
The summer is over and it’s time to pack up your inflatable swan and suntan lotion and jump right back into making your website even more search engine friendly! It can be a fair bit of work, so to simplify things a little I’ve drawn up a list focusing on 14 key points with a brief description and – as space is limited – links to resources explaining best practices and handy tips.
Here’s a list of the 14 things we’re going to check:
– HTTPS, HTTP/2, www
– page status 2xx, 3xx, 4xx, 5xx
– Orphan pages
– Robots.txt
– Sitemap
– Mobile friendly
– Page speed TTFB,
– Minification resources
– Cache
– Canonical & Hreflang
– Title, Description, H1
– Images : size, alt, title & figure
– Schema.org structured data
– Semantic HTML5 structure
Before we get started you’ll need to crawl your site using Oncrawl or any other crawler application.
Take a deep breath, and let’s get started!
#1 HTTPS, HTTP/2, www, HSTS
HTTPS
HTTPS is a top priority for Google and the other search engines.
Even without crawling your site you can easily test the solidity of your https handling by
- First, just typing just your domain without the “https://” into the address bar and it should show the padlock, like this:

Second, typing your domain but this time with “http://” and it must redirect to the “https://” protocol.
Look at your crawl results and look for internal urls that start with http://. If you find any they should all have a redirection to https:// (or use a rewrite in your .htaccess file), and you need to go through the code of your site and replace them with https:// in the href links.
www / non-www
Google’s Search Console used to differentiate between the data for the www and non-www versions of your website urls but since they introduced Domain Properties the data is combined. However using either www or non-www urls consistently across your site is an indicator of quality so you need to look at your crawl results, check that redirections from the incorrect version are in place (or use a rewrite in your .htaccess file) and update the incorrect urls in your site code.
HTTP/2
If your site makes a lot of HTTP requests (which, in an ideal world, it shouldn’t) you can speed up page loading by using HTTP/2 which sends the requests simultaneously rather than one after the other. You can check if your server supports HTTP/2 here and, if not, talk to your site developer about changing the configuration.
HSTS
Security is always an issue for websites but if you want to go just that bit further consider forcing the use of HTTPS with HSTS (Http Strict Transfer Security) headers.
#2 page status 2xx, 3xx, 4xx, 5xx
Look at your crawl results and you’ll see a status code for each url (pages, images, css files, javascript files etc) :
- 200 means success!
- 301 is a permanent redirection. There should be as few as possible internal links that give a 301, so look through the html of your site and replace the urls being redirected with destination urls of the redirections.
- 302 is a temporary redirection and you should use a 301 instead, if necessary.
- Any 400, 410 etc codes means that the file was not found. Having a very small percentage of these is not a major problem (and they will be removed from the Google index anyway) but they could be files that you DO want indexed and it could also indicate that access to them is being blocked or that the url contains, for example, accented or other non-standard characters.
- There should be 0 urls with a 5xx status!
For more information look at this article on the different https status codes.
#3 Orphan pages
An orphan page is one that is not linked to from any other page in the site and can occur when a site is very large, has been online for a number of years or has been restructured. They are a wasted opportunity for your SEO! You can find them manually by using a spreadsheet to cross-reference a list of pages crawled through the site with a list of pages exported from Search Console (to get the orphan pages that Google has indexed) and/or use Oncrawl to cross-reference with log analysis for all orphan pages that have had at least one visit, regardless of whether they’re indexed or not. Site owners are often surprised by how much stuff can be lurking in the dark recesses of their sites!
#4 Robots.txt
There should be a robots.txt file at the root of the site, for example https://mydomain.com/robots.txt. It will usually contain instructions describing which parts of a site are accessible to search engine robots and which parts are not and overly-broad restrictions can lead to parts of a site not being indexed. It should also contain a link to the site’s sitemap like this:

#5 XML Sitemap
You need to have a sitemap containing a full list of your pages and it needs to be up to date. Some plugins and crawl software will generate a sitemap, but it can be done manually, and the basic structure it needs to have is like this:

The attribute is the date that the page was last updated, and is important. Find a lot more information about sitemaps here.
#6 Mobile friendly
This is a whole subject in itself! Because the Google index is mobile-first you need to check your site on a regular basis to make sure that any recent changes haven’t made it mobile-unfriendly. Test how the Google mobile bot sees your site here.
Even if the page is considered to be globally mobile-friendly it will often give you hints about issues that it has discovered.
#7 Page speed: TTFB
Page speed is super important. There are a number of factors that affect this and we’ll take a look at a couple more in this article, but one of the most basic ones is the Time To First Bite (TTFB) or, in other words, the time lapse between when you click on a link and the moment that the first byte of data is received by your browser. You can check it on Page Speed Insights, Pingdom or Chrome Developer Tools and it should ideally (in Google’s opinion) be less than 200 milliseconds.

