
The webinar New perspectives on duplicate content is the final episode in the SEO in Orbit series, and aired on June 24th, 2019. In this episode, join Oncrawl Ambassador Omi Sido and Alexis Sanders as they explore the question of duplicate content. They tackle questions like: How do ranking factors and evolving search technologies impact the way we handle duplicate content? And: What does the future hold for similar content on the web?
SEO in Orbit is the first webinar series sending SEO into space. Throughout the series, we discussed the present and the future of technical SEO with some of the finest SEO specialists and sent their top tips into space on June 27th, 2019.
Watch the replay here:
Presenting Alexis Sanders
Alexis Sanders works as a Technical SEO Account Manager at Merkle. The SEO technical team ensures the accuracy, feasibility and scalability of the agency’s technical recommendations across all verticals. She is a contributor to the Moz blog and the creator of the TechnicalSEO.expert challenge and the SEO in the Lab podcast.
This episode was hosted by Omi Sido. Omi is a seasoned international speaker and is known in the industry for his humour and ability to deliver actionable insights that audiences can immediately start using. From SEO consulting with some of the world’s largest telecommunications and travel companies to managing in-house SEO at HostelWorld and Daily Mail, Omi loves diving into complex data and finding the bright spots. Currently, Omi is a Senior Technical SEO at Canon Europe and Oncrawl Ambassador.
What is duplicate content?
Omi provides the following definition of duplicate content:
Duplicate content that is similar or nearly similar to content that lives on a different URL on the same (or a different) website.
The Myth of the Duplicate Content Penalty
There is no duplicate content penalty.
This is a performance issue. We don’t want a bot to look at two particular URLs and think that they are two different contents that can be ranked next to one another.
Alexis compares a bot’s understanding of your website to Joey’s pictures from 10 Things I Hate About You: it’s impossible for a bot to find a material difference between the two versions.

You want to avoid having two exact same things that have to compete with one another in a search engine ranking situation. Instead, you want to have a single, consolidated experience that can rank and perform in search engines.
Difference between what users and bots see
A user might see a single convincing URL, but a bot might still see multiple versions that look essentially the same to it.
– Effect on crawl budget for very large site
For sites that are very large, such as Zillow or Walmart, crawl budget can vary for different pages.
As Alexis discussed in a 2018 article based on a presentation by Frédéric Dubut at SMX East, budgets are set at varying levels–at subdomain levels, at different server levels. Search engines, whether Google or Bing, want to be polite crawlers; they don’t want to slow the performance down for actual users. Whenever they sense a change in performance, they’ll back off. This can occur at different levels, not just the site level.
If you have a massive site, you want to make sure that you’re giving the most consolidated experience that is relevant for your users.
Is duplicate content a content or a technical issue?
Despite the word “content” in “duplicate content,” it’s in part a technical issue.
– Sources of duplication – [07:50]
There are many factors that can cause duplication. Even a partial list can seem to go on forever:
- Repetitive pages
- Staging sites
- HTTP vs HTTPS URLS
- Different subdomains
- Different cases
- Different file extensions
- Trailing slash
- Index pages
- URL parameters
- Facets
- Sorts
- Printer-friendly version
- Doorway page
- Inventory
- Syndicated content
- PR Releases
- Republishing content
- Plagiarized content
- Localized content
- Thin content
- Only-images
- Internal site search
- Separate mobile site
- Non-unique content
- …
– Distribution of issues between technical SEO and content
In fact, these sources of duplicate content can be split into technical and development sources and content-based sources, and some that fall into an overlapping zone between the two.
