
Why is crawl budget important?
Search engines need to perform the process of crawling and indexing sites correctly in order to effectively determine SERP rankings. Here is where crawl budget is important: this term refers to the number of pages Google examines on your site during each crawl.
If you have a small website, you probably don’t have to worry about the crawl budget too much. However, if you have an E-commerce or mega site with more than 1,000 unique pages, you’d better start to optimise it with the budget in mind.
The great content case
At greatcontent, we provide multilingual content production services in over 30 languages and variations. Our 1,000+ clients and the members of our large freelance author community are based in many different countries and speak different languages as their mother tongue. This means our website must effectively serve several countries (or at least those of our high-value languages) and we must manage the crawling and indexing processes by the search engines for the different language versions and their many pages.
Currently, we are in a transition process. We recently released a new version of our website which is only available in three languages, and we are working on creating new content for all the languages of the countries we target. This means having a large number of pages (essentially, one version of the site for each language) that must be indexed by Google. This is where crawl budget becomes crucial. So what should we do to ensure it is used in the most effective way?
How to detect crawl problems using Oncrawl
The first thing we need to do is gather as much information as possible.
1 . Adding data sources
One of the advantages of Oncrawl platform seo is that it allows you to integrate various data sources in order to gain a global view of what’s happening on your site.
You can then connect all the information from the different sources such as Google Analytics and Google Search Console. Best of all, you can integrate third-party data tools like SEMrush (via CSV files) and Access Log files that give you the data pertaining to the access that both Google and your users have to your site.
Want to know more about how to connect external data sources? You can watch this video:
2. Log monitoring
The log analyzer of Oncrawl is definitely one of the added-value features.
You can easily add information from your server’s Access Logs. Oncrawl provides you with an FTP account which allows you to import the Logs files from your server into your Oncrawl project.
You can see how this information is combined in this video:
With Oncrawl, you have two options when importing Access Logs:
- Upload them manually (you’ll have to do it for every date you want to have data for)
- Include script in the source server so that Logs are sent automatically.
In our case, we needed to know if Google was continuously accessing the least relevant pages (most of them portfolio pages). Search Console showed us that this was the case and gathered information to help understand why.
3. Third Party Data
As we’ve already said, Oncrawl allows you to cross-reference data from all the analytical tools you can imagine. For this, you can simply use a CSV file (in the indicated format), which allows you to process your tools’ data. For example, you can upload the typical SEMrush visibility tables that show the keywords you have positioned, the positions they occupy, monthly search volumes… pretty much everything.
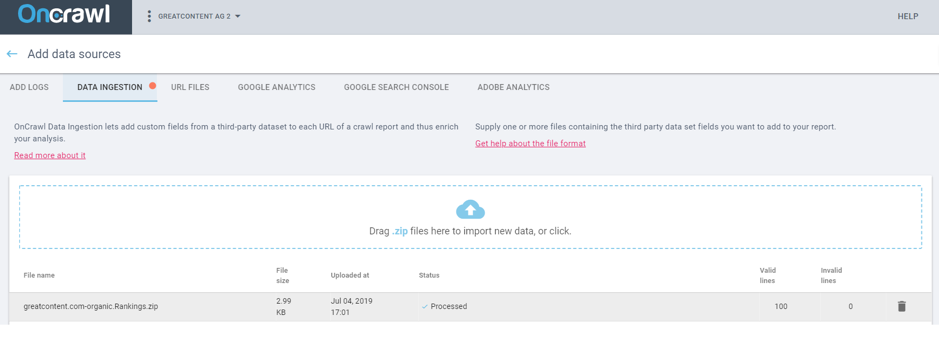
Image 1- Third party data
4. Crawl Report
After adding all the data sources to collect as much information as possible, we can launch a trace and look at the result in the Crawl Report function.
