dimension only represent 30-50% (the exact figure will depend on your site) of the total displayed if you include the “page” dimension, for example.
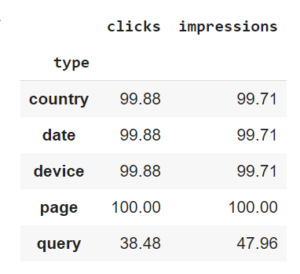
In other words: the tool suffers from dimensional sampling. This means that the metrics returned by Google Search Console will be different depending on what you are analyzing (queries, pages …). I should also point out that I obtained this data using the API, i.e. by interacting with all the data available, instead of through the interface that everyone is familiar with, which only allows you to analyze a maximum of 1000 elements.
If you work with Python, you can read the official Google documentation or, even better, use this library which will save you a lot of time. I use it myself on a regular basis.
That being said, Google Search Console is still more exhaustive than any other third party tool such as SEMrush, SEObserver, Ahrefs or Sistrix, to name only the best known.
Methodology to obtain your n-grams
In order to obtain your n-grams, you need to follow this procedure:
Download your Google Search Console data
It is important to download your data for a single vertical. As the n-grams of a Flight section and a Train section of your site will probably be different, if you mix your data, you might obtain n-grams valid only for the most-searched vertical.
If your site is new or if it rarely appears on the first page, I recommend that you use an additional data source.
Remove variables
In some cases, you may need to remove some of the elements in these keywords. For example, let’s suppose that my list contains only 4 keywords:
- Flight paris rome
- Cheap flight paris rome
- Flight lyon barcelona
- Cheap flight lyon barcelona
I want to obtain n-grams in the form of structures, containing variables. Here, for example, I want to keep only: flight {{origin}} {{destination}} and cheap flight {{origin}} {{destination}}, without the cities. In your case, you may have to replace the name of your products, the size, etc… It will depend on your industry.
Calculate n-grams and retrieve search volumes
You can use whatever system you prefer: In my case, I use Python, which has the advantage of being simple and can handle the amount of data we have on a regular computer (without crashing it).
#import libraries
import collections
import nltk
import numpy as np
import pandas as pd
#create a list of unique keywords
list_of_keywords = report['query'].tolist()
#create a list of words contained in these keywords
list_of_words_in_keywords = [x.split(" ") for x in list_of_keywords]
#count the most common ones
counts = collections.Counter()
for phrase in list_of_words_in_keywords:
counts.update(nltk.ngrams(phrase, 1))
counts.update(nltk.ngrams(phrase, 2))
You can also use Oncrawl’s native function to analyze your content and discover some n-grams that don’t appear in Google Search Console (yet).
Then, you’ll need to retrieve the search volumes for each of these structures, to get a table like the one below. This table shows the most common structures: the ones that have the highest number of impressions for our vertical.
| query | count | impressions |
|---|---|---|
| Flight {origin} {destination} | 50 | 167000 |
| Cheap flight {origin} {destination} | 676 | 30000 |
| Ticket {origin} {destination} | 300 | 97000 |
Good job for making it through to this stage. I can tell you want to know what we will use this information for. The answer is in the next part ;)
[Case Study] How business-oriented SEO increases traffic and conversions
Extracting search volumes
Let’s remember that our goal is to define the most important pages to link to first.
In order to understand which pages have the highest potential traffic, we need to retrieve the search volumes of the different most common keyword structures, for each page. We will only take into account the search volume here; the notion of CTR will come later!
Are you starting to understand what the previous step was for? In order to gain efficiency, the use of an API is mandatory. Many solutions, most of which are paid solutions, exist. If you use DataForSEO, obtaining volumes for 350,000 keywords will cost you less than 40€, so we are not talking about a significant investment either.
At the end of this step, you will have a file with the potential volume per URL. This is the sum of the volumes of the most common n-grams calculated in the previous step.
