
How do you define word vectors? In this post, I will introduce you to the concept of word vectors. We’ll go over different types of word embeddings, and more importantly, how word vectors function. We’ll then be able to see the impact of word vectors on SEO, which will lead us to understand how Schema.org markup for structured data can help you take advantage of word vectors in SEO.
Keep reading this post if you wish to learn more about these topics.
Let’s dive right in.
What are word vectors?
Word vectors (also called Word embeddings) are a type of word representation that allows words with similar meanings to have an equal representation.
In simple terms: A word vector is a vector representation of a particular word.
According to Wikipedia:
It is a technique used in natural language processing (NLP) for representing words for text analysis, typically as a real-valued vector that encodes the meaning of the word so that words that are close in vector space are likely to have similar meanings.
The following example will help us to understand this better:
Look at these similar sentences:
Have a good day. and Have a great day.
They barely have a different meaning. If we construct an exhaustive vocabulary (let’s call it V), it would have V = {Have, a, good, great, day} combining all words. We could encode the word as follows.
The vector representation of a word may be a one-hot encoded vector where 1 represents the position where the word exists and 0 represents the rest
Have = [1,0,0,0,0]
a=[0,1,0,0,0]
good=[0,0,1,0,0]
great=[0,0,0,1,0]
day=[0,0,0,0,1]
Suppose our vocabulary has only five words: King, Queen, Man, Woman, and Child. We could encode the words as:
King = [1,0,0,0,0]
Queen = [0,1,0,0,0]
Man = [0,0,1,00]
Woman = [0,0,0,1,0]
Child = [0,0,0,0,1]
Types of word Embedding (Word Vectors)
Word Embedding is one such technique in which vectors represent text. Here are some of the more popular types of word Embedding:
- Frequency-based Embedding
- Prediction based Embedding
We will not go deep into Frequency-based Embedding and Prediction-based Embedding here, but you may find the following guides helpful to understand both:
An Intuitive Understanding of Word Embeddings and Quick Introduction to Bag-of-Words (BOW) and TF-IDF for Creating Features from Text
A brief introduction to WORD2Vec
While Frequency-based Embedding has gained popularity, there is still a void in understanding the context of words and limited in their word representations.
Prediction-based Embedding (WORD2Vec) was created, patented, and introduced to the NLP community in 2013 by a team of researchers led by Tomas Mikolov at Google.
According to Wikipedia, the word2vec algorithm uses a neural network model to learn word associations from a large corpus of text (large and structured set of texts).
Once trained, such a model can detect synonymous words or suggest additional words for a partial sentence. For example, with Word2Vec, you can easily create such results: King – man + woman = Queen, which was considered an almost magical result.
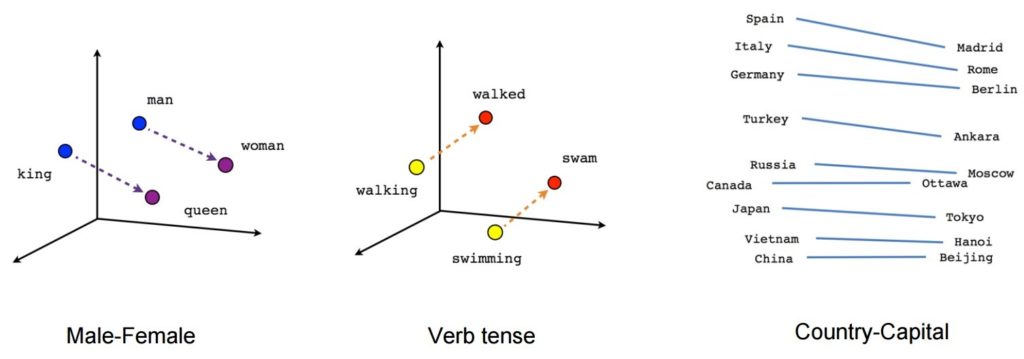 Image source: Tensorflow
Image source: Tensorflow
- [king] – [man] + [woman] ~= [queen] (another way of thinking about this is that [king] – [queen] is encoding just the gendered part of [monarch])
- [walking] – [swimming] + [swam] ~= [walked] (or [swam] – [swimming] is encoding just the “past-tense-ness” of the verb)
- [madrid] – [spain] + [france] ~= [paris] (or [madrid] – [spain] ~= [paris] – [france] which is presumably roughly “capital”)
Source: Brainslab Digital
I know this is a little technical, but Stitch Fix put together a fantastic post about semantic relationships and word vectors.
The Word2Vec algorithm is not a single algorithm but a combination of two techniques that uses a few AI methods to bridge human comprehension and machine comprehension. This technique is essential in solving many NLP problems.
These two techniques are:
- – CBOW (Continuous bag of words) or CBOW model
- – Skip-gram model.
