
In this case study, I will look at Hangikredi.com which is one of the biggest financial and digital assets of Turkey. We will see technical SEO subheadings and some graphics.
This case study is presented in two articles. This article handles the 12 March Google Core Update, which had a strong negative effect on the website, and what we did to counteract it. We will look at 13 technical problems and solutions, as well as holistic issues.
Read the second installment to see how I applied learning from this update to become a winner from every Google Core Update.
Problems and Solutions: Fixing the Effects of the 12 March Google Core Update
Until the 12 March Core Algorithm Update, everything was smooth sailing for the website, based on the analytics data. In one day, after the news was released about the Core Algorithm Update, there was a huge drop in rankings and great frustration in the office. I personally didn’t see that day because I only arrived when they hired me to start a new SEO Project and Process 14 days later.
[Case Study] Improving rankings, organic visits and sales with log files analysis

The Damage Report for firm’s web site after 12 March Core Algorithm Update is below:
- 36% Organic Session Loss
- 65% Click Drop
- 30% CTR Loss
- 33% Organic User Loss
- 100 000 Impressions Lost per day.
- 9.72% Impression Loss
- 8 000 Keywords Lost

Now, as we stated at the beginning of the Case Study Article, we should ask one question. We couldn’t ask “When will the next Core Algorithm Update happen?” because it has already happened. Only one question was left.
“What different criterias did Google consider between me and my competitor?”
As you can see from the chart above and from damage report, we had lost our main traffic and keywords.
1. Problem: Internal Linking
I noticed that when I first checked the internal link count, anchor text, and link flow, my competitor was ahead of me.
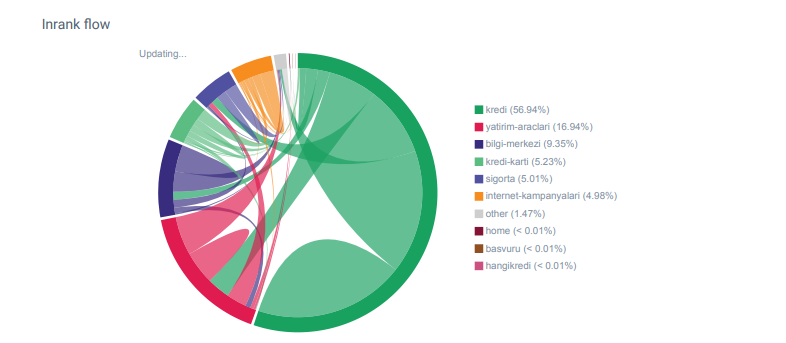
Linkflow report for Hangikredi.com’s categories from Oncrawl
My main competitor has over 340 000 internal links with thousands of anchor texts. In these days, our web site only had 70 000 internal links without valuable anchor texts. In addition, lack of internal links had affected crawl budget and productivity for the web site. Even though 80% of our traffic was collected on only 20 product pages, 90% of our site consisted of guide pages with useful information for users. And most of our keywords and relevancy score for financial queries come from these pages. Also, there were countlessly too many orphaned pages.
Because of the missing internal linking structure, when I did Log Analysis with Kibana, I noticed that the most crawled pages were the ones that received the least traffic. Also, when I paired this with the internal link network, I discovered that the lowest traffic corporate pages (Privacy, Cookies, Security, About Us Pages) have the maximum number of internal links.
As I’ll discuss in the next section, this caused Googlebot to remove the internal link factor from Pagerank when it crawled the site, realizing that internal links were not constructed as intended.
2. Problem: Site-Architecture, Inte²rnal Pagerank, Traffic and Crawl Efficiency
According to Google’s statement, internal links and anchor texts help Googlebot to understand the importance and context of a web page. Internal Pagerank or Inrank is calculated based on more than one factor. According to Bill Slawski, internal or external links are not all equal. A link’s value for Pagerank flow changes according to its position, kind, style and font-weight.

If Googlebot understands which pages are important for your website, it will crawl them more and index them faster. Internal links and correct Site-Tree design are important factors for this. Other experts have also commented on this correlation over the years:
“Most links do provide a bit of additional context through their anchor text. At least they should, right?”
–John Mueller, Google 2017“If you have pages that you think are important on your site don’t bury them 15 links deep within your site and I’m not talking about directory length I’m talking about actual you have to click through 15 links to find that page if there’s a page that’s important or that has great profit margins or converts really – well – escalate that put a link to that page from your root page that’s the sort of thing where it can make a lot of sense.”
–Matt Cutts, Google 2011“If one page links to another with the word “contact” or the word “about”, and the page being linked to includes an address, that address location might be considered relevant to the page doing that linking.”
12 Google Link Analysis Methods That Might Have Changed – Bill Slawski
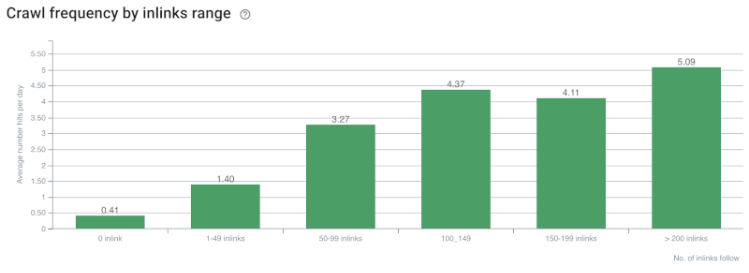
Crawl Rate/Demand and Internal Link Count Correlation. Source: Oncrawl.
So far, we may make these inferences:
- Google cares about click depth. If a web page is closer to the home page, it should be more important. This was also confirmed by John Mueller on 1 July 2018 English Google Webmaster Hangout.
- If a web page has lots of internal links which point it, it should be important.
- Anchor texts can give contextual power to a web page.
- An internal link can transmit different Pagerank amounts based on its the position, type, font-weight or style.
- A UX-friendly Site-Tree that gives clear messages about Internal Page Authority to the search engine crawlers is a better choice for Inrank distribution and crawl efficiency.