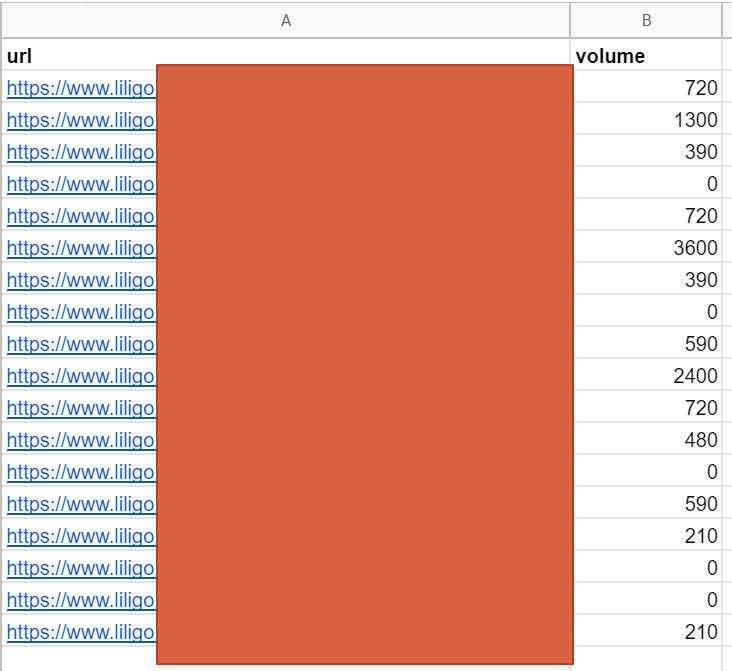
Merging the data
At this stage, we obviously cannot use this data to prioritize the most important pages of our site. Why not?
Let’s not mix volume and traffic!
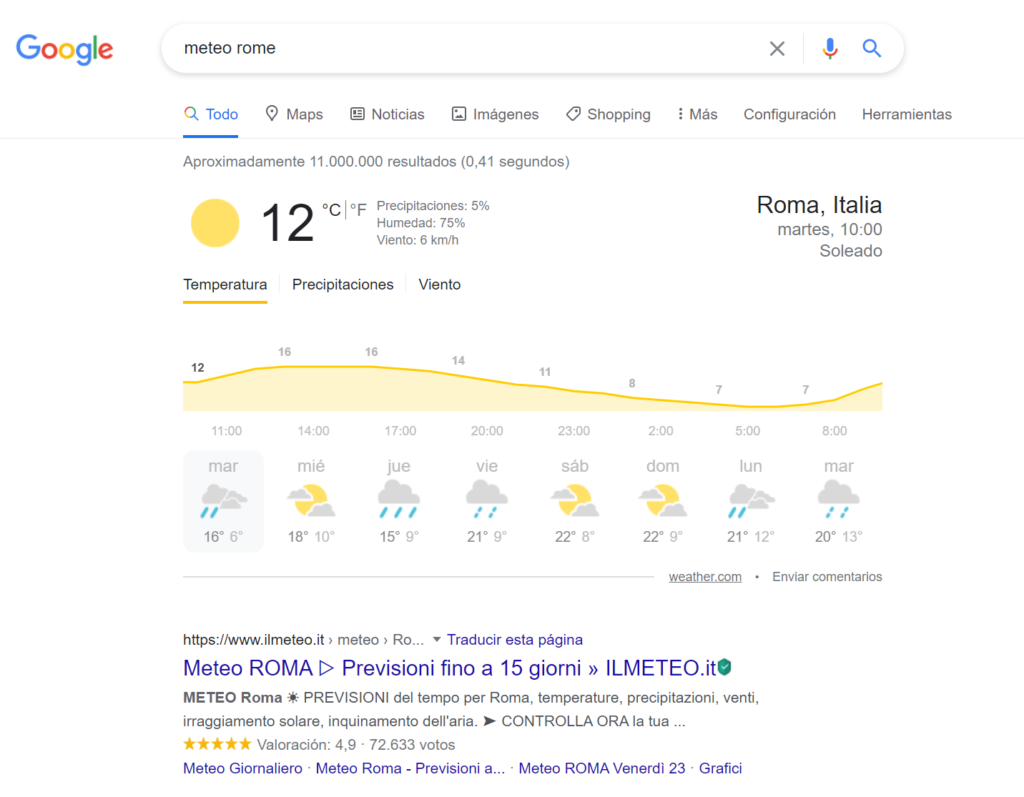
In some cases, even if you are in first position, your CTR may still be low. This is often due to the number of ads and SERP features displayed by Google above your page. Here is an example on a weather query where the first Google element strongly attracts the user’s attention long before the user can reach the first organic result.