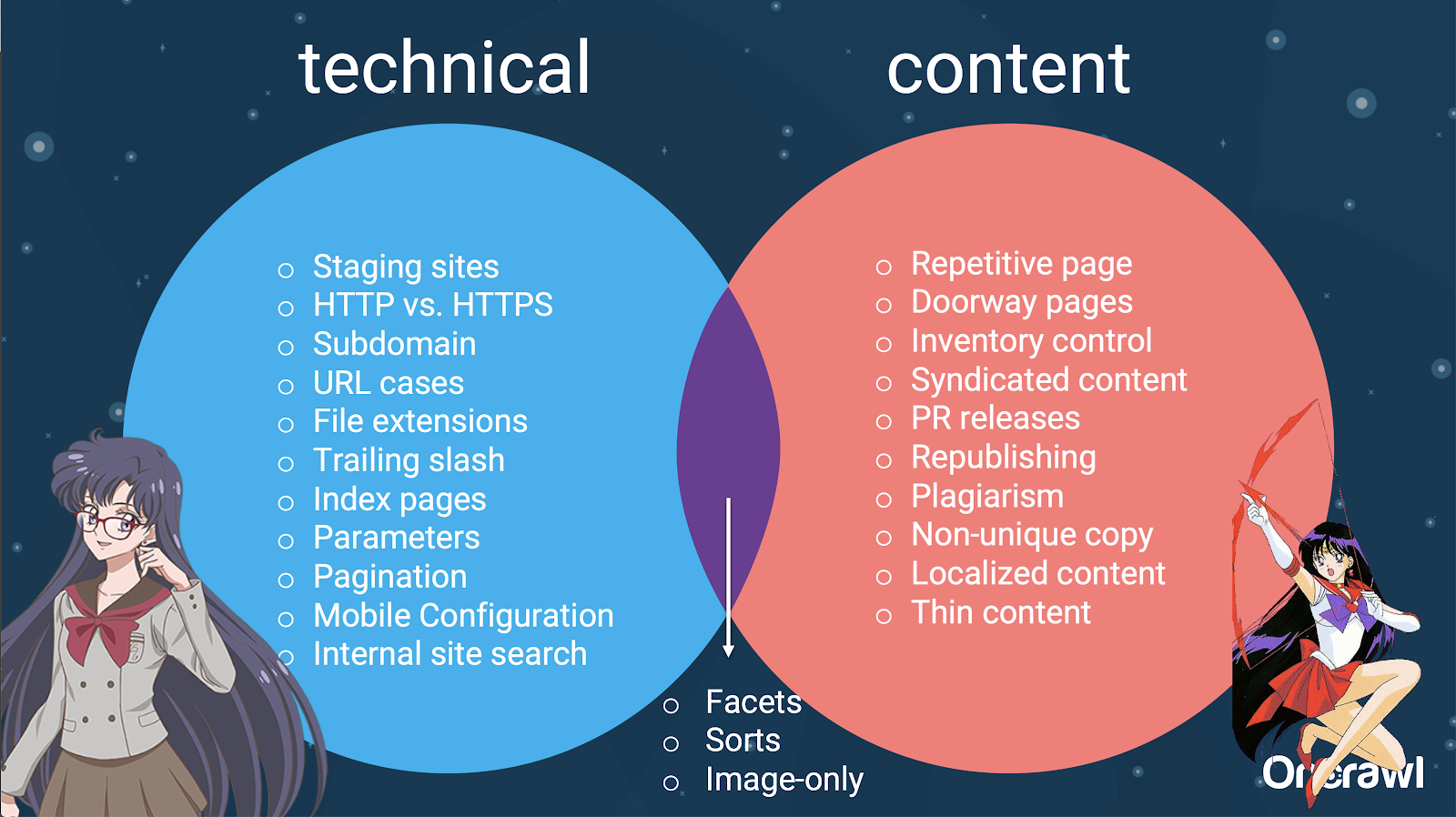
This makes duplicate content a cross-team issue, which is part of what makes it so interesting.
How to find duplicate content
Most duplicate content is unintentional. For Omi, this indicates that there’s a shared responsibility between content and technical teams for finding and fixing duplicate content.
– Omi’s favorite tool: Grammarly
Grammarly is Omi’s favorite tool for finding duplicate content–and it’s not even an SEO tool. He uses the plagiarism checker. He asks the content publisher to check to see if a new piece of content has already been published anywhere else.
– Volume of unintentional duplicate content
The problem of unintentional duplicate content is one that engineers are very familiar with. In a book called Introduction to Information Retrieval (2008), which is clearly way outdated, they estimated that about 40% of the web at the time was duplicated.

