
The webinar Creating entity-based content that converts is a part of the SEO in Orbit series, and aired on May 15th, 2019. For this episode, Oncrawl Ambassador Murat Yatağan and JP Sherman dive deep into the question of how to create content that machines understand in order to increase rankings, CTR and conversions. Join us for insights on how to build content for SEO in 2019.
SEO in Orbit is the first webinar series sending SEO into space. Throughout the series, we discussed the present and the future of technical SEO with some of the finest SEO specialists and sent their top tips into space on June 27th, 2019.
Watch the replay here:
Presenting JP Sherman
JP Sherman is a 10+ year veteran of Search, Findability and Competitive Intelligence. He works as the Search & Findability expert for the Red Hat Customer Portal, where his responsibility is to bridge the intention gap between tens of thousands of technical and support documents and the customers looking for them in Google and Red Hat’s internal search platform. He has found a natural talent to connect data, behavior, search and findability to bring actionable changes and value to Paramount Studios, Skechers, Performance Bike, Dewalt and many more.
You can find him on Twitter @jpsherman where he enjoys talking shop, non sequitors and other geeky endeavors.
This episode was hosted by Murat Yatağan, an SEO Consultant with more than 9 years of expertise on SEO and UX, of which 5 years derives from his Senior Product Analyst role at Google Search Quality Team (aka. Trust & Safety) in Ireland. During his consultancy career he built expertise on technical SEO, high quality content creation strategy, outreach and international SEO throughout managing 65+ clients globally from various business verticals.
What are entities?
To put it very simply, entities are things that have attributes. For example, a dog has attributes like legs, a heart… When you dig deep into entities, it’s the attributes that really define and differentiate the things described as entities.
These aren’t always concepts. Brands can also be entities, because of their association with products and with other “things”.
What makes entities interesting, is that attributes are shared. A dog and a cat have shared attributes.
What is structured data?
Structured data, as the name suggests, is information that is structured and organized on a page to help search engines to understand what the page is about. It can also help visitors to your website, because on the front-end, you also use structured data to organize your information: lists, tables…
Search engines, unlike human visitors, use construct knowledge graphs based on entities, and to define relationships between these entities.
For example, Google uses structured data to create new elements in search results, such as the Q&A page and FAQ pages. More generally, these are known as rich results. They can give you an advantage in the search results by making your results more prominent on results pages, as well as other advantages.
What is Schema.org?
Schema.org is a standard developed by a consortium of major search engine players including not only Google but also Bing, Yahoo!, Yandex, and others. These are definitions of how to build structured data in ways so that search engines can understand them better.
It provides the rules and structure of encodings to be used. The full standard is available on the project’s website, Schema.org, where you can find full details and help with markup types, such as JSON-LD.
Biological constraints on how people search
There are biological constraints on how people search. This is essentially a two-part answer about how people access information, and then how they recognize and follow that information to meet a search intent.
Accessibility
The first part of a biological constraint on search is accessibility. Physically, not everyone can consume information in the same way. A basic example: not everyone sees colors in the same way.
The search audience is one with variations in how they can consume information. So things like text size, color, or location are extremely important to the idea of findability, or how people can access search and search results.
Google has implied that there are strong correlations–though not necessarily causations–between ranking and how accessible your site is. This goes back to E-A-T (Expertise, Authority, and Trust), which Marie Haynes has been talking about a lot recently. The more accessible the site is, the more it gains in authority and trust.
Pattern-seeking behavior
The second part of the biological constraints on search is that humans are essentially pattern-seeking animals. We see patterns when there are no patterns.
For example, take the term paradoia: humans see face-like patterns where there aren’t any, such as in the bark of a tree.
In fact, we look for data; we look for patterns. We’re not just pattern-recognizing, but also pattern-searching.
When it comes to search, there are concepts and biological aspects concerning how humans interact with their environment, or even a web page, that apply to search. The way that people scan for information is fairly predictable; the way we recognize information is fairly predictable.
Because entities are recognizable things, they stand out as pattern signals. Someone searching for information who encounters, say, “Batman” will suddenly understand associations already built around this entity:
- A location
- Friends
- Enemies
- Movies
- Media
- Etc.
This coalesses into entity recognition. When a user recognizes something as an entity, it creates what we call an “information scent trail”. This means that the user starts to focus on the entity to start to see whether or not there is a relation to what the user is searching for–in essence, the search intent.
A lot of human search behavior is based on entity recognition from a human perspective, and pattern recognition through pattern searching.
Before machine learning was in vogue, Murat worked on research on neural networks; he believes that a better understanding of how humans search for and recognize information is extremely valuable to research driving how machines perform and facilitate similar tasks.