Limitations of n-grams
The importance of long tail keywords can vary depending on the sector. The structures that would not have been retained in the first step (or are hidden by Google Search Console) could nevertheless represent an interesting part of the potential. We must therefore include them.
Importance of each page
As an SEO expert, our goal is not to generate traffic, but to generate sales through search engines. It is therefore crucial, if you can, to complete this analysis with data from your sales department. For example, data on the sales margin could help you determine which URLs you should prioritize.
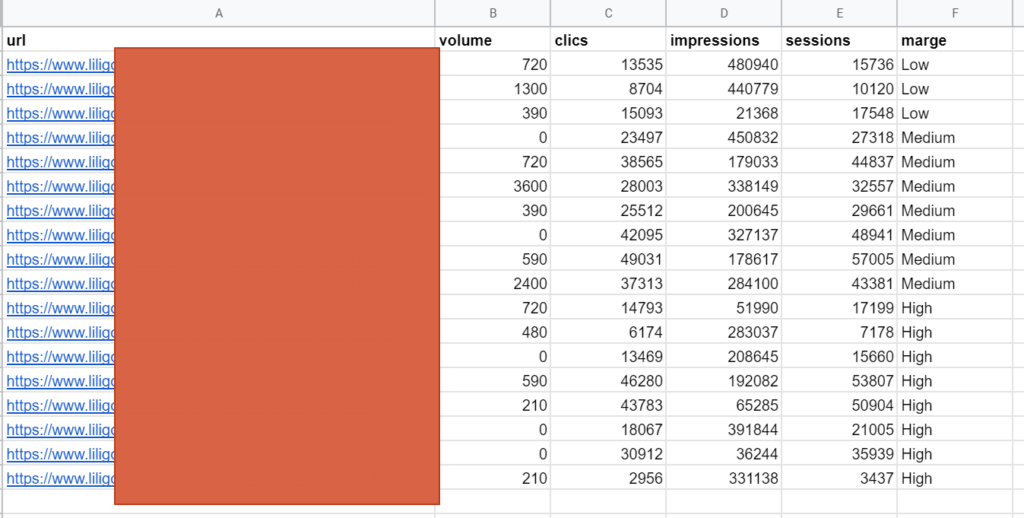
Let’s take the table from the end of the previous step, and add other data that it can be useful to measure:
- Potential exposure (volume / impressions)
- Actual traffic (sessions / clicks)
- Revenue (conversion rate / margin / revenue)
Here is an example of how to present this table:
Weighting the data
In order to classify each different piece of content according to its potential exposure, potential traffic and revenue, you must decide how much to weight each of these elements.
I cannot propose standard percentages; it is up to you to define the percentages that will suit your own situation.
Standardization
Please note that we cannot yet define the importance of each of our pages. The result we obtain by weighting the data that we obtained earlier is not yet valid.
Explanation: By definition, impressions will be higher than clicks and sessions. This is especially true in industries with low CTRs. Without processing our data beforehand, we risk overweighting impressions (and underweighting sessions).
How do we solve this problem? By standardizing our data! This process allows us to resize the numerical variables so that they are comparable on a common scale (source). Through mathematical manipulation, our quantitative data distribution will have a mean value of 0 and a standard deviation of 1.