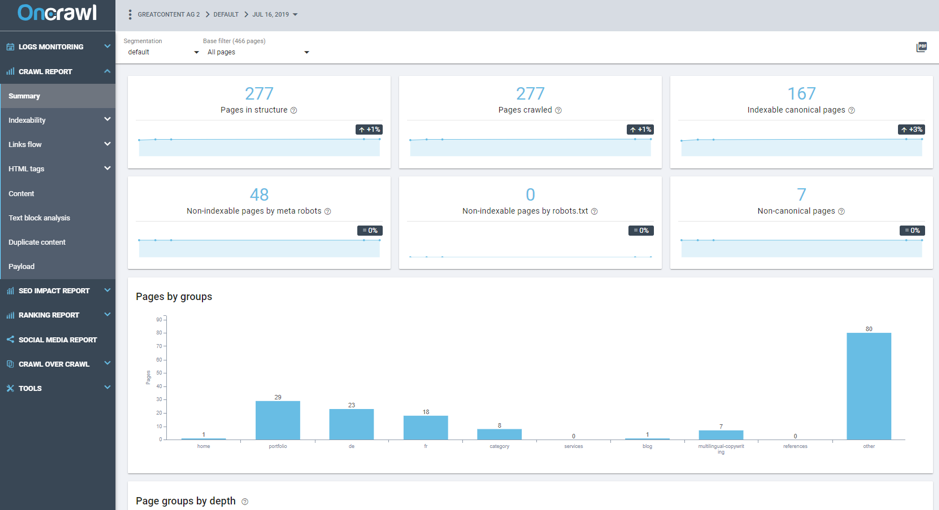
Image 2 – Crawl Report Summary
One of the most interesting functions is the one which allows you to see the ranking value of incoming links (Page Rank) by depth levels.
Curiously, we had many pages with high average values of Inrank at a depth level 4 (too deep), most of them portfolio pages, which aren’t so relevant.
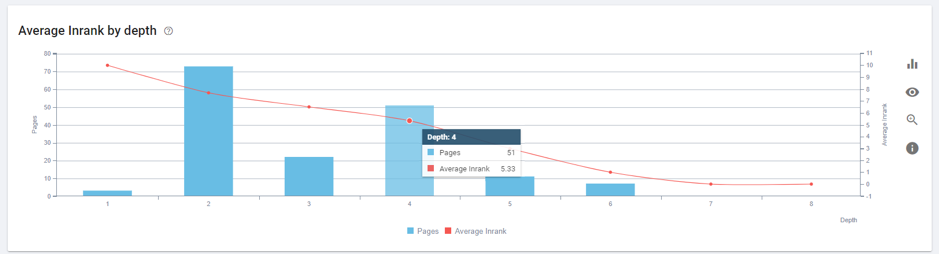
Image 3 – Average Inrank by depth
Another fundamental data point of the Crawl Report is Status Codes. It tells us about the server response that the robots find.
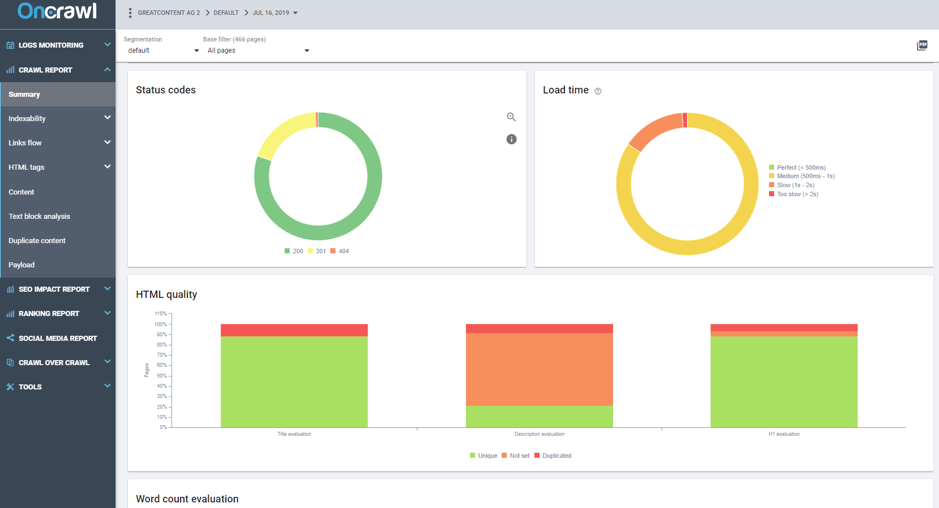
Image 4 – Crawl Report Status Code
On our website, almost 20% of the crawled pages had a 301 code. This means we were wasting 20% of Google’s and other bot’s access and we had a lot of internal links which should have been replaced.
