
The feature discussed in this article is getting a new look! This article will be updated in June 2019 to reflect changes in Oncrawl.
Is Google flagging duplicate content on your site and not accepting the canonical URLs you’ve put in place? This can often happen when you’ve correctly dealt with only part of a set of pages that can be seen as duplicates.
With this walk-through of how Oncrawl processes and reports on pages that can be classified as duplicate content, we hope you’ll gain a new way of looking at how to manage duplicate content on your website. It’s quick to set up: all you need is a crawl. And it’s quick to analyze: you need to be able to identify stoplight colors, and judge relative sizes of rectangles.
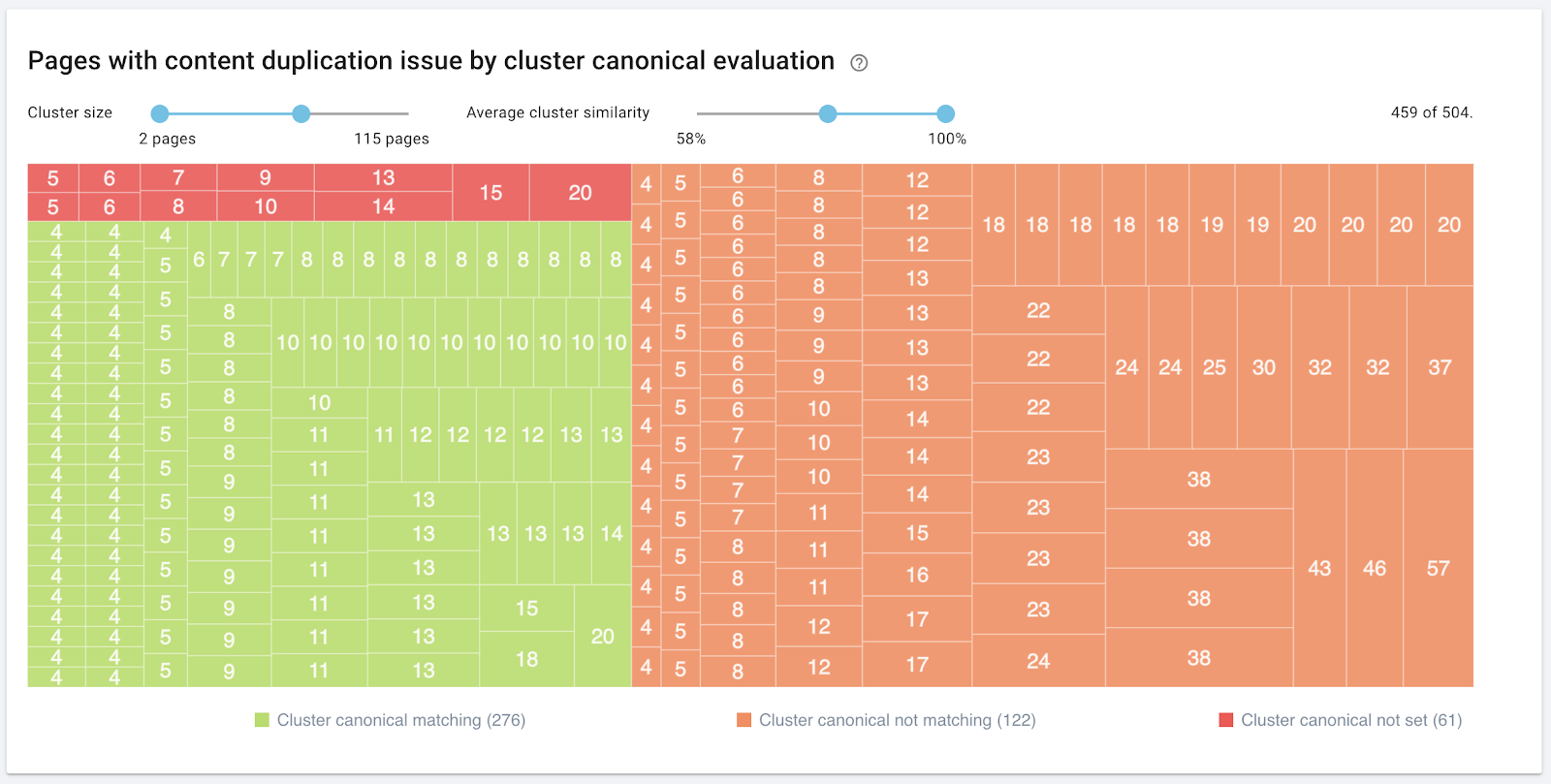
Analyzing duplicate content with Oncrawl
In addition to flagging on-page duplicate issues, such as reused titles, descriptions, and H1s, Oncrawl measures the level of similarity of all of the pages it crawls. Oncrawl uses the Simhash algorithm to establish page similarity, the same way Google does.