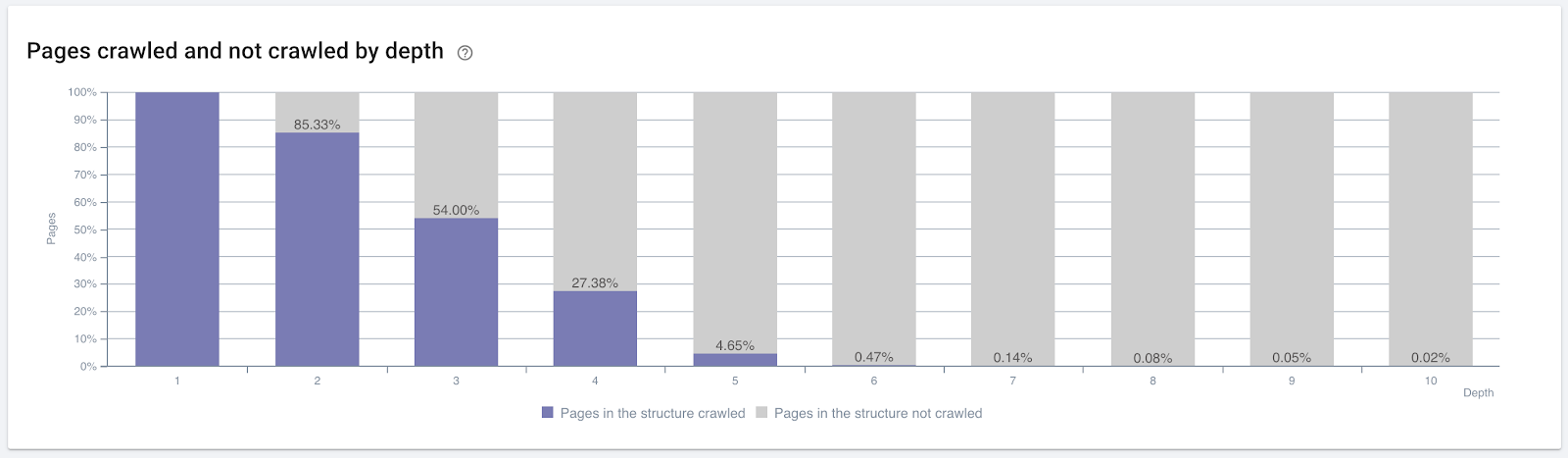
Percentage of pages crawled by click depth. Source: Oncrawl.
But these are not enough to understand internal links’ nature and effects on crawl efficiency.
Oncrawl SEO Crawler

If your most internally linked pages don’t create traffic or get clicked, it gives signals that indicate that your Site-Tree and internal link structure are not constructed according to user-intent. And Google always tries to find your most relevant pages with user-intent or search entities. We have another citation from Bill Slawski that makes this subject clearer:
“If a resource is linked to by a number of resources that is disproportionate with respect to the traffic received by use of those links, that resource may be demoted in the ranking process.”
Did the Groundhog Update Just Take Place at Google? — Bill Slawski“The selection quality score may be higher for a selection that results in a long dwell time (e.g., greater than a threshold time period) than the selection quality score for a selection that results in a short dwell time.”
Did the Groundhog Update Just Take Place at Google? — Bill Slawski
So we have two more factors:
- Dwell Time in the linked page.
- User traffic which produced by the link.
Internal link count and style/position are not the only factors. The number of users that follow these links and their behaviour metrics are also important. Additionally, we know that links and pages that are clicked/visited are crawled by Google much more than links and pages that are not clicked or visited.
“We have moved more and more towards understanding sections of a site to understand the quality of those sections.”
John Mueller, 2 May 2017, English Google Webmasters Hangout.
In light of all these factors, I will share two different and different Pagerank Simulator results:
These Pagerank calculations are made with the assumption that all pages are equal, including the Homepage. The real difference is determined by the link hierarchy.
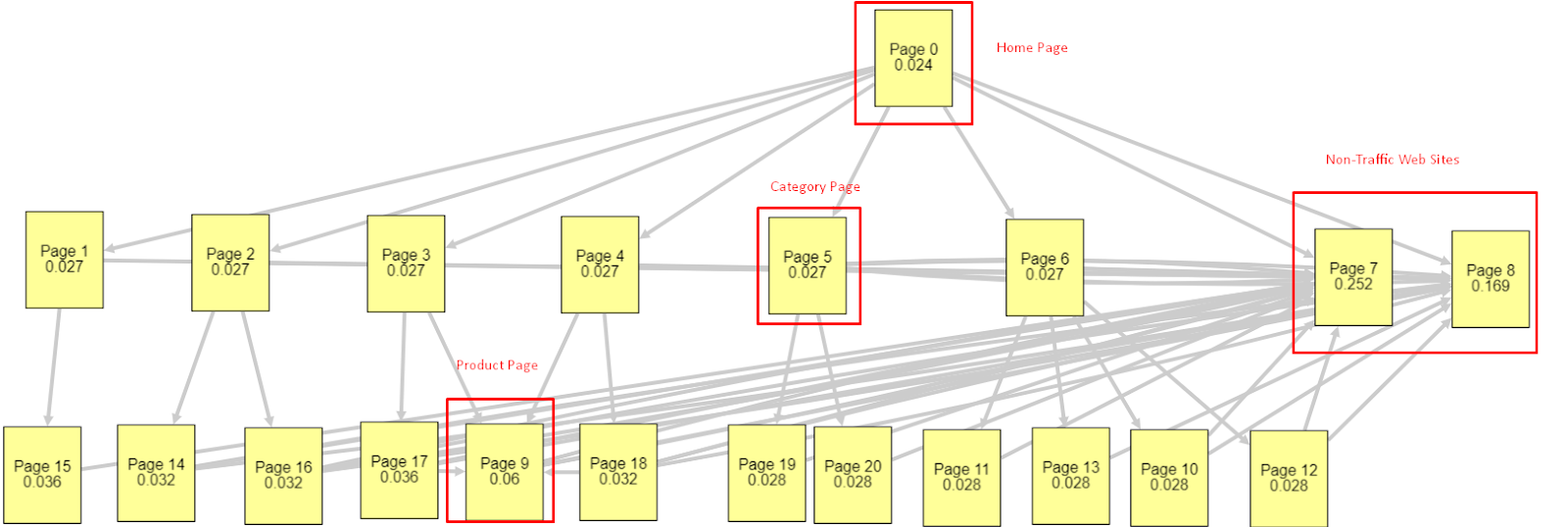
The example shown here is closer to the internal link structure before March 12th. Homepage PR: 0.024, Category Page PR: 0.027, Product Page PR: 0.06, Non-traffic Web Pages PR: 0.252.
As you may notice, Googlebot cannot trust this internal link structure to calculate internal pagerank and importance of internal pages. Non-traffic and product-free pages have 12 times more authority than the homepage. It has more than product pages.