Recent evolutions in search engines
There have been a lot of evolutions in search engine technology: neural search, natural language processing, better understanding of content and queries, and fighting against spam. Part of this is driven by the high number of queries that are new and that have never been seen before.
Some of these have a big impact on how we find information. There have been a significant number of changes by Google that influence the idea of search and findability; JP discussed only a few.
Understanding individuals and their patterns
Search engines have made huge advances in understanding each individual searcher and their patterns of search behavior.
For example, when JP leaves to go to work in the morning, Google lets him know that it’s going to take him 10 minutes to get to his favorite café, even though he has no digital interaction with this particular café, but “his phone” knows that he always stops there. This is an example of non-input learning feature.
The point is that Google’s ability to be aware of and to understand context in a predictable and displayable way allows them to present results before a searcher formulates a search request. This allows Google to provide non-interruptive information.
Accounting for context
Dawn Anderson, who is one of the brilliant people in the forefront of the field in SEO information retrieval and findability, recently quoted linguist John Firth, saying that you can tell what a word means by the company it keeps.

This is true about entity recognition, and about keywords. In the past–and the habit has lingered in some areas of SEO–we tended to treat keywords as a context-free bag of words. Too many SEOs focused on this tactic. But as even search engine algorithms begin to contextualize words and searches, it is necessary to understand that words mean more things in context:
- Words are associated with other words
- Words are associated with entities
- Words can be contextualized through mobile location
- Words can be contextualized through past visits
This means that JP’s searches, for example, will be very different from someone else’s because his context is very different.
Applied to SEO, JP gave the example of how he used to do SEO for a large online bicycle company. The same keyword [bike tires] had a different meaning in Colorado Springs than in Los Angeles. In Colorado Springs, the intent was generally for mountain bike tires. In LA, it was road bike tires. However, the keyword itself was exactly the same: [bike tires].
Understanding that the same word can have a bifurcated intent within user groups depending context (in this case: location) was incredibly illuminating in content development, SEO, and in looking for a way to “click” on an emotional level to get the interests and the click from the SERPs.
SERP ranking and CTR optimization
JP tells the story of what he and the bike company did:
The site had never ranked for the term [road bikes]. JP looked at the SERPs, and all of the winners’ titles were formatted the same: “Road bikes – Brand” or “Road bikes | Brand”. JP found this very unappealing from a search perspective.
He changed just the title tag of the company’s road bike page to “Light-weight, fast bikes for the open road”. That led to the idea that what we’re optimizing for in SEO is intent and emotion.
Consider the fact that a user generally spends less than a second looking at each snippet. You need to capture their attention and give them an immediate perception of value. When a user is looking at “Road bikes – Brand” versus “Light-weight, fast bikes for the open road” (or, when it comes to kids’ bikes, “Affordable, durable bikes for kids”), this stands out because it captures two significant concerns. Optimizing for emotion and intent offers an immediate recognition of value from the SERP perspective.
Instead of keyword-stuffing, JP was able to optimize the click-through by using words to target the right intention. The result? Out-ranking major brands like REI, Target or Walmart for keywords they’d never ranked for before.
JP believes that the SEO battle of the future is going to be played out on the SERPs to fight for that immediate recognition of value. This helps reduce the difference between position 1 and position 4, if you can immediately convey, through words, the value from your content.
Difference between ranking with neural matching vs keywords
It’s important to recognize that Google is also evolving: Google is not only looking at the theme of your page and term frequency. They also have teams of engineers working on how the human mind works and how Google can satisfy the query intentions of human searchers.
This means that the type of content that ranks for a word-bag keyword and the type of content that ranks with Google’s neural matching algorithms isn’t the same.
Triggering neural networks for search intent
With the caveat that he doesn’t work for Google and doesn’t intimately know their algorithms, JP finds that, from his observations and tests, there needs to be a trigger for the neural network to recognize a level of context and entities.
For example, if a searcher is looking for [red shoes], that’s not an entity, and the searcher is probably in an e-commerce mindset. JP would guess that there’s a recognition factor from the keyword that leads to a high-level assumption as to what the searcher is looking for: are they looking for information? Are they looking to make a purchase?
Where the query [red shoes] is concerned, the algorithm is much more direct and much more discreet.
Google’s use of entities to decipher queries
However, with a query such as [how to repair carpet from water damage] or [movie that makes fun of Star Wars], there are multiple contextual concepts that need to be understood. In the second case, the first result is going to be Spaceballs.