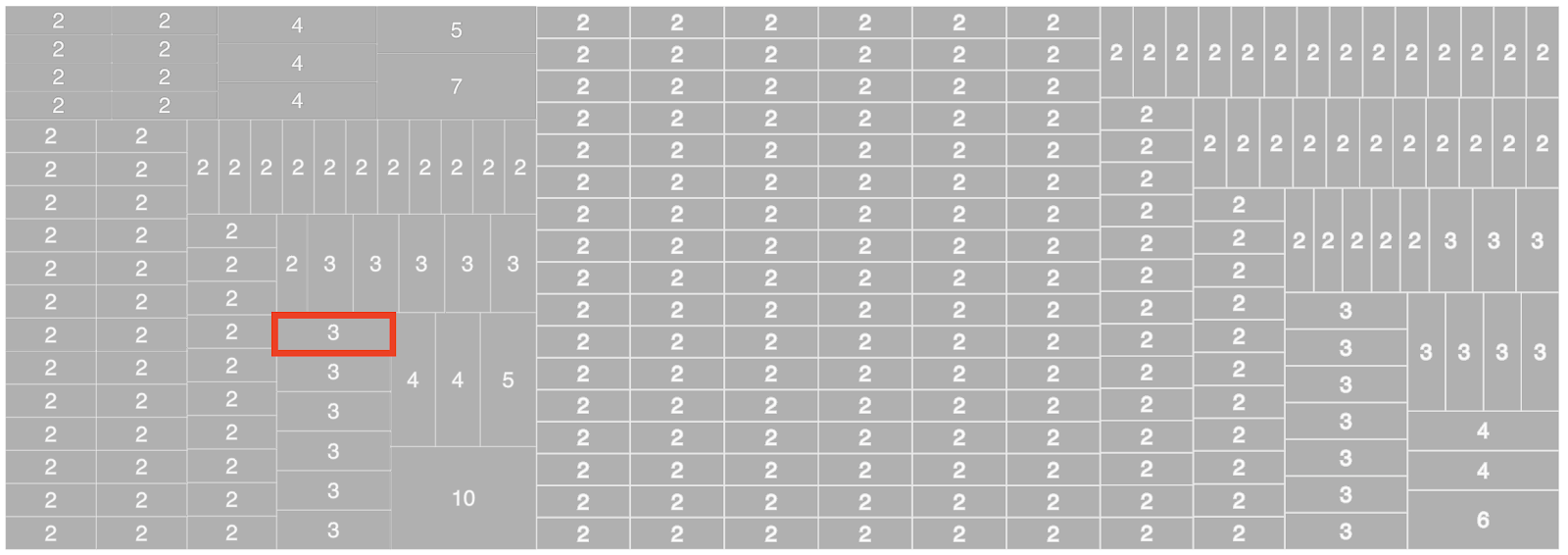
Pages that are somewhat similar are grouped together. We call this group a cluster of pages with duplicate content. Within a cluster, all pages are similar to one another. Here is a representation of one cluster with 3 pages in it:

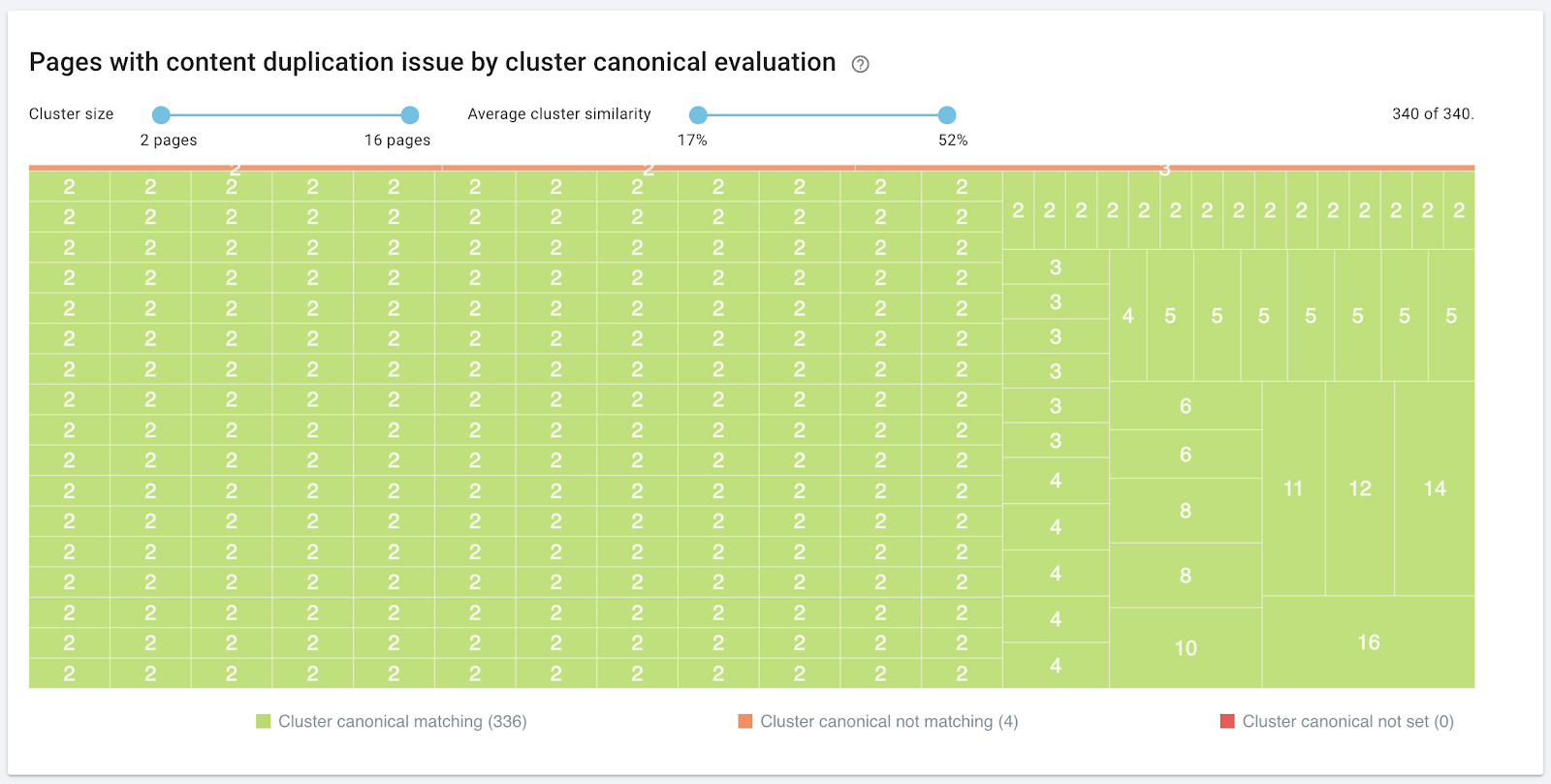
Then, Oncrawl presents all of the clusters in the same chart. The bigger the rectangle in this graphic, the more pages in the cluster :
Finally, Oncrawl matches the cluster to your use of canonical URLs. Canonical declarations are one way of signaling to Google that you’re aware that content is similar, and which of the similar pages is intended to be the most authoritative version.
Each cluster is colored based on the analysis:
- Green: all of the pages in the cluster list the same canonical URL.
- Orange: not all of the pages in the cluster list the same URL. Some declarations may be mission, or some pages may list different canonical URLs than others.
- Red: no canonical URL is set.
This lets you quickly judge whether your strategy for managing duplicate content is adequate or not.

The slider at the top of the graphic helps you narrow down the view to only clusters of a specific size.

You can use a slider to filter out clusters whose average similarity you’re not interested in. For example, you can concentrate on only clusters with a similarity of more than 80%.

What to do about duplicate content on your site
Evaluating your duplicate content management
Most sites will need to use a combination of the following three strategies to effectively manage duplicate content. Here are a few clues to spotting a well-implemented strategy.