– Prioritizing strategies for dealing with duplicate content
To deal with duplicate content, you should:
- Start by knowing your user journey, which will help you understand where every piece of content fits. This can be extremely hard to do, particularly when websites were made 20 years ago, when we didn’t know how big they would become, or how they would scale. Knowing where your user is at any given point in their journey will help you prioritize in some of the next steps.
- You’ll need a hierarchy that works, in order to provide a place for each type of content. Understanding your information architecture is really high up in the steps to dealing with duplicate content.
- Prioritize duplicate content that affects performance. The partial list of sources above is far too long to be something you can realistically attack all at once.
- Deal with 100% duplication
- Signal duplicate content
- Make strategic choice on how to handle duplication: consolidate, create, delete, optimize
- Deal with stolen content

– Tools: Using segmentation in Oncrawl
Alexis really likes the ability to segment your website in Oncrawl, which allows you to dive into things that are meaningful for you.
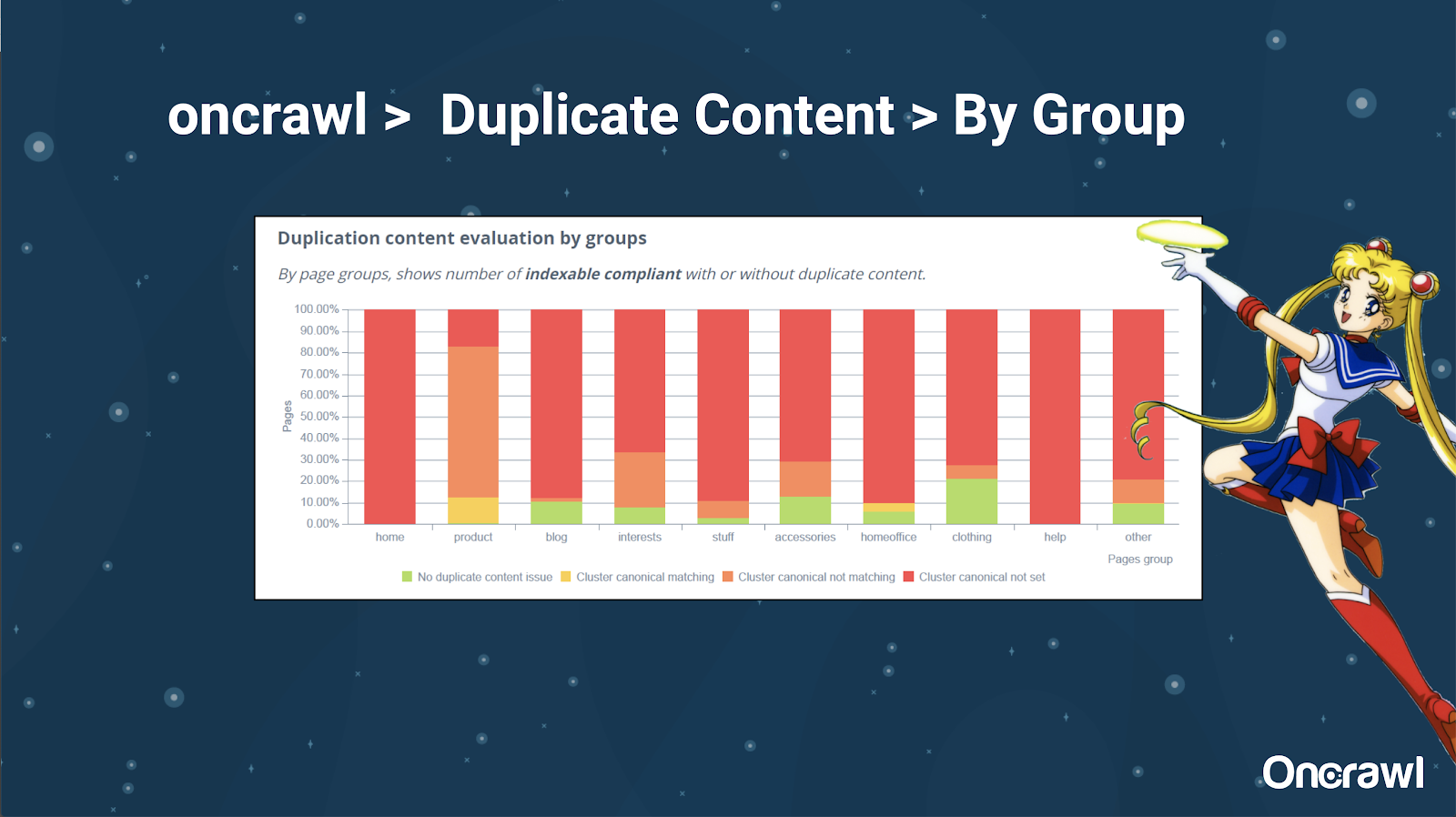
Different types pages have different amounts of duplication; this allows to get a view of the sections that have the most issues. In the example above, the site needs a lot of attention.