Both are shallow neural networks that provide probabilities for words and have been proven helpful in tasks such as word comparison and word analogy.
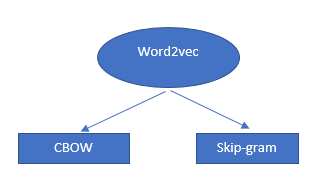
How word vectors and word2vecs works
Word Vector is an AI model developed by Google, and it helps us solve very complex NLP tasks.
“Word Vector models have one central goal that you should know:
It is an algorithm that helps Google in detecting semantic relationships between words.”
Each word is encoded in a vector (as a number represented in multiple dimensions) to match vectors of words that appear in a similar context. Hence a dense vector is formed for the text.
These vector models map semantically similar phrases to nearby points based on equivalence, similarities, or relatedness of ideas and language
[Case Study] Driving growth in new markets with on-page SEO

Word2Vec- How does it work?
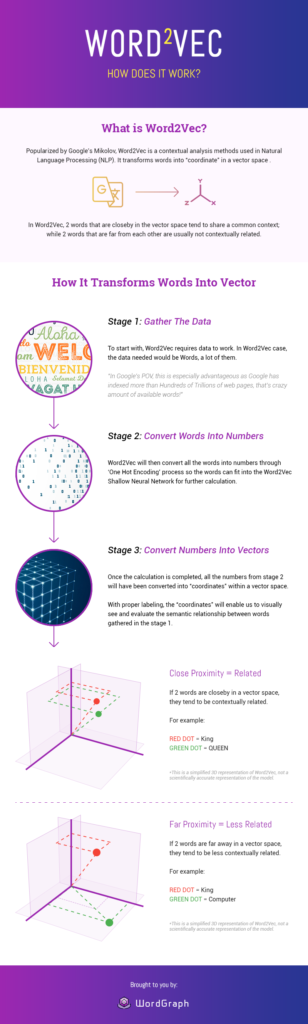
Image source: Seopressor
{kind=link}
Pros and Cons of Word2Vec
We have seen that Word2vec is a very effective technique for generating distributional similarity. I have listed some of its other advantages here:
- There is no difficulty understanding Word2vec concepts. Word2Vec is not so complex that you aren’t aware of what is happening behind the scenes.
- Word2Vec’s architecture is very powerful and easy to use. Compared to other techniques, it is fast to train.
- Training is almost entirely automated here, so human-tagged data is no longer required.
- This technique works for both small and large datasets. As a result, it is an easy-to-scale model.
- If you know the concepts, you can easily replicate the entire concept and algorithm.
- It captures semantic similarity exceptionally well.
- Accurate and computationally efficient
- Since this approach is unsupervised, it is very time-saving in terms of effort.
Challenges of Word2Vec
The Word2vec concept is very efficient, but you may find a few points a bit challenging. Here are a few of the most common challenges.
- When developing a word2vec model for your dataset, debugging can be a major challenge, as the word2vec model is easy to develop but hard to debug.
- It does not deal with ambiguities. So, in the case of words with multiple meanings, Embedding will reflect the average of these meanings in vector space.
- Unable to handle unknown or OOV words: The biggest problem with word2vec is the inability to handle unknown or out-of-vocabulary (OOV) words.
Word Vectors: A Game-changer in Search Engine Optimization?
Many SEO experts believe Word Vector affects a website’s ranking in search engine results.
Over the past five years, Google has introduced two algorithm updates that put a clear focus on content quality and language comprehensiveness.
Let’s take a step back and talk about the updates:
Hummingbird
In 2013, Hummingbird gave search engines the capability of semantic analysis. By utilizing and incorporating semantics theory in their algorithms, they opened a new path to the world of search.
Google Hummingbird was the biggest change to the search engine since Caffeine in 2010. It gets its name from being “precise and fast”.
According to Search Engine Land, Hummingbird pays more attention to each word in a query, ensuring that the entire query is considered, rather than just particular words.
The main goal of Hummingbird was to deliver better results by understanding the context of the query rather than returning results for specific keywords.
“Google Hummingbird was released in September 2013.”
RankBrain
In 2015, Google announced RankBrain, a strategy that incorporated artificial intelligence (AI).
RankBrain is an algorithm that helps Google break down complex search queries into simpler ones. RankBrain converts search queries from “human” language into a language that Google can easily understand.
Google confirmed the use of RankBrain on 26 October 2015 in an article published by Bloomberg.
BERT
On 21 October 2019, BERT began rolling out in Google’s search system
BERT stands for Bidirectional Encoder Representations from Transformers, a neural network-based technique used by Google for pre-training in natural language processing (NLP).
In short, BERT helps computers understand language more like humans, and it is the biggest change in search since Google introduced RankBrain.