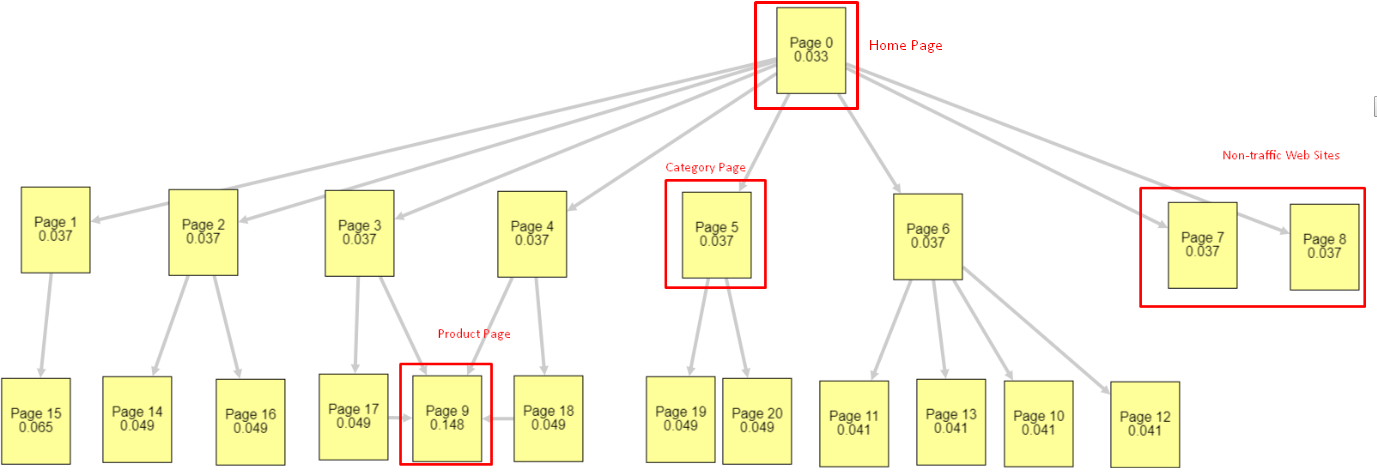
This example is closer to our situation before the June 5th Core Algorithm Update.. Homepage PR: 0.033, Category Page: 0,037, Product Page: 0,148 and Non-Traffic Pages’ PR: 0,037.
As you may notice, internal link structure is still not right but at least Non-Traffic Web Pages don’t have more PR than Category Pages and Product Pages.
What is further proof that Google has taken the internal link and site structure out of the Pagerank scope according to user flow and requests and intentions? Of course Googlebot’s behavior and Inlink Pagerank and Ranking Correlations:
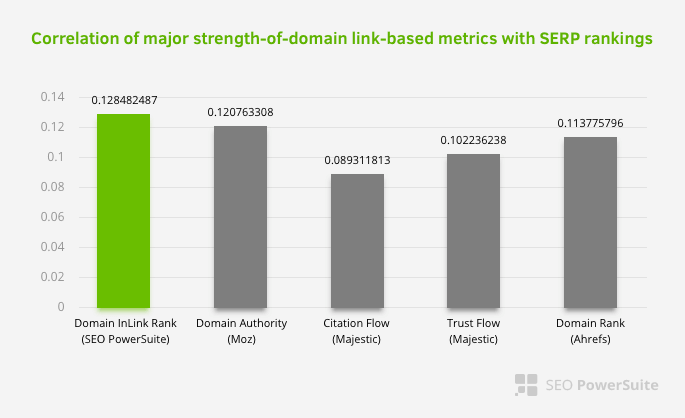
This does not mean that the internal link network, especially, is more important than other factors. The SEO perspective that focuses on a single point can never be successful. In a comparison between third-party tools, it shows that the internal Pagerank value is progressing in relation to other criteria.
According to the Inlink Rank and rank correlation research by Aleh Barysevich, the pages with the most internal links have higher rankings than the other pages of the website. According to the survey conducted on 4-6 March 2019, 1,000,000 pages were analyzed according to the internal Pagerank metric for 33,500 keywords. The results of this research conducted by SEO PowerSuite were compared with the different metrics of Moz, Majestic and Ahrefs and gave more accurate results.
Here are some of the internal link numbers from our site before March 12th Core Algorithm Update:
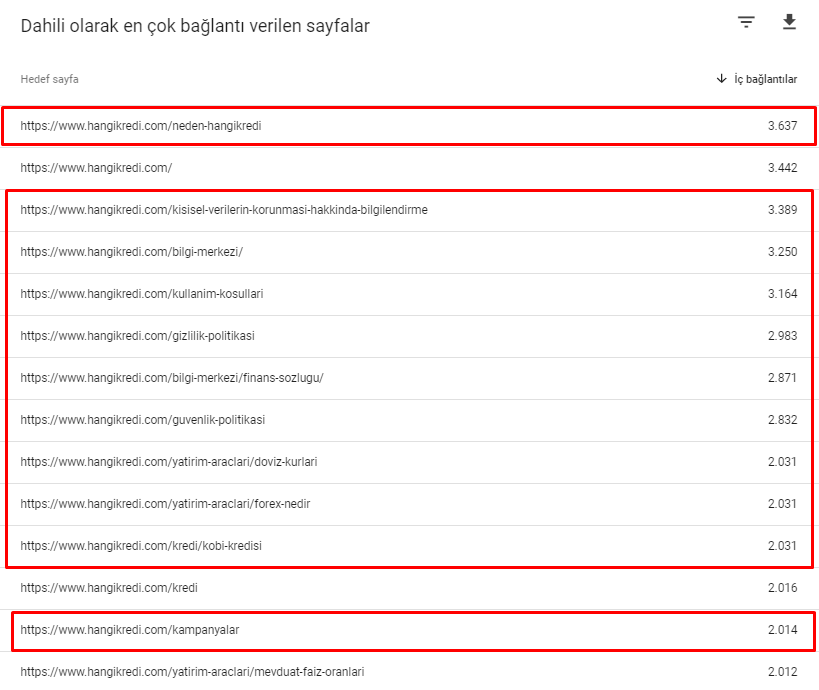
As you can see, our internal connection scheme did not reflect user intention and flow. The pages that receive the least traffic (minor product pages) or that never receive traffic (in red) were directly in the 1st Click Depth and receive PR from the homepage. And some had even more internal links than the homepage.
In the light of all this, there are only the last two points that we can show on this subject.
- Crawl Rate / Demand for the Most Internally Linked Pages
- Link Sculpting and Pagerank
Between 1 February and 31 March, here are the pages Googlebot crawled most frequently:
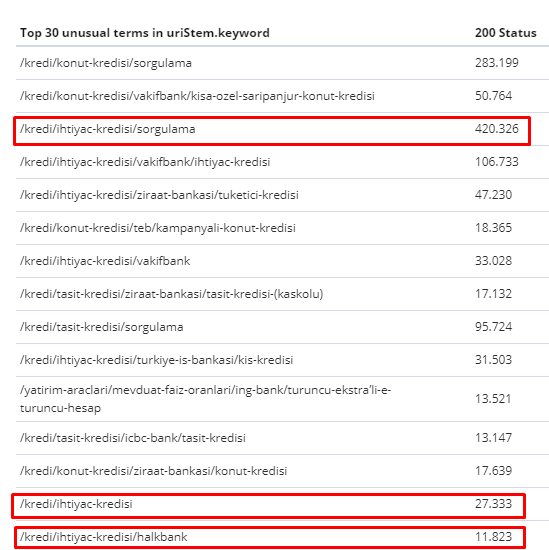
As you may notice, crawled pages and pages that have the most internal links are completely different from each other. Pages with the most internal links were not convenient for user-intent; they don’t have organic keywords or any kind of direct SEO value. (
The URLs in the red boxes are our most visited and important product page categories. The other pages in this list are second or third most visited and important categories.)