– Tools: Google search and GSC
You can also check for duplicate content using the search engine itself. In Google you can:
- Use direct quotes
- Use site: searches
- Using additional operators like inurl:, intitle:, or filetype:

Google Search Console has also added a duplicate content report, which is very useful in identifying what Google believes to be duplicate content from their side.
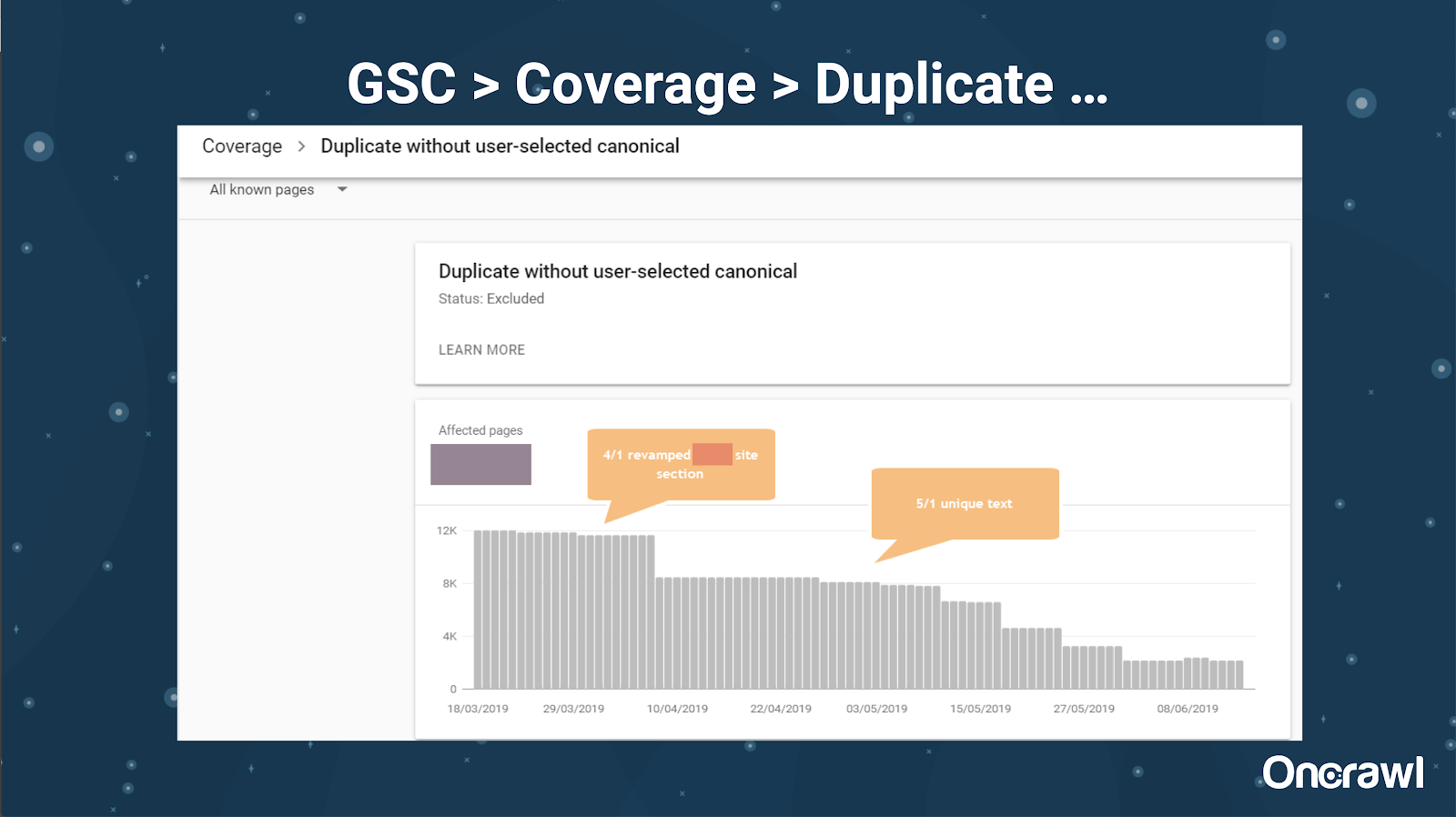
– Tools: Plagiarism tools
Like Omi, Alexis also uses different plagiarism tools:
Quetext
Noplag
PaperRater
Grammarly
CopyScape
You want to make sure that your content is not only original, but that also from a bot’s perspective, that it’s not being perceived as drawn from another source.
These can also help you find segments within an article that might be similar to content elsewhere on the internet.
Alexis loves how we have these tools that allow us to be “empathetic to search engine bots”, since none of us are robots. When tools give us signals that content is too similar, even if we know there’s a difference, that’s a good sign there’s something to dig into there.
– Tools: Keyword density tools
Two examples of keyword density tools that Alexis uses are:
TagCrowd
SEObook
Issues dependent on the type of site
Resolving duplicate content really depends on the type of content you’re publishing and type of issue you’re facing. Blogs don’t face the same cases of duplicate content as ecommerce sites, for example.