It is not a replacement for RankBrain, but rather an added method for understanding content and queries.
Google uses BERT in its ranking system as an addition. The RankBrain algorithm still exists for some queries and will continue to exist. But when Google feels that BERT can better understand a query, they will use that.
For more information on BERT, check out this post by Barry Schwartz, as well as Dawn Anderson’s in-depth dive.
Rank your site with Word Vectors
I’m assuming you already have created and published unique content, and even after polishing it over and over again, it does not improve your ranking or traffic.
Do you wonder why this is happening to you?
It might be because you didn’t include Word Vector: Google’s AI model.
- The first step is to Identify the Word Vectors of the top 10 SERP rankings for your niche.
- Know what keywords your competitors are using and what you might be overlooking.
By applying Word2Vec, which takes advantage of advanced Natural Language processing techniques and machine learning framework, you will be able to see everything in detail.
But these are possible if you know the machine learning and NLP techniques, but we can apply word vectors in the content using the following tool:
WordGraph, World’s First Word Vector Tool
This artificial intelligence tool is created with Neural Networks for Natural Language Processing and trained with Machine Learning.
Based on Artificial Intelligence, WordGraph analyzes your content and helps you improve its relevance to the Top 10 ranking websites.
It suggests keywords that are mathematically and contextually related to your main keyword.
Personally, I pair it up with BIQ, a powerful SEO tool that works well with WordGraph.
Add your content to the content intelligence tool built into Biq. It will show you a whole list of on-page SEO tips that you can add if you want to rank in the top position.
You can see how content intelligence works in this example. The lists will help you master on-page SEO and rank using actionable methods!
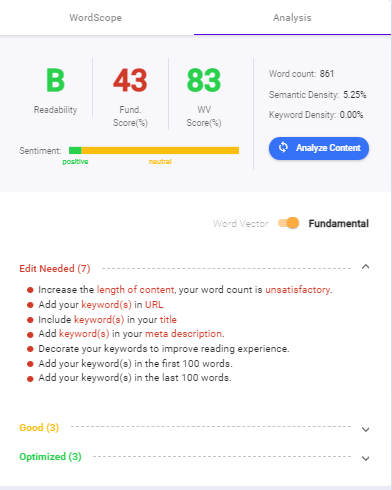
How to Supercharge Word Vectors: Using Structured Data Markup
Schema markup, or structured data, is a type of code (written in JSON, Java-Script Object Notation) created using schema.org vocabulary that helps search engines to crawl, organize, and display your content.
How to add structured data
Structured data can be easily added to your website by adding an inline script in your html
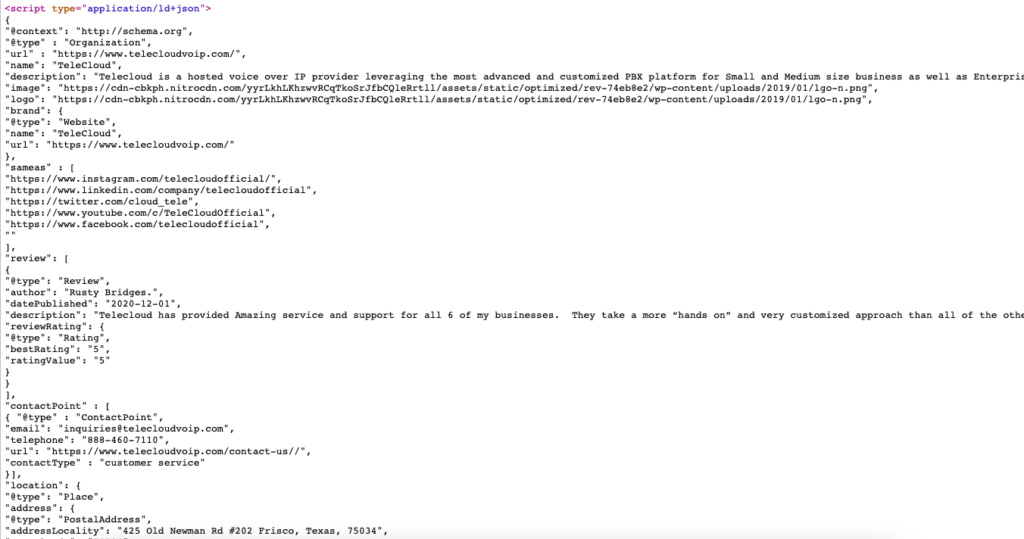
An example below shows how to define your organization’s structured data in the simplest format possible.
To generate the Schema Markup, I use this Schema Markup Generator (JSON-LD).
Here is the live example of schema markup for https://www.telecloudvoip.com/. Check the source code and search for JSON.