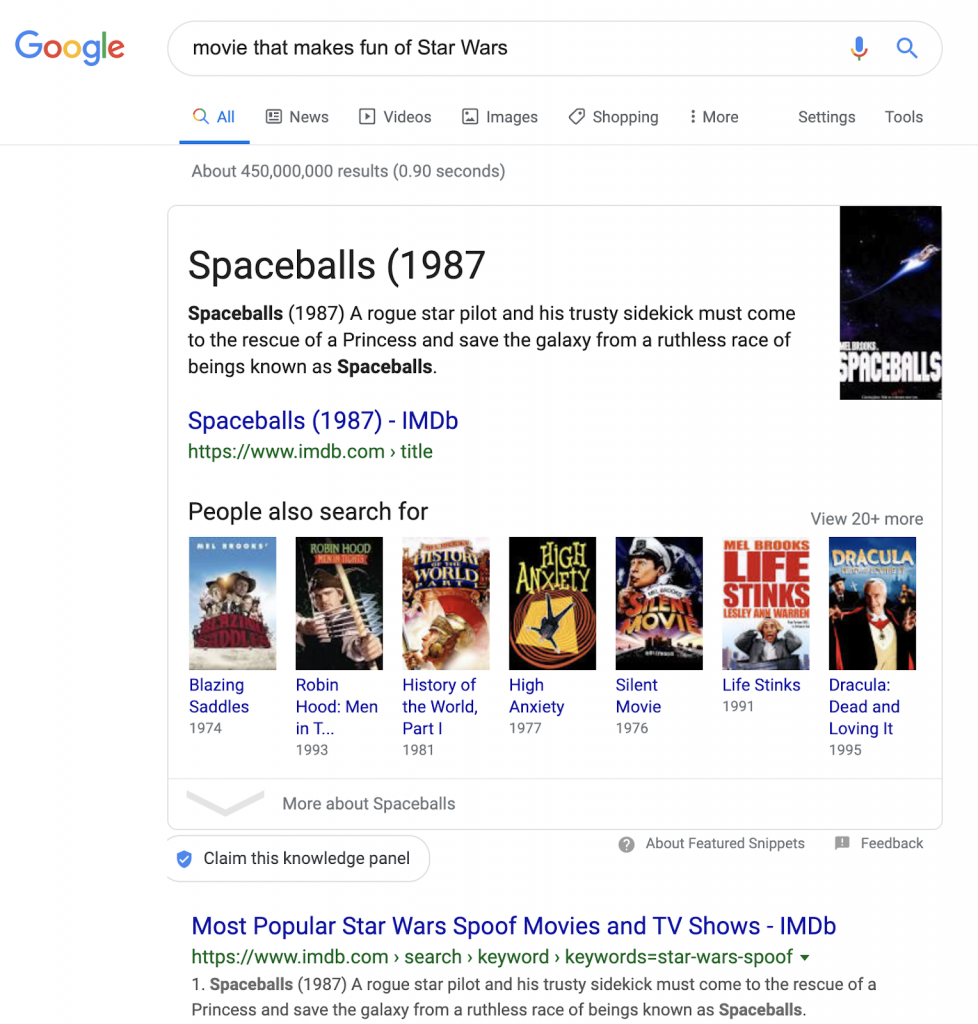
Google needs to understand:
- Movie (a type of media)
- “Makes fun of” (a parody: not the thing, but something like the thing)
- Star Wars
When we search for [movie that makes fun of Star Wars], Google is able to determine that we want a movie that isn’t Star Wars.
In other search engines, you still get Star Wars content–but in Google, you get Spaceballs.
To JP, this indicates that Google is doing some high-level parsing and high-level query-type recognition and is able to apply nuanced synonyms that have the ability to change the result.
Knowledge graphs
Several years ago, Google introduced the Knowledge Graph, built by drawing from Wikipedia and other sources.
Horizontal relationships of entities sharing characteristics
The thing about the Knowledge Graphs is that, using data provided through entities and Schema.org mark-up, it creates a horizontal layer of shared characteristics.
Whales, humans, gorillas, even bats: almost all mammals have five, three-boned fingers. That’s an example of a shared characteristic among different entities. Structured mark-up has given Google a means to access this type of horizontal relationship between different entities.
Filling template gaps
Knowledge Graphs were curated: there was an algorithm built to search Google for missing information in the entity templates. For example if there was no birthdate included in the Knowledge Graph for Morgan Freeman, the program would search Google to determine a consensus as to what Morgan Freeman’s birthdate was in order to fill in the Famous Person/Actor template for that type of entity.