Memorable cases
Alexis shares recent client cases where she found memorable duplicate content issues.
– Massively large site: results after adding unique content
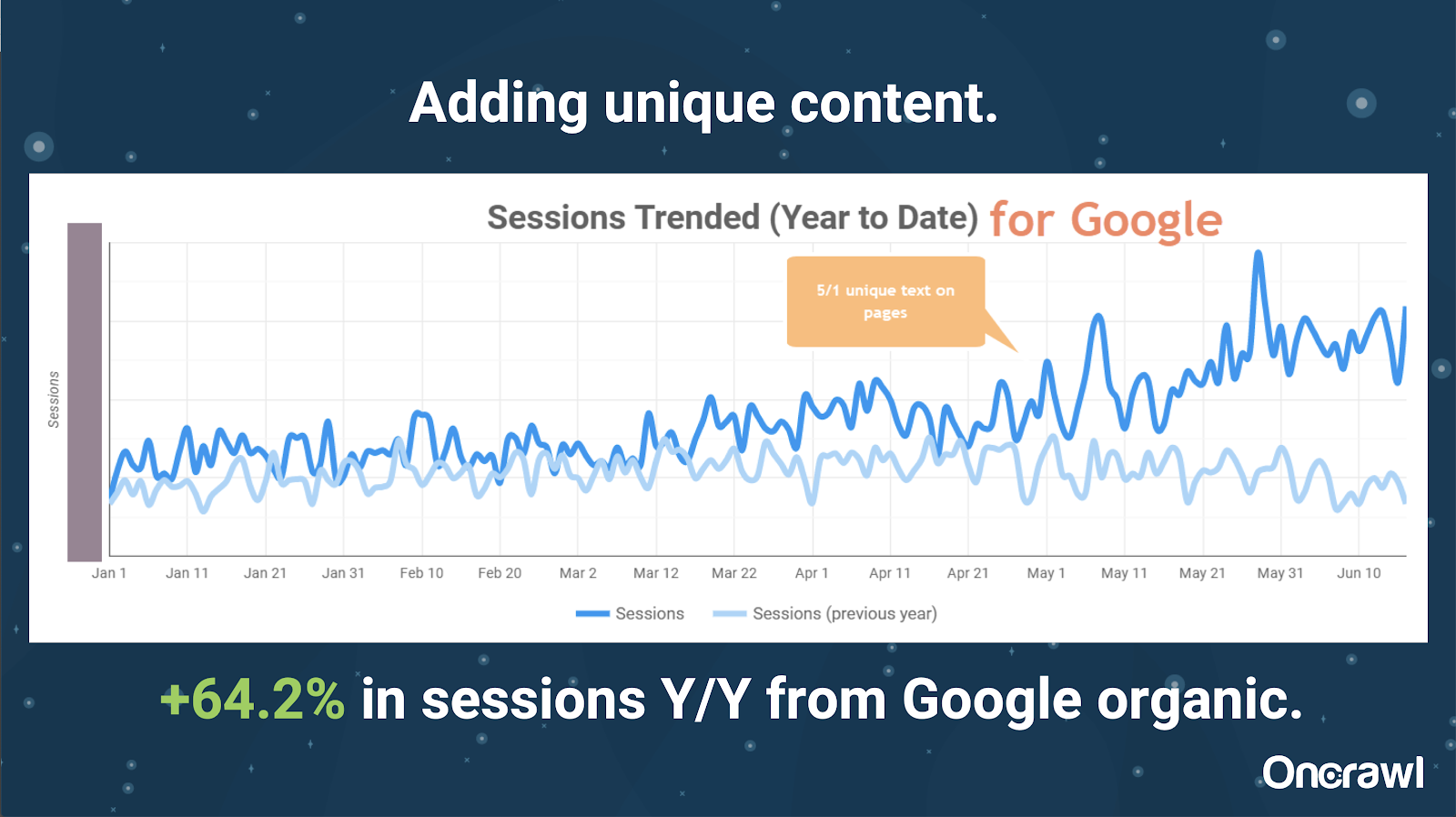
This site was massively large, and runs into crawl budget issues. It has 86 million pages that have not been indexed yet, and only about 1% of its pages have been indexed.
This is a real estate site, so much of the content is not particularly unique, and a lot of their pages are very, very similar. Alexis ended up adding content to page to add location-specific information to differentiate pages. It was surprising how quickly this produced results. (This is just Google organic data.)
For Alexis, this is a pretty generic case study. As much as we talk about EAT and similar things today, this demonstrates that as soon as search engines see content as unique and valuable, that is still being rewarded.

On this site, an accidental canonical tag issue cause about 250 pages were sent to the wrong protocol.
This is one case where canonical tags indicated the wrong principal page, pushing the HTTP pages in place of the HTTPS page.
Changes in the past 18 months
Alexis wrote a very complete article, Duplicate content and strategic resolution, about 18 months before this webinar. SEO changes rapidly, and you constantly need to renew and reassess your knowledge.
For Alexis, most of what is mentioned in the article is still relevant today, with the exception for rel=next/prev. She hopes that it will cease to be relevant within the next five to ten years, though.
Technical issues handled by developers: too manual
Many of the issues related to duplicate content that are handled by developers are way too manual. Alexis believes that they should be handled instead by CMSs and Adobe. For example, you shouldn’t have to go through manually and make sure that all of the canonicals are set, and coherent.
– Automation/notification opportunities
There is a lot of opportunity for automation in the area of technical issues with duplicate content. To give an example: we should be able to detect immediately if any links are going to HTTP when they should be going to HTTPS, and correct them.
– Site age and legacy infrastructure as a hindrance
Some back-end systems are far too old to support certain changes and automations. It’s extremely difficult to migrate an old CMS to a new one. Omi gives the example of migrating Canon’s websites to a new, custom-built CMS. It was not only expensive, but it took them 12 months.
Rel prev/next and communication from Google
Sometimes communication from Google is a bit confusing. Omi cites an example where, in applying rel=prev/next, his client saw a significant increase in performance in 2018, despite Google’s 2019 announcement that these tags haven’t been used for years.