If you have a bloated site on a slow server it can easily be ten times that. If you value your business get good hosting, and there are now an increasing number of highly-optimised blazing-fast hosting services for CMSs like Wordpress.
#8 Page speed: Minification of page resources
A lot of sites load a large number of extra resources – such as css and javascript files – needed for page rendering and interaction, particularly plugin-heavy CMSs like Wordpress. So go ahead and open up the page source of your homepage and search (Ctrl+F) for “.js”:

Each one of those files requires a separate http request and is simply more data to download.
So, first, ask yourself “do all those plugins and other javascript interactivity really improve the user experience?” If so, that’s great, but you need to combine as many of the js files as possible into one single file and then minify it to reduce its size. If you don’t have a plugin to do that there are plenty of online tools. Then do the same for your css files.
#9 Page speed: Cache and CDN
Using a cache to serve pages and files that do not change often (or at all) is another whole subject in itself as there are a number of ways of implementing it depending on your particular situation, but it is a great way to speed up your site loading.
A CDN is a service consisting of fast content delivery servers that handle sending all the static files for your site, such as images, leaving your own site server to just generate the html, a much lighter workload. Some CDNs will also resize images on the fly if specific dimensions are sent in the request.
Talk to your site developer about whether you have a cache system and the possibilities of implementing this.
#10 Canonical & Hreflang
The hreflang attribute is most important if you have different language versions of the same page, but you should put them in anyway, along with the canonical tags, as Google looks for them even in mono-lingual pages. Read more about using canonical tags here.
Have a look in the section of the source code of your page: the canonical tag should contain the url of the page it is in and the hreflang attribute(s) should point to the url for each of the language versions, including one for the language of the current page, like this :

#11 Title, Description, H1
You can check these by crawling your site pages. Read more information about how to write these 3 elements here.
Title
Every page must have a unique title. It should be between 15 and 40 characters long, avoid words like “awesome”, “insane” and “unbelievable”, should contain the keywords and is the first thing that people will see in the search results so it needs to precisely answer the user’s search query.
Description
Pages that you want to rank should have a unique, engaging meta description. The description is not in itself a ranking factor, but if it’s attractive and has a call to action you will get a higher click-through rate, since it’s often used by Google as the descriptive text that appears on the search results pages.
H1
The <h1>tag is the main content header title and should be unique on all pages. It should be the first thing the user sees on the page and should reassure the user that this page is going to give them the information they need.
#12 Images: size, alt, title and figure
Look at the images section of your crawl data and consider the points below. You can get much more detailed information on images here.
- No standard page image should be bigger than 100k tops or they will slow your page loading speed, especially on mobile. Look especially at images uploaded by contributors; I have seen 5 megabyte images in blog pages!
- Make sure they have a useful name with no special characters (and no “404 File Not Found” status!)
- Images must have a value for the “alt” attribute and it should describe the image.
- The title attribute, though not essential is also an opportunity.
- Use the HTML5 semantic tags <figure> around your images and add a </figure>, like this :

Google’s John Mueller has stated that Google image search looks at the alt and figcaption and treats them as separate entities.
#13 Schema.org structured data
Schema.org structured data has become an essential means of communicating information to search engines and is another vast subject in itself, but you can check that it is present and correctly-used by testing your page URLs in the Structured Data Testing Tool.
The following structured data should be present:
- In your Homepage and About Us page at the very least you should have full mark-up for your organization, being as specific as possible about the organization type. If you are a LocalBusiness have a look at the sub-types. Include as much specific data as possible – identifying the founders, linking to social accounts, to official company identification sites, to any professional organizations that your company is a member of, etc – which will increase Google’s understanding and trust and boost your ranking.
- On product and services pages include full data, linking to your company as the provider (or as the broker if you’re listing services provided by other companies) and the areaServed property for services.
- If your site has reviews on review platforms be sure to mark them up in the Schema, and use starRating if you are a LodgingBusiness or FoodEstablishment and have stars.
- Blog articles should be fully marked up, including DatePublished and DateModified and full information about the Author with links to their site or social account pages to show their expertise.
These are just some of the possibilities offered by Schema.org structured data markup. Be sure to use the JSON-LD format rather than including it inline in the page html tags.
[Ebook] Technical SEO for non-technical thinkers

#14 Semantic HTML5 structure
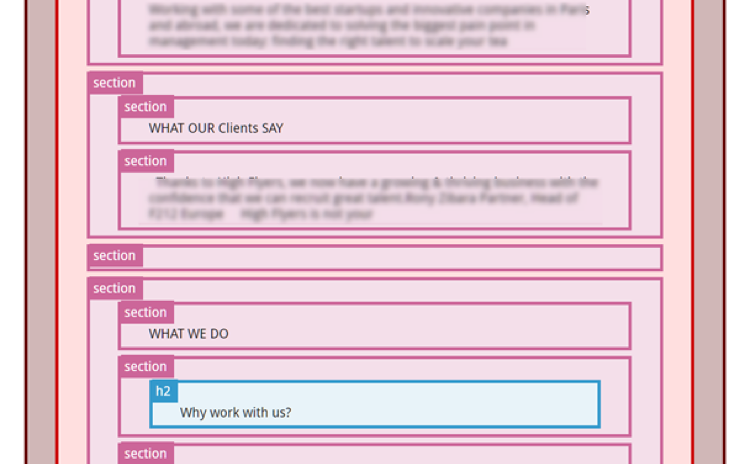
This is the last point to check on our list. As I described in my article about Semantic HTML5 tags, one goal of using these tags is to make Google’s life easier by telling it exactly which part of the page contains the unique, important content. So if you have an over-complicated structure with sections containing sections containing articles and so on (like in the image), you’re just making things more complicated! Have a look at the article to see an example of a good simple structure and then test it in the Semantic HTML5 viewer.
A final word
Phew, that was quite a ride! If you have checked all of those points you’re on your way to making your website a sleek high-performance information machine that the search engine algorithms will love!
One more thing: test your site as if you were an average user. You may think “wait, what?!” but you’d be surprised how rarely people test their own sites and are surprised to discover that it’s super difficult to place an order, find the contact form, etc. Go ahead, do it now!
Have a great autumn!