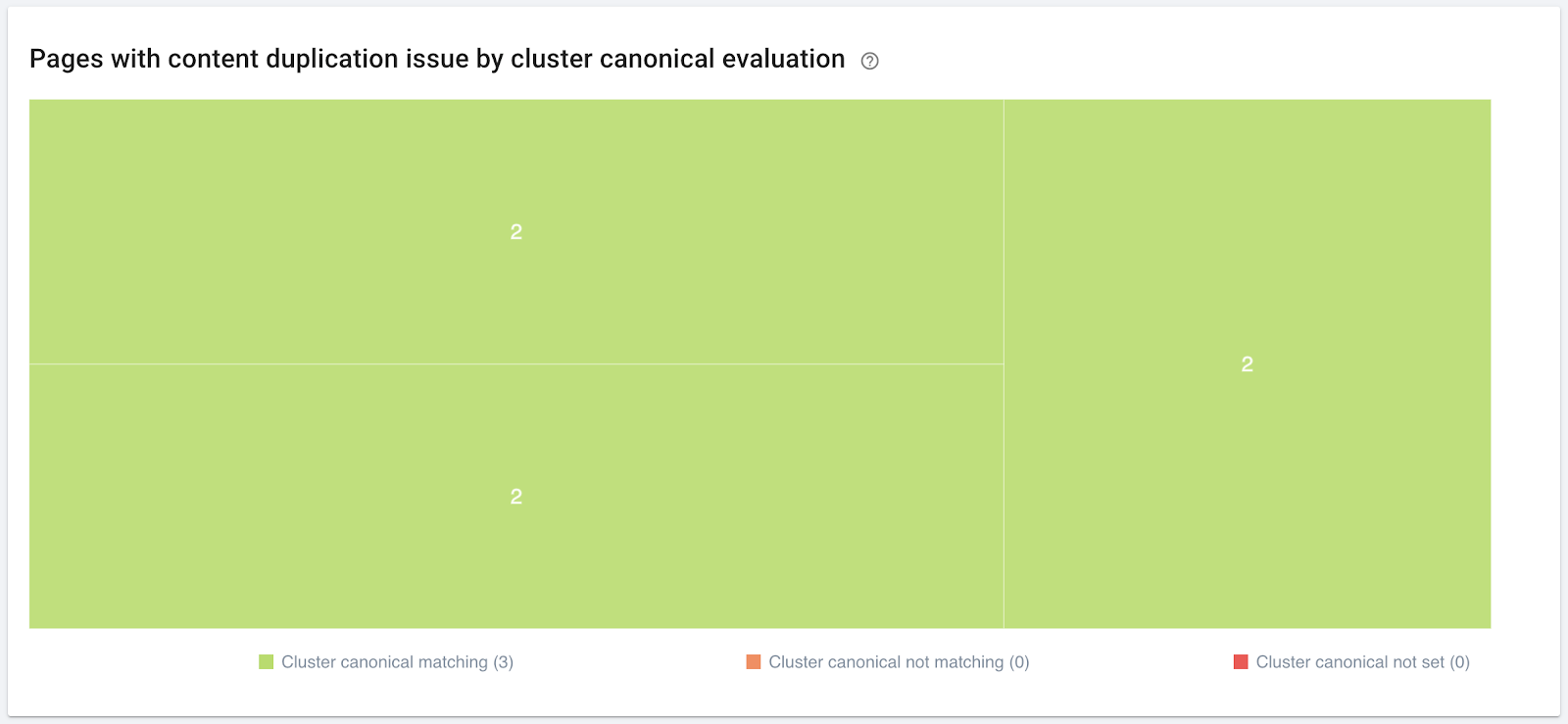
Managing duplicate content by differentiating between pages: page content is modified so that the pages no longer appear similar.