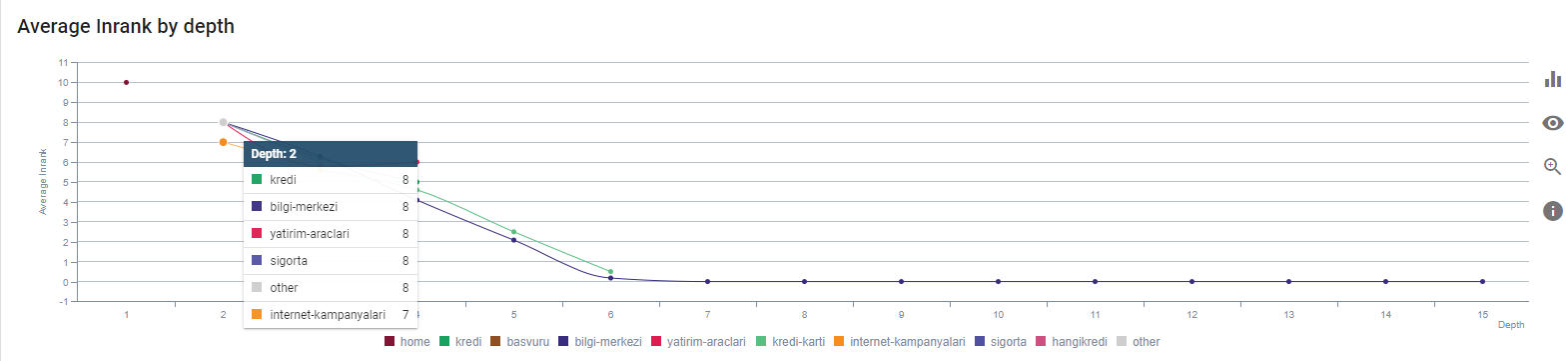
Our current Inrank by Page Depth. Source: Oncrawl.
What is Link Sculpting and What to do with Internally Nofollowed Links?
Contrary to what most SEOs believe, links marked with a “nofollow” tag still pass internal Pagerank value. For me, after all these years, no one has narrated this SEO element better than Matt Cutts in his Pagerank Sculpting Article from 15 June 2009.
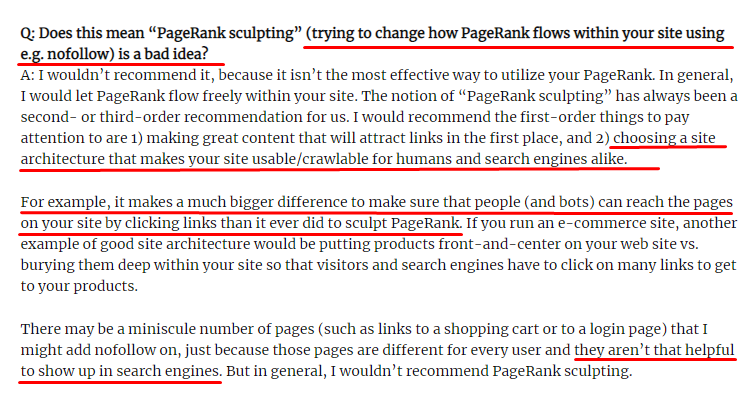
A useful part for Link Sculpting, which shows real purpose of Pagerank Sculpting.
“I’d recommend not using nofollow for kind of PageRank sculpting within a website because it probably doesn’t do what you think it does.”
–John Mueller, Google 2017
If you have worthless web pages in terms of Google and users, you shouldn’t tag them with “nofollow”. It won’t stop the Pagerank flow. You should disallow them from robots.txt file. In this way, Googlebot won’t crawl them but also it won’t pass the Internal Pagerank to them. But you should use this only for really worthless pages, as Matt Cutts said ten years ago. Pages which make automatic redirects for affiliate marketing or pages with mostly no content are some convenient examples here.
Solution: Better and More Natural Internal Linking Structure
Our competitor had a disadvantage. Their website had more anchor text, more internal links, but their structure was not natural and useful. The same anchor text was used with the same sentence on each page on their site. The entry paragraph for each page was covered with this repetitive content. Every user and Search Engine can easily recognize that this is not a natural structure that considers the user’s benefit.
So I decided on three things to do in order to fix the internal link structure:
- Site Information Architecture or Site-Tree should follow a different path from the links placed within the content. It should follow more closely the user’s mind and a keyword neural network.
- In each piece of content, the side keywords should be used along with the main keywords of the targeted page.
- Anchor texts should be natural, adapted to the content, and should be used at a different point on each page with attention to the user’s perception
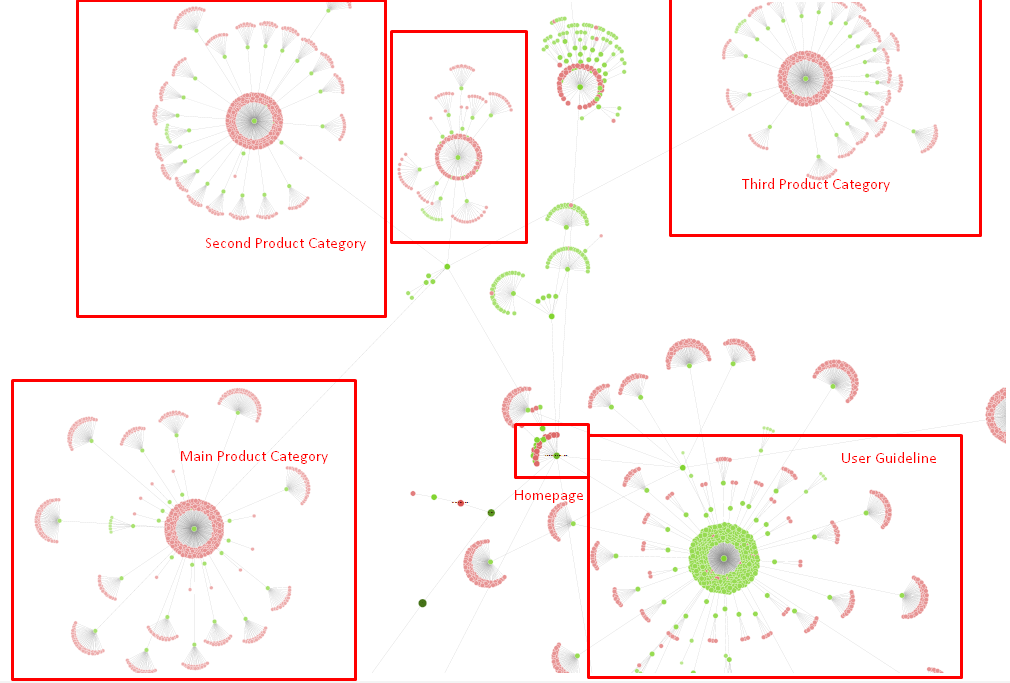
Our site-tree and a part of inlink structure for now.
In the diagram above, you can see our current internal link link and site tree.
Some of the things we did for fixing this problem are below:
- We created 30 000 more internal links with useful anchors..