After the schema markup code is created, use Google’s Rich Results Test to see if the page supports rich results.
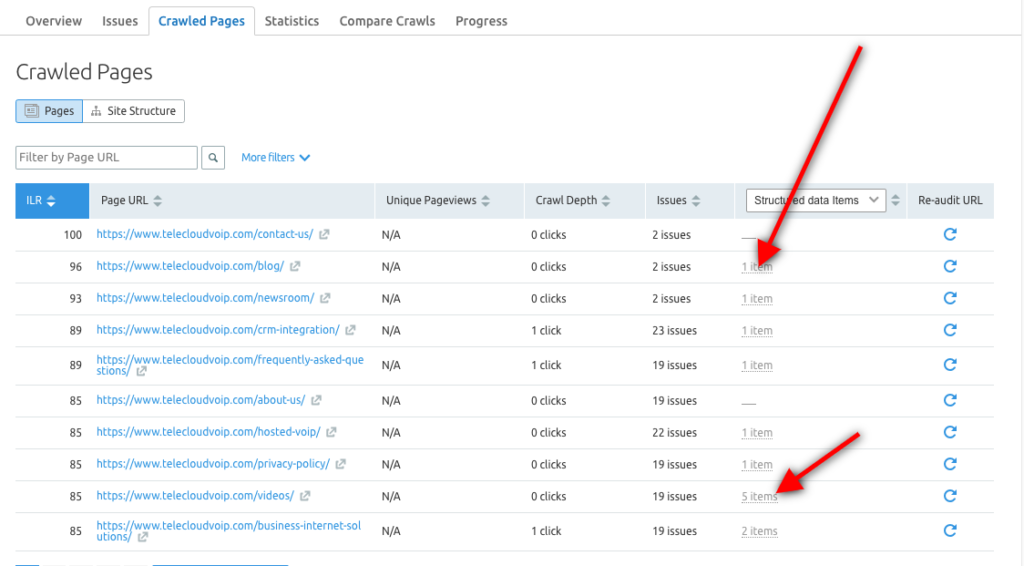
You can also use the Semrush Site Audit tool to explore Structured Data items for each URL and identify which pages are eligible for being in Rich Results.
Why is Structured Data Important for SEO?
Structured Data is important for SEO because it helps Google to understand what your website and pages are about, resulting in a more accurate ranking of your content.
Structured Data improves both the Search Bot’s experience as well as the user’s experience by improving the SERP (search engine result pages) with more information and accuracy.
To see the impact in Google search, go to Search Console and under Performance > Search Result > Search Appearance, you can view a breakdown of all the rich result types like “videos” and “FAQs” and see the organic impressions and clicks they drove for your content.
The following are some advantages of structured data:
- Structured data support semantic search
- It also supports your E‑A-T (expertise, authoritativeness, and trust)
- Having structured data can also increase conversion rates, since more people will see your listings, which increases the likelihood that they will buy from you.
- Using structured data the search engines are better able to understand your brand, your website, and your content.
- It will be easier for search engines to distinguish between contact pages, product descriptions, recipe pages, events pages, and customer reviews.
- With the help of structured data Google builds a better, more accurate knowledge graph and knowledge panel about your brand.
- These improvements can result in more organic impressions and organic clicks.
Structured data is currently used by Google to enhance search results. When people search for your web pages using keywords, structured data can help you get better results. Search engines will notice your content more if we add Schema markup.
You can implement schema markup on a number of different items. Listed below are a few areas where schema can be applied:
- Articles
- Blog Posts
- News Articles
- Events
- Products
- Videos
- Services
- Reviews
- Aggregate Ratings
- Restaurants
- Local businesses
Here’s a full list of the items you can mark up with schema.
Structured Data with Entity Embeddings
The term “entity” refers to a representation of any type of object, concept, or subject. An entity can be a person, movie, book, idea, place, company, or event.
While machines can’t really understand words, with entity embeddings, they are able to easily understand the relationship between king – queen = husband – wife
Entity embeddings perform better than one-hot encodings
The word vector algorithm is used by Google to discover semantic relationships between words, and when combined with structured data, we end up with a semantically enhanced web.
By using structured data, you are contributing to a more semantic web. This is an enhanced web where we describe the data in a machine-readable format.
Structured semantic data on your website helps search engines match your content with the right audience. The use of NLP, Machine Learning and Deep Learning helps reduce the gap between what people search for and what titles are available.
Final Thoughts
As you now understand the concept of word vectors and its importance, you can make your organic search strategy more effective and more efficient by utilizing word vectors, entity embeddings and structured semantic data.
In order to achieve the highest ranking, traffic, and conversions, you must use word vectors, entity embeddings and structured semantic data to demonstrate to Google that the content on your webpage is accurate, precise, and trustworthy.