- Few clusters of similar pages
- Few pages per cluster
- Low level of similarity per cluster
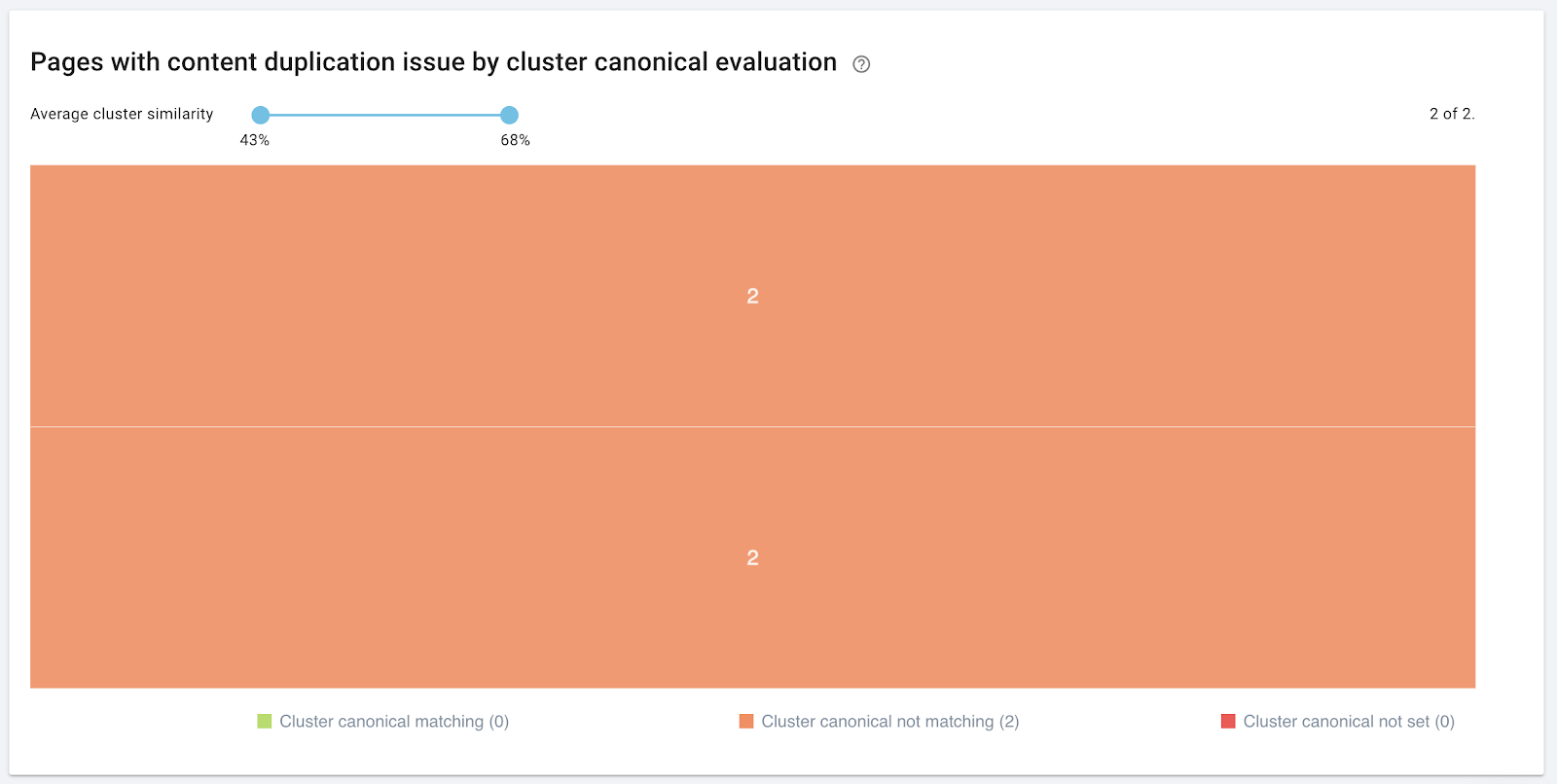
Managing duplicate content by using canonical declarations: canonical URLs are declared for all similar pages and only the canonical URL is indexed.
- No red clusters
- Few or no orange clusters
- Clusters with a large number of pages have a logical explanation
Managing duplicate content by closing duplicate pages to crawl and indexing: instructions to robots, particularly the meta robots noindex tag, are used to prevent indexing of duplicate pages.