- We used natural spots and keywords for the user.
- We didn’t use the repetitive sentences and patterns for internal linking.
- We gave the right signals to the Googlebot about Inrank of a webpage.
- We examined the effects of correct internal link structure on the crawl efficiency via Log Analysis and we saw that our main product pages were crawled more compared to previous stats.
- Created more than 50 000 internal links for orphaned pages.
- Used home page internal links for powering the sub-pages and created more internal link sources on the home page.
- For protecting Pagerank Power, also we used nofollow tag for some unnecessary external links. (This wasn’t about internal links but it serves the same goal.)
3. Problem: Content Structure
Google says that for YMYL websites, trustworthiness and authority are way more important than for other types of sites.

In the old days, keywords were just keywords. But now, they are also entities which are well defined, singular, meaningful and distinguishable. In our content, there were four main problems:
- Our content was short. (Normally, length of content is not important. But in this case, they didn’t contain enough information about the topics.)
- Our writers’ names were not singular, meaningful or distinguishable as an entity.
- Our content was not eye-friendly. In other words, it was not “fast-food” content. It was content without subheadings.
- We used marketing language. In the space of one paragraph, we could identify the brand name and its advertising for the user.
- There were lots of buttons that sent users to the product pages from informational pages.
- In the contents of our product pages, there was not enough information or comprehensive guidelines.
- Design was not user-friendly. We were using basically the same colour for font and background. (This is mostly still the case because of infrastructure problems.)
- Images and videos hadn’t been seen as a part of content.
- User-intent and search-intent for a specific keyword hadn’t been seen as important before.
- There was a lot of duplicate, unnecessary and repetitive content for the same topic.
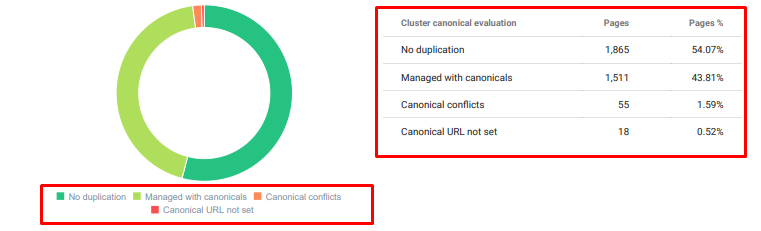
Oncrawl Duplicated Content Audit from today.
Solution: Better Content Structure for User Trust
When checking a site-wide problem, using a site-wide audit program as assistant is a better way to organize time spent on SEO Projects. Like in the internal link section, I used Oncrawl Site Audit along with other tools and Xpath inspections.
Firstly, fixing every problem in the content section would have taken too much time. In those collapsing crisis days, time was a luxury. So I decided to fix quick-win problems such as:
- Deleting Duplicate, Unnecessary and Repetitive Content
- Unifying Short and Thin Content lacking comprehensive information
- Republishing content that lacked subheadings and eye-trackable structure
- Fixing Intensive Marketing Tone in the Content
- Deleting Lots of Call To Action Buttons from Content
- Better Visual Communication with Images and Videos
- Making content and target keywords compatible with user and search intent
- Using and showing financial and educational entities in the content for trust
- Using social community for creating social proof of approval
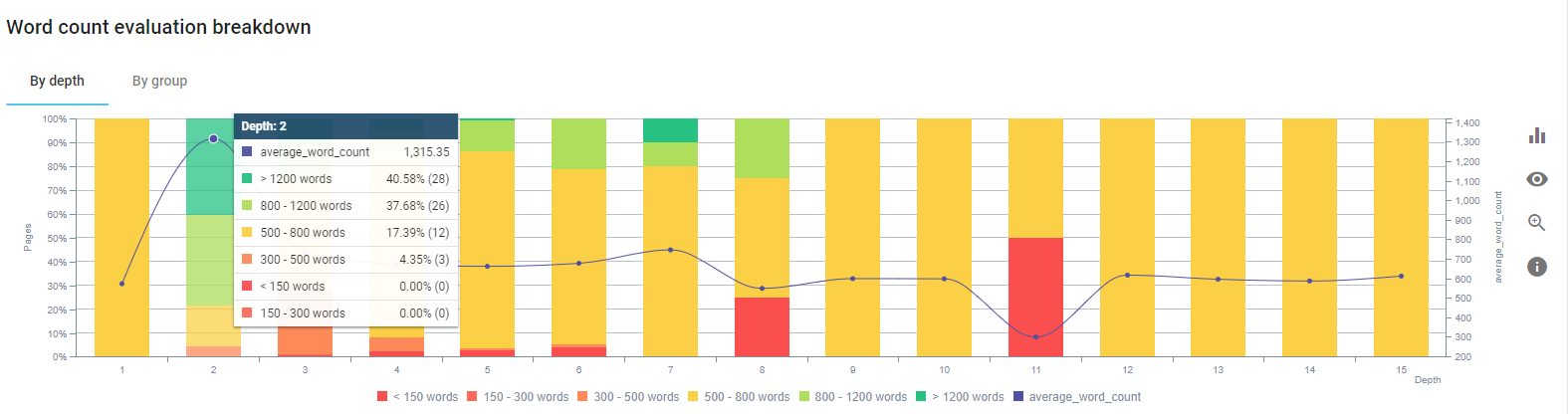
We concentrated on fixing the contents of product pages and the guide pages closest to them.
At the beginning of this process, most of our product and transactional landing/guideline pages had less than 500 words without comprehensive information.
In 25 days, the actions we carried out are below:
- Deleted 228 pages with duplicate, unnecessary and repetitive content. (Ccontent’s backlink profiles were checked before process of deleting. And we used 301 or 410 status codes for better communication with Googlebot.)
- Combined more than 123 pages lacking comprehensive information.
- Used subheadings according to their importance and user-demand in the contents.
- Deleted brand name and CTA buttons with marketing styled language.
- Include text in images to reinforce the main topic.
This is a screenshot from Google’s Vision AI. Google can read text in images and detect feelings and identities within entities.
- Activated the our social network to attract more users.
- Examined content gap between competitors and us and created more than 80 new pieces of content.
- Used Google Analytics, Search Console and Google Data Studio to determine the underperformed pages with a high bounce rate and low traffic.
- Did research for Featured Snippets and their keywords and content structure. We added the same headings and content structure into our related contents This increased our Featured Snippets.