5. SEO Impact report
Finally, you should look at possibly the most important indicator when it comes to crawl budget: the SEO Impact Report. This gives us a detailed, comprehensive overall report which allows us to see all the relevant information at a glance.
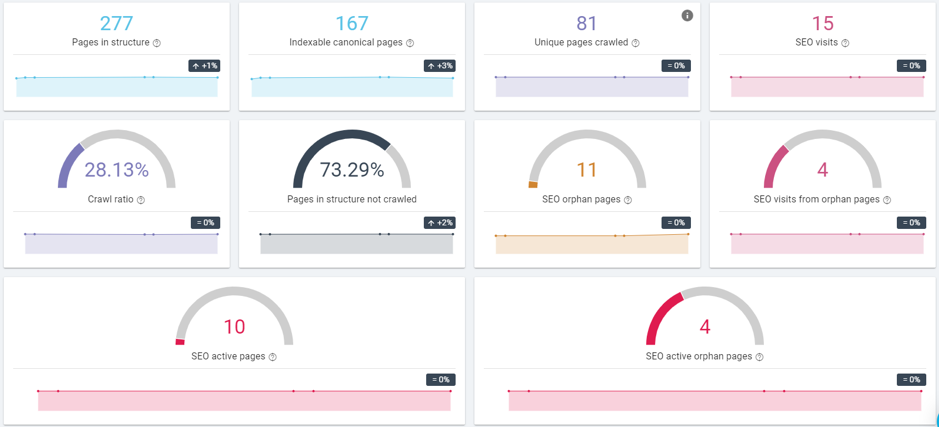
Image 5 – SEO Impact report
Here, we can see all the relevant insights from the data based on the information in the Access Logs for a given date.
- Only 81 of the 167 indexable pages were crawled by Google – less than half.
- Less than 30% of the pages known to Oncrawl were crawled by Google.
- Google was crawling inactive pages daily, almost two times per crawl on average.
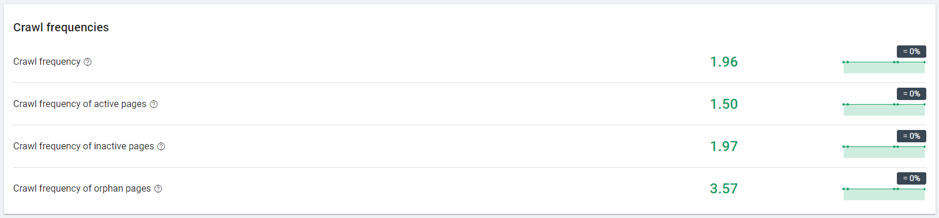
Image 6 – Crawling for inactive pages
Conclusions
According to Search Console, some of the pages that had appeared recently in search results on Google were less relevant pages to us.
In fact, they were pages that, in earlier versions of the website, had been used (and linked) frequently but which are currently less relevant; for example, the portfolio pages (examples of texts for each language and industry).
The best thing about Oncrawl is that it gives you all the detailed information for each URL – not only the SEO improvements of the page itself and the indexing values (something that Search Console offers you as well) but also information about architecture (popularity of that URL within the page, links you receive, redirects, etc.)
Thanks to Oncrawl, we noticed several issues regarding page crawling by search engines:
- The most important pages of the site are not gaining authority because we have a large number of internal links pointing towards irrelevant pages instead of the most important ones.
- Many of the links are not direct links but are links that are pointing to a redirect. You may know that when Google arrives at a page and receives a 301 code, it adds this URL to a list for future crawls. Therefore, it does not track them directly and we miss the opportunity for Google to crawl the page in that session and, in turn, waste some of the crawl budget.
- Redirect loops. There was a link that should lead to a more general category, but it actually led to a URL that did not already exist which included a redirect to the page itself.
- We also discovered other pages where internal links were continuously pointing to content with a redirect.
All the Oncrawl tools gave us valuable information to help us keep improving the new version of our website and to avoid replicating mistakes in future versions in new languages.
If these tools are useful for any typical corporation site (or a smaller site), you can surely imagine how essential the tools can be for E-commerce sites, where the number of pages that make up the website architecture is very large and the waste of crawl budget can be significant.