– Lack of one-size-fits-all solutions
The difficulty with SEO is that what one person observes happening on their website isn’t necessarily the same as what another SEO sees on their own website; there’s no one-size-fits-all SEO.
Google’s ability to make announcements that are pertinent to all SEOs should be recognized as a major feat, even some of their statements are a miss, like in the case with rel=next/prev.
Hopes for the future of duplicate content management
Alexis’ hopes for the future:
- Less technical-based duplicate content (as CMSs wise up).
- More automation (unit testing and external testing). For example, tools like Oncrawl might regularly crawl your site and notify you as soon as they notice certain errors.
- Automatically detect high similarity pages and page types for writers and content managers. This would automate some of the verifications that are currently done manually in tools like Grammarly: when someone tries to publish, the CMS should say “this is kind of similar–are you sure you want to publish this?” There’s a lot of value in looking at single websites as well as at cross-website comparison.
- Google continue to improve their existing systems and detection.
- Perhaps an alert system to escalate issue of Google not using the right canonical. It would be useful to be able to alert Google to the issue and get it solved.
We need better tools, better internal tools, but hopefully as Google develops their systems, they’ll add elements to help us out a bit.
Alexis’ favorite technical tricks
Alexis has several favorite technical tricks:
- EC2 remote computer instance. This is a really great way to access a real computer for very large crawls, or anything that requires a lot of computing power. It’s extremely fast once you get it set up. Just make sure you terminate it when you’re done, as it does cost money.
- Check mobile first testing tool. Google has mentioned that this is the most accurate picture of what they’re looking at. It looks at the DOM.
- Switch user agent to Googlebot. This will give you an idea of what Googlebots are really seeing.
- Using TechnicalSEO.com’s robots.txt tool. This is one of Merkle’s tools, but Alexis really does love it because robots.txt can be really confusing at times.
- Use a log analyzer.
- Made with Love’s htaccess checker.
- Using Google Data Studio to report on changes (syncing Sheets with updates, filtering each page by relevant updates).
Technical SEO difficulties: robots.txt
Robots.txt is really confusing.
It’s an archaic file that looks like it should be able to support RegEx, but doesn’t.
It has different precedence rules for disallow and allow rules, which can get confusing.
Different bots can ignore different things, even though they’re not supposed to.
Your assumptions about what is right aren’t always right.

Q&A
– HSTS: is split protocol required?
You have to have all HTTPS for duplicate content if you have HSTS.
– Is translated content duplicate content?
Often, when you’re using hreflang, you’re using it to disambiguate between localized versions within the same language, such as a US and an Irish English-language page. Alexis wouldn’t consider this duplicate content, but she would definitely recommend making sure that you have your hreflang tags set up correctly to indicate that this is the same experience, optimized for different audiences.
– Can you use canonical tags instead of 301 redirects for an HTTP/HTTPS migration?
It would be useful to check what’s actually happening in the SERPs. Alexis’ instinct is to say that this would be okay, but it depends on how Google is actually behaving. Ideally, if these are the exact same page, you would want to use a 301, but she has seen canonical tags work in the past for this type of migration. She’s actually even seen this accidentally happen.
In Omi’s experience, he would strongly suggest using 301s to avoid issues: if you’re migrating the website, you might as well migrate it correctly to avoid current and future errors.
– Effect of duplicate page titles
Let’s say you have a title that is very similar for different locations, but the content is very different. While that isn’t duplicate content to Alexis, she sees search engines as treating this as a “overall” type thing, and titles are something that can be used to identify areas with possible issues.
This is where you might want to use a [site: + intitle: ] search.
However, just because you have the same title tag, it’s not going to cause a duplicate content issue.
You should still aim for unique titles and meta descriptions, even on paginated or other very similar pages. This is not due to duplicate content, but rather concerns the way to want to optimize how you present your pages in the SERPs.
Top tip
“Duplicate content is both a technical and content marketing challenge.”
SEO in Orbit went to space
If you missed our voyage to space on June 27th, catch it here and discover all of the tips we sent into space.