- Low level of similarity per cluster
Setting up a new strategy or adjusting the strategy in place
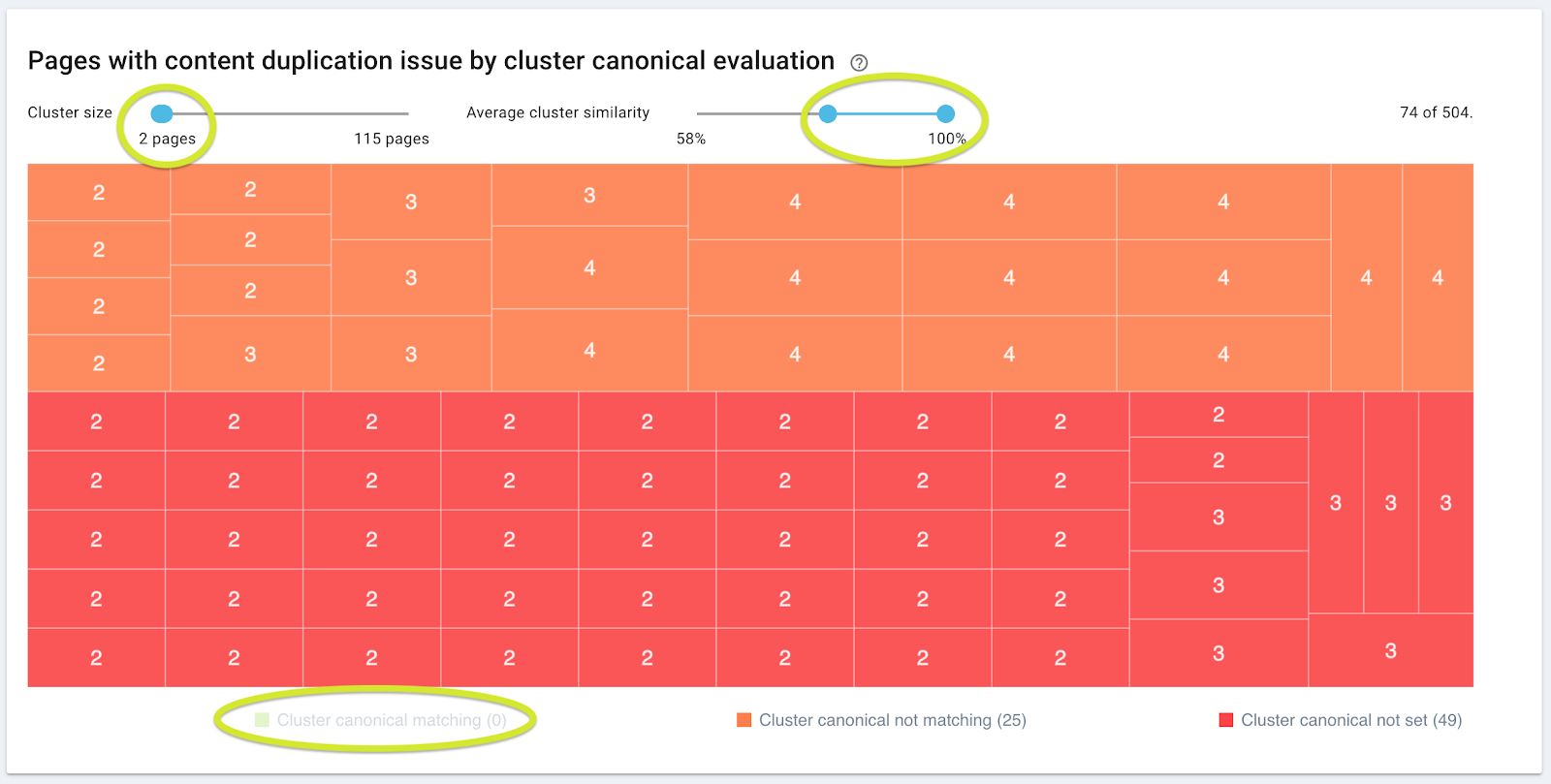
If your strategy for managing duplicate content is not working, here’s one way of using the chart to find a place to start correcting it:
- Set the similarity ratio slider to show pages with at least 80% similarity.
- Set the cluster size to something manageable for your SEO team. If you don’t know what you can handle, try clusters with a maximum of 4 pages.
- Remove the green rectangles.
- Don’t address one page at a time: look for trends across clusters. Ask questions such as:
- Do all of these clusters have a malformed URL in them?
- Do all clusters of this size and similarity contain a category page?
- Do most of these clusters contain only one type of page?
- …
It your turn to upgrade your strategy for handling duplicate pages
Duplicate pages are one of the core issues in SEO: pages that are too similar can compete against one another for rankings on the same query, or duplicate pages may not be indexed in favor of a single authoritative version chosen by you (or, increasingly, by Google). You can prevent these issues and increase your chances to have Google accept your canonical declarations by using simple aids.
Oncrawl helps you to:
- Monitor the groups of pages that looks similar based on the same algorithms as Google uses
- Judge the extent and the importance of duplicate content on your site, based on the number and size of clusters
- Focus only on the clusters that matter
- Evaluate the effectiveness of your canonical strategy through color-coded clusters