If you are curious, the mathematical formula is as follows:
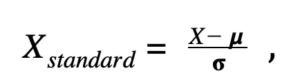
X_standard = standardized value
X = initial value
μ = mean (average) of our distribution
σ = standard deviation of our distribution
It is very simple to apply this formula to your data:
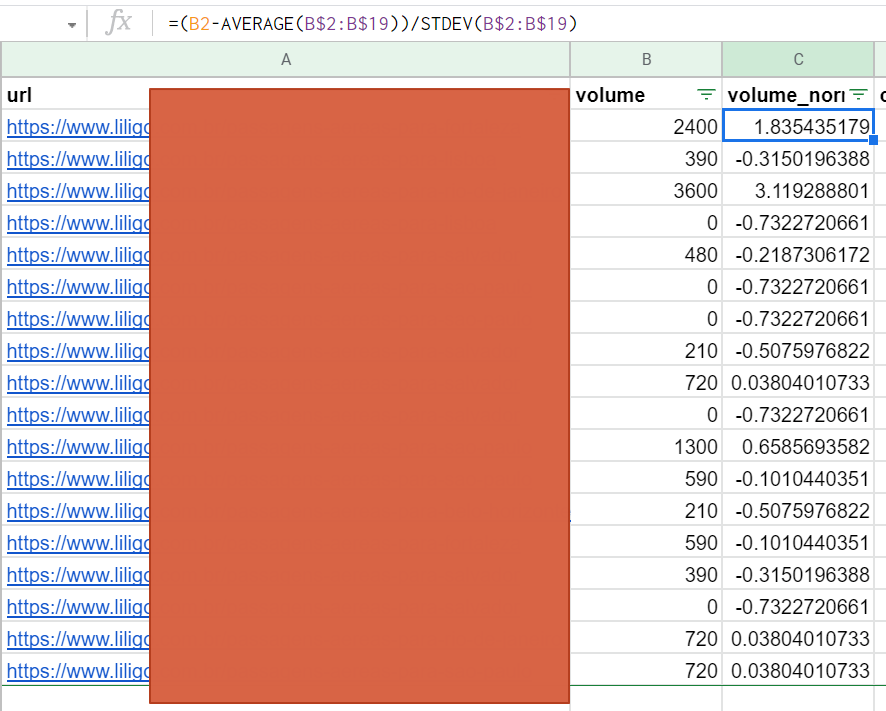
Apply this formula to all the data you want to consider in your calculation. This will definitely eliminate the problem of overweighting a metric.
Calculating the score
Once you have defined your weights and calculated your standardized values, you can assign a score to each of your URLs to determine its importance. In this example, we have 4 metrics, each weighted equally at 25%, but you can obviously use other numbers.
This methodology therefore allows you to place a URL first that is objectively the best: a lower search volume, but high impressions, and above all an impressive CTR.
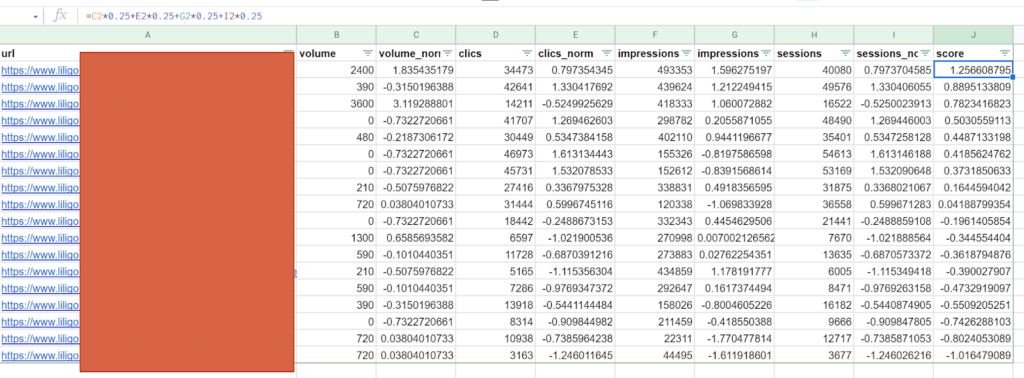
With this information, you’ll be able to define your internal linking structure in a much more comprehensive and relevant way than if you based it on a single criterion, such as search volume. It’s up to you to link:
- From the home page: the most important pages
- From a category: the most important pages of the category in question
- And so on.
Conclusion
The n-gram methodology is efficient and has the advantage of being applicable to many projects. You just need to adapt it by using the most important data of your industry. Despite the use of a mathematical concept that may be new to some (standardization), it is also simple to explain and to put into practice with the tools you have at your disposal.
It will provide you with the necessary information to build your internal mesh based on the potential and results of your pages. A task that is sometimes complex to obtain for large sites.
All you have to do is apply it!