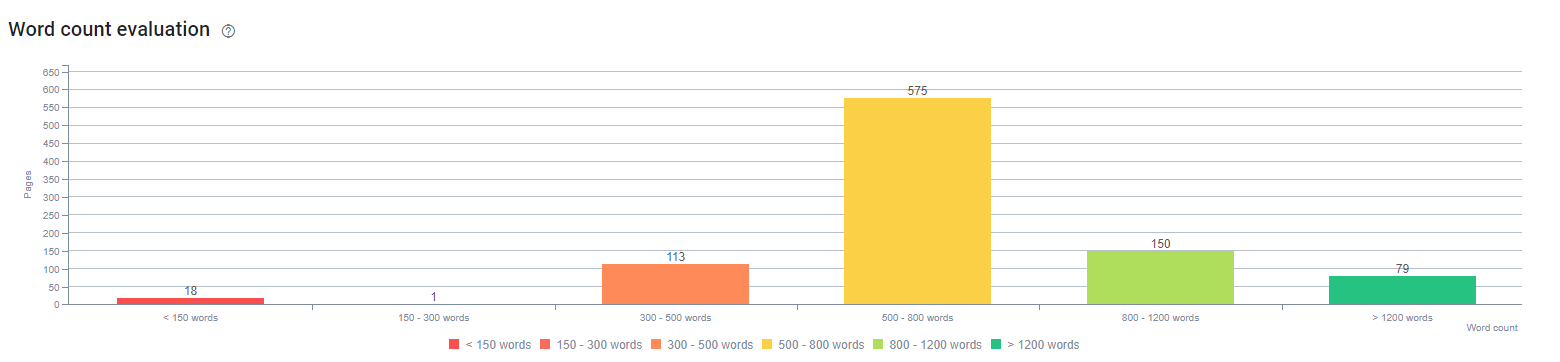
At the beginning of this process, our contents were consisted of mostly between 150 and 300 words. Our averagely content length increased by 350 words for sitewide.
4. Problem: Index Pollution, Bloat and Canonical Tags
Google has never made a statement about Index Pollution and in fact I am not sure whether someone has used it as an SEO term before or not. All pages that don’t make sense to Google for a more efficient index score should be removed from Google index pages. Pages that cause index pollution are pages that haven’t produced traffic for months. They have zero CTR and zero organic keywords. In the cases where they have a few organic keywords, they would have to become a competitor of other pages on your site for the same keywords.
Also, we had carried out research for index bloat and found even more unnecessary indexed pages. These pages existed because of an erroneous site information structure, or because of a bad URL structure.
Another reason for this problem was incorrectly used canonical tags. For more than two years, canonical tags have been treated as just hints for Googlebot. If they are used incorrectly, Googlebot will not calculate them or pay attention to them while valuing the site. And also, for this calculation, you will probably consume your crawl budget inefficiently. Because of incorrect canonical tag usage, we had more than 300 comment pages with duplicate content get indexed.
My theory’s aim to show Google only quality and necessary pages with potential of earning clicks and creating value for users.
Solution: Fixing Index Pollution and Bloat
First, I took advice from John Mueller of Google. I asked him if I used noindex tag for these pages but still let Googlebot to follow them, “would I lose link equity and crawl efficiency?”
As you can guess, he said yes at first but then he suggested that using internal links can overcome this obstacle.
I also found that using noindex tags at the same time as dofollow decreased crawl rate by Googlebot on these pages. These strategies allowed me to make Googlebot crawl my product and important guideline pages more often. I also modified my internal link structure as John Mueller advised.
In a short time:
- Unnecessary indexed pages were discovered.
- More than 300 pages were removed from the index.
- Noindex tag was implemented.
- Internal link structure was modified for the pages that received links from pages that were removed from the index.
- Crawl efficiency and quality was examined over time.
5. Problem: Wrong Status Codes
At the beginning, I noticed that Googlebot visits lots of deleted content from the past. Even pages from eight years ago were still being crawled. This was due to the use of incorrect status codes especially for deleted content.
There is a huge difference between 404 and 410 functions. One of them is for an error page where no content exists and the other one is for deleted content. In addition, valid pages also referenced a lot of deleted source and content URLs. Some deleted images and CSS or JS assets were also used on the valid published pages as resources. Finally, there were lots of soft 404 pages, and multiple redirect chains, and 302-307 temporary redirects for permanently redirected pages.
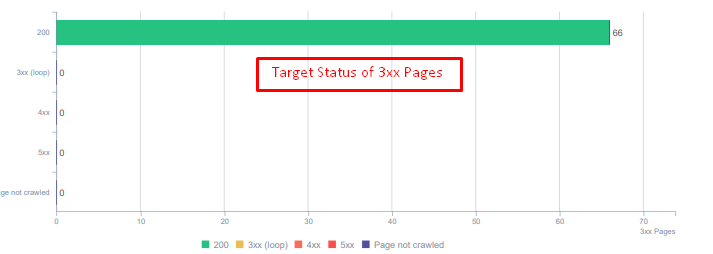
Status codes for redirected assets today.
Solution: Fixing Wrong Status Codes
- Every 404 status code was converted to 410 status code. (More than 30000)
- Every resource with 404 status code was replaced with a new valid resource. (More than 500)
- Every 302-307 redirect was converted to 301 permanent redirect. (More than 1500)
- Redirect chains were removed from the assets in use.
- Every month, we had received more than 25 000 hits on pages and resources with a 404 status code in our Log Analysis. Now, it is less than 50 for 404 status codes per month and zero hits for 410 status codes…
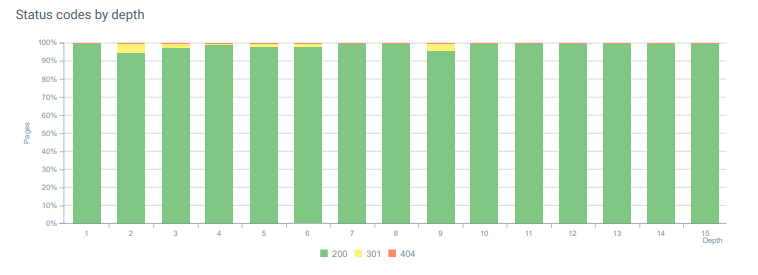
Status codes throughout page depth today.
6. Problem: Semantic HTML
Semantics refers to what something means. Semantic HTML includes tags that give the meaning for page component within a hierarchy. With this hierarchical code structure, you can tell Google what the purpose of a part of the content is. Also, in the case where Googlebot can’t crawl every resource required to fully render your page, you can at least specify the layout of your web page and the functions of your content parts to Googlebot.
On Hangikredi.com, after the 12 March Google Core Algorithm Update, I knew that there was not enough crawl budget due to unoptimised web site structure. So, in order to make Googlebot understand the web page’s aim, function, content and usefulness more easily, I decided to use Semantic HTML.
Solution: Semantic HTML Usage
According to Google’s Quality Rater Guidelines, every searcher has an intent and every web page has a function according to that intent. To prove these functions to Googlebot, we made some improvements to our HTML Structure for some of the pages that are crawled less by Googlebot.
- Used <main> tag for showing main content and function of the page.
- Used <nav> for the navigational part.
- Used <footer> for the footer of site.
- Used <article> for the article.
- Used <section> tags for every heading tag.
- Used <picture>, <table>, <citation> tags for images, tables and quotes in the content.
- Used, <aside> tag for the supplementary content.
- Fixed the H1-H6 Hierarchy Problems (Despite Google’s latest “using two H1 is not a problem” statement, using the right structure, helps the Googlebot.)