[Case Study] Handling multiple site audits

Structured markup and machine learning
This is the sort of learning that structured markup helps with. JP likes to refer to structured markup as machine learning food.
Machine learning, despite the marketing hype around the term, can only work as well as it is fed. It has to consume data.
JP’s advice: If you’re getting a product that includes machine learning, you also need to evaluate the data it will be using–so look at the data on your site. What is that machine going to consume? Otherwise the improvements won’t feel hugely significant.
Murat’s experience is that, as machine learning algorithms are being built, the kind of data you are sending them is essential. Engineers consider questions like: are the signals coherent enough? Does the data make sense as a whole? Can you be confident in the results? Poor machine learning input reduces the quality of its output.
Structured markup to signal content to search engines
The level of visibility that you bring to your website with structured data is extremely important. If you’re able to give the right signals to search engines regarding what your content is about, there will be a significant effect.
If you provide ambiguous or messy data, though, using mixed-up application of structured data, you won’t see the same results: it won’t be very helpful to search engines.
Featured snippets
Google recognizes all sorts of types of structure in content. They also use content structure to create not only rich results but also featured snippets.
Present information in simple, clear ways
JP likes to use AJ Kohn‘s metaphor for Google’s intelligence: Google is like a clever [sic] five year old. They’re clever, but they’re also a little lazy, and limited in their understanding of the world.
When appealing to Google in order to capture featured snippets, explain content in simple and clear ways.
Support with structure and markup
Support your clear explanations with structure like ordered lists.
Eric Enge, from Stone Temple (now Proficient Digital) has done a lot of research on featured snippets and how to get them. Here are the basic takeaways:
- Answer a question clearly and concisely
- Organize your answer in a way that can be immediately recognized as valuable
- Support it with structured markup (not required, but helpful)
With regards to structured markup, it doesn’t help so much by unlocking the ability to get a featured snippet, but by allowing Google to obtain a better understanding of the concept or entity. This makes it easier for Google to match content on your page as an ideal response to a given search query.
Speed of understanding
The overarching concept that JP tries to promote is speed. You want a human to be able to understand what you’re talking about in under 1 second. If you can do this, you create the necessary information scent trail. The searcher will essentially follow the information because you’ve given them a piece of data that matches what they’re looking for.
This means that from a tactical standpoint, it can be extremely beneficial to focus on optimizing click-through-rates.
Use in voice search and new Google features
Structured data also helps voice and other devices to provide users with more relevant information instead of just offering random descriptions and titles that might not have been written in the best possible way.
There is also evidence that they might be helpful in new things released by Google and other search engines. One example of this would be Google Discover.
Collaborating with smart people
JP’s favorite trick is to collaborate with people who are smarter than himself. He doesn’t feel like he’s an expert, but has experiences that he can share. He’s also discovered that there are a lot of peers that have things to share.
One of the most important skills is to be able to recognize what you need to improve and to put it in a good question. This helps you learn from other people who are amazing at things you might only be okay at, whether it’s Python or JavaScript or automating data reporting…
How Google handles SERP-based intent
When it comes to SERP-based intent, there are multiple things to unpack. In response to a viewer question about how he believes that Google algorithms handle SERP-based intent, JP detailed some of them.
Consuming historical data
Historical data on previous searches and previous behaviors can help Google determine intent.
Data mining of user behavior on a platform level
Since Google owns Chrome and Android, it’s extremely likely that they draw information from user data from these sources, even if it’s anonymized. This is probably exploited through data-mining on a platform level as opposed to an algorithmic level. Both Chrome and Android probably send data regarding, on their platforms, when users are looking for X that they generally go towards a given particular thing.
Keyword refinements
JP is very interested in site search, and his experience with on-site search makes him suspect that Google looks at things like keyword refinement. If someone searches for something, then comes back and searches for something else is that a new search, or is it a refinement of the previous search because it didn’t yield the results that the searcher wanted.
This means that Google must have at least some sort of sophisticated language processing ability in query understanding. This might mean that they recognize that there’s an entity in a search, and that a high percentage of its attributes have a horizontal relationship with the concepts in the first search, so this can be treated as a refinement.
Related searches
As we see in the display of the results with the “People also ask” box, there’s likely work with related searches. The related searches are included as part of the natural SERP structure. This can help encourage people to click on a recommended search instead of going back and refining the search.
This may also be a business solution that targets SERP intent.
Top tip
“Optimize for intent and for emotion and give an immediate perception of value in less than 1 second in the SERPs”
SEO in Orbit went to space
If you missed our voyage to space on June 27th, catch it here and discover all of the tips we sent into space.