- Like in Content Structure section, we also used Semantic HTML for Featured Snippets, we used tables and lists for more Featured Snippet results.
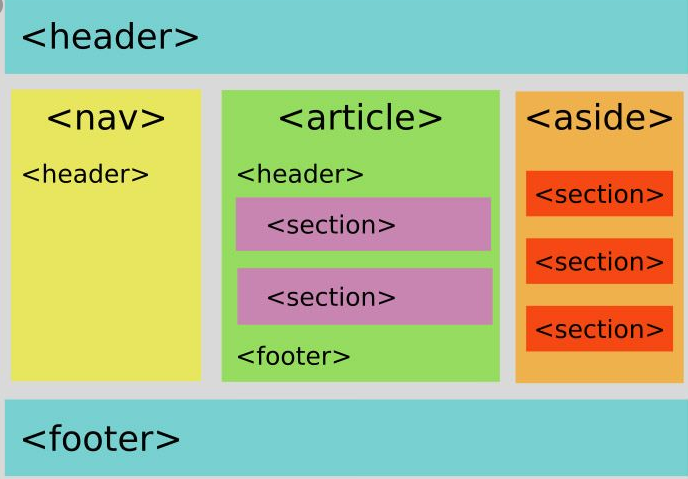
For us, this was not a realistically implementable development for the entire site. Still, with every design update, we are continuing to implement Semantic HTML tags for additional web pages.
7. Problem: Structured Data Usage
Like Semantic HTML usage, Structured Data may be used to show the functions and definitions of web page parts to Googlebot. In addition, Structured Data is compulsory for rich results. On our web site, structured data wasn’t used or, more commonly, was used incorrectly until the end of March. In order to create better relations with entities on our web site and our off-page accounts, we started to implement Structured Data.
Solution: Correct and Tested Structured Data Usage
For financial institutions and YMYL Websites, Structured Data can fix lots of problems. For example, they can show the identity of the brand, the kind of content and create a better snippet view. We used the following structured data types for sitewide and individual pages:
- FAQ Structured Data for Main Product Pages
- WebPage Structured Data
- Organisation Structured Data
- Breadcrumb Structured Data
8. Sitemap and Robots.txt Optimisation
On Hangikredi.com, there is no Dynamic Sitemap. The existing sitemap at the time did not include all necessary pages and also included deleted content. Also, in the Robots.txt file, some of the affiliate referrer pages with thousands of external links weren’t disallowed. This also included some third-party JS files which are unrelated to content and other additional resources that were unnecessary for Googlebot.
The following steps were applied:
- Created a sitemap_index.xml for multiple sitemaps which are created according to site categories for better crawling signals and better coverage examination.
- Some of the third-party JS files and some unnecessary JS files were disallowed in robots.txt file.
- Affiliate pages with external links and no landing page value were disallowed, as we mentioned in the section of Pagerank or Internal Link Sculpting.
- Fixed more than 500 coverage problems. (Most of them were pages which indexed despite being disallowed by Robots.txt.)
You can see our crawl rate, load and demand increase from the chart below:
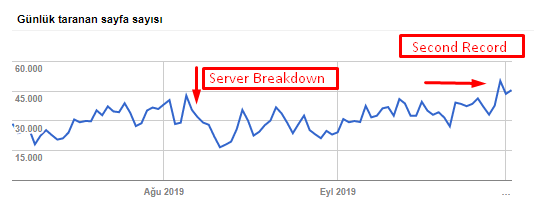
Crawled page count per day by Googlebot. There was a steady increase in pages crawled per day until 1 August. After an attack caused a server failure in early August, it regained its stability in slightly over a month.
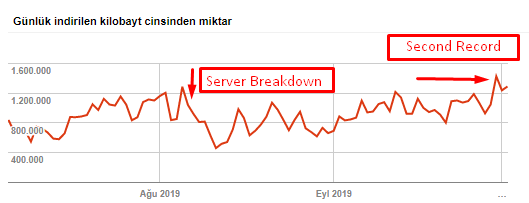
Crawled Load per day by Googlebot has evolved in parallel with the number of pages crawled per day.
9. Fixing AMP Problems
On the firm’s web site, every blog page has an AMP version. Because of incorrect code implementation and missing AMP canonicals, all of the AMP pages were repeatedly deleted from the index. This created an unstable index score and lack of trust for the website. Additionally, AMP pages had English terms and words by default on Turkish content.
- Canonical tags were fixed for more than 400 AMP pages.
- Incorrect code implementations were found and fixed. (It was mainly due to incorrect implementation of AMP-Analytics and AMP-Canonical tags.)
- English terms by default were translated into Turkish.
- Index and ranking stability was created for the blog side of the firm’s website.
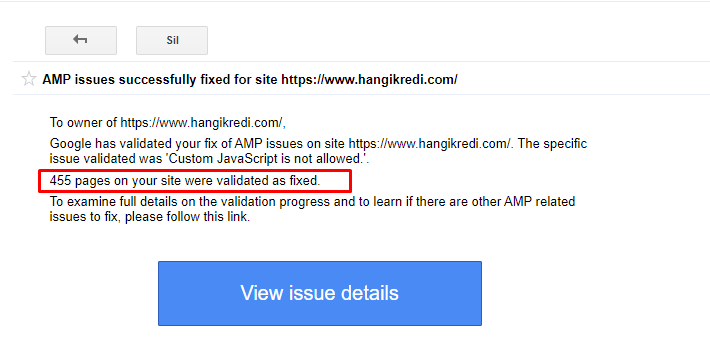
An example message in GSC about AMP Improvements
10. Meta Tag Problems and Solutions
Because of the crawl budget issues, sometimes in critical search queries for important main product pages, Google didn’t index or display content in the meta tags. Instead of meta title, the SERP listing showed only the firm name built from two words. No snippet description was shown.. This was lowering our CTR and harming our brand identity. We fixed this problem by moving the meta tags to the top of our source code as shown below.
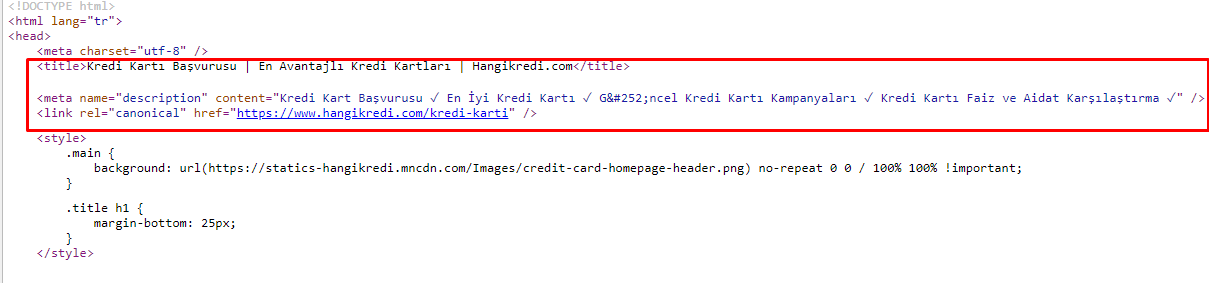
Beside for crawl budget, we also optimised more than 600 meta tags for transactional and informative pages:
- Optimised character length for mobile devices.
- Used more keywords in the titles
- Used different style of meta tags and examined the CTR, Keyword Gap and Ranking Changes
- Created more pages with correct site-tree structure for targeting secondary keywords better thanks to these optimisation processes.
- On our site, we still have different meta titles, descriptions and headings for testing Google’s algorithm and search user CTR.
11. Image Performance Problems and Solutions
Image problems can be divided into two types. For content convenience and for page speed. For both, firm’s web still site has lots to do.
In March and April following the negative 12 March Core Algorithm Update:
- Images didn’t have alt tags or they had wrong alt tags.
- They didn’t have titles.
- They didn’t have correct URL structure.
- They didn’t have next generation extensions.
- They didn’t get compressed.
- They didn’t have the right resolution for every device screen size.
- They didn’t have captions.
To prepare for the next Google Core Algorithm Update:
- Images were compressed.
- Their extensions were partially changed.
- Alt tags were written for most of them.
- Titles and captions were fixed for the user.
- URL structures were partially fixed for the user.
- We found some unused images which are still being loaded by the browser, and deleted them from the system.
Because of site infrastructure, we partially implemented image SEO corrections.
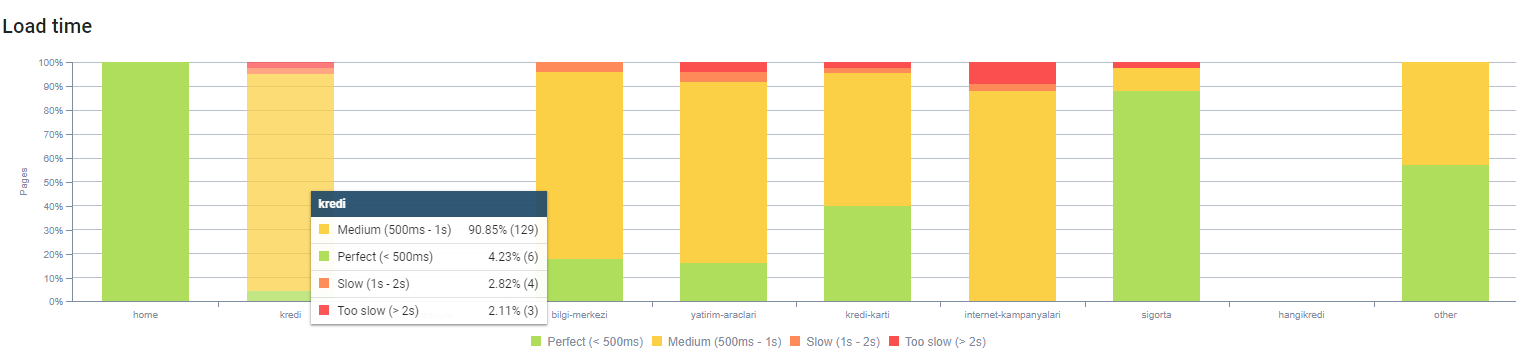
You can observe our page load time by page depth above. As you can see, most of the product pages are still heavy.
12. Cache, Prefetch and Preload Problems and Solutions
Before the 12 March Core Algorithm Update, there was a loose cache system on firm’s web site. Some of the content parts were in the cache but some of them weren’t. This was especially a problem for product pages because they were slower than our competitor’s product pages by 2x. Most of the components of our web pages are actually static sources but still they didn’t have Etags for stating the cache range.
To prepare for the next Google Core Algorithm Update:
- We cached some components for every web page and made them static.
- These pages were important product pages.
- We still don’t use E-Tags because of site infrastructure.
- Especially images, static resources and some important content parts are now fully cached sitewide.
- We have started to use dns-prefetch code for some forgotten outsourced resources.
- We still don’t use the preload code but we are working on user-journey on the site in order to implement it in the future.
13. HTML, CSS and JS Optimising and Minifying
Because of the site infrastructure issues, there were not so many things to do for site speed. I tried to close the gap with every method I could, including deleting some page components. For important product pages, we cleaned the HTML code structure, minified and compressed it.
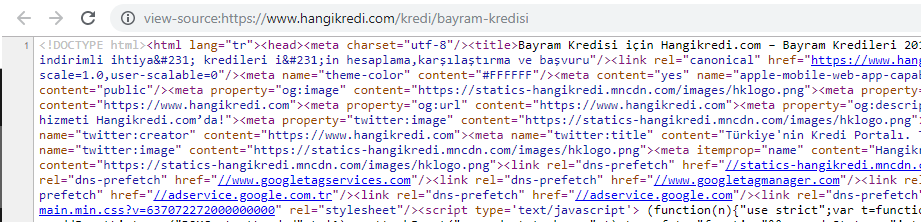
A screenshot from one of our seasonal but important product page’s source code. Using FAQ Structured Data, HTML Minifying, Image Optimisation, Content refreshing and Internal Linking gave us the first rank at the right time. (Keyword is “Bayram Kredisi” in Turkish, meaning “Holiday Credit”)
We also implemented CSS Factoring, Refactoring and JS Compression partially with small steps. When the rankings dropped, we examined the site speed gap between our competitor’s pages and ours. We had chosen some urgent pages which we could speed up. We also partially purified and compressed critical CSS files on these pages. We initiated the process of removing some of the third-party JS files used by different departments of the firm, but they have not been removed yet. For some product pages, we were also able to change the resource loading order.
Examining the Competitors
In addition to every technical SEO improvement, inspecting competitors was my best guide to understanding a Core Algorithm Update’s nature and aims. I have used some useful and helpful programs to follow my competitor’s design, content, rank and technology changes.
- For keyword ranking changes, I used Wincher, Semrush and Ahrefs.
- For Brand Mentions, I used Google Alerts, BuzzSumo, Talkwalker.
- For new link and new keyword gaining reports I used Ahrefs Alert.
- For content and design changes, I used Visualping.
- For technology changes, I used SimilarTech.
- For Google Update News and Inspection, I mainly used Semrush Sensor, Algoroo and CognitiveSEO Signals.
- For inspecting URL history of competitors, I used the Wayback Machine.
- For server speed of competitors, I used Chrome DevTools and ByteCheck.
- For crawl and render cost, I used “What Does My Site Cost”. (Since last month, I have started using Onely’s new JS Tools like WWJD or TL:DR..)

A screenshot from SimilarTech for my main competitor.
A screenshot from Visualping which shows the layout changes for my secondary competitor.
Testing the value of the changes
With all of these problems identified and solutions in place, I was ready to see whether the website would hold up to the next Google core algorithm updates.
In the next article, I’ll look at the major core algorithm updates over the next several months, and how the site performed.
