
In May, we held a webinar in French on Google’s crawl budget. For his second webinar with Oncrawl, Erlé Alberton, ex head of SEO for Orange & Sosh ( a French Internet provider) and now Customer Success Manager for Oncrawl introduces the crawl budget concept, best practices to optimize it, what to avoid, etc. Practical examples will illustrate this concept that was recently confirmed by Google’s team.
What Google says about crawl budget
Mid-January, Google posted an article on their blog stating: “we don’t have a single term that would describe everything that “crawl budget” stands for externally. ” In other words what we, SEOs, consider as the crawl budget.
The web giant also indicates that if your new pages are usually crawled the same day of their publication, then you do not really have to worry about the crawl budget. It also states that if a site has fewer than a few thousand URLs, it will be crawled correctly as crawl budget is usually reserved for high volume sites… This is both right and wrong because all sites in Google Search Console have a crawl budget. We can easily see this in the Google metrics.
We also find out in this article that Google is trying to achieve a “crawl rate limit” which limits the maximum fetching rate for a given site. We can see that, for example, when a loading time is too long, Google cuts its budget almost in 2. With that being said, there are factors that can impact the crawl budget such as bad architecture (system, status codes, internal structure), poor and / or duplicate content, spider traps, etc.
How does Google’s crawl budget work?
Google’s crawl is a set of simple steps that operates recursively for each site. Here’s a graph from Google where we see that the crawl starts with a hit on a txt robot and then it separates in a set of URLs that are compiled in a list. Afterwords, Google attempts to fetch them while comparing with the URLs he already knows in addition to the ones he already has in backup.

Its goal is to exhaustively and precisely complete its index. We see that even if the site is in JavaScript, Google will send third level crawlers. You should still be careful with JavaScript sites, as they consume a lot of bot resources and are sent on average only once a quarter. We need to rethink our method so that Google has access to pages outside a JavaScript navigation.
Google will then check the page update’s status (comparison with content indexed previously) to evaluate whether the page is important or less important. Indeed, Google needs to optimize its crawl resources because it can not crawl every page of all web sites. It’s called page importance… it’s a very important score to follow and that we will see in details below!
Fact: if Google optimizes, it’s because there’s a reason
Crawl budget depends on:
- Site’s capacity to answer quickly;
- Site’s sanity – 4xx, 5xx, 3xx (when a site starts to have 404s or 500s, the crawl budget will be affected, because it will always double check if fixes have been made);
- Content’s quality – semantics and exhaustivity;
- Anchor’s diversity (a page is considered important when it receives a lot of links. With Oncrawl’s InRank you can analyze the whole thing);
- Page popularity – external and internal;
- Optimizable factors – simplify the crawl (reduce image size, capacity to have css, js, gif, fonts, etc.)

[Case Study] Increase crawl budget on strategic pages

Google Page Importance’s key components
Page importance definition is not the same as Page Rank:
- Page location in the website – depth on crawl rate;
- Page Rank: Page’s TF/CF – Majestic;
- Internal Page Rank – Oncrawl’s InRank;
- Type of document : PDF, HTML, TXT (PDF is usually a final qualitative document so it gets crawled a lot);
- Inclusion in sitemap.xml;
- Number of internal links:
- Anchor’s quality/importance;
- Qualitative content: number of words, few near duplicates (Google will penalize similar content if the pages are too close in content);
- Importance of the “home”’ page.
How to plan important URLs to crawl

URL scheduling: What pages does Google want to visit and how often?
In the example above, (observation of a crawl frequency of a same site) Google does not crawl at the same frequency on the different groups. We see that when Google crawls part of the site, the ranking’s impact is seen quickly.
More information on Google’s crawl budget
- 100% of Google Search Console’s websites have crawl data;
- We can follow its crawl behavior thanks to a log analysis that helps you detect quickly an abnormality in the bot’s behavior;
- A bad internal structure (pagination, orphan pages, spider traps) can stop Google from crawling the right pages;
- Crawl budget is directly linked with ranking.

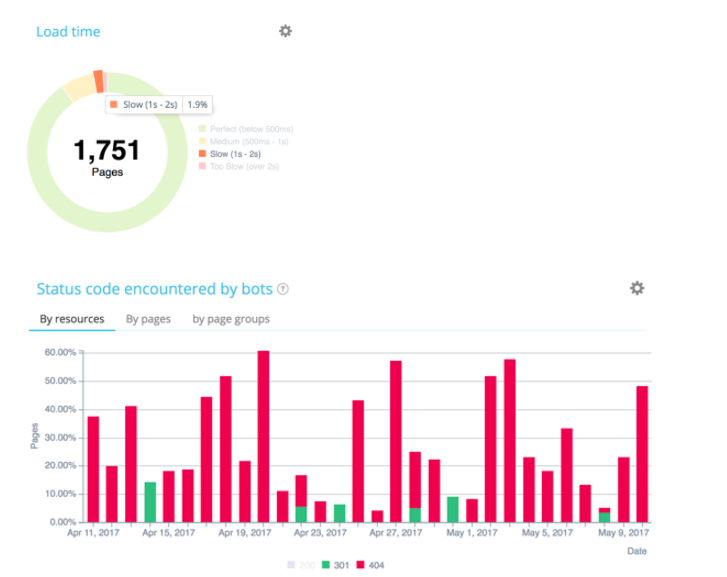
Page Speed First
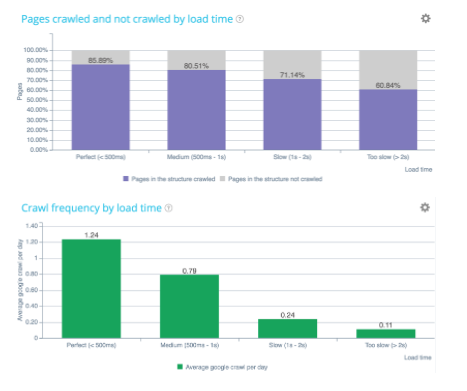
The most important factor is a page’s load time as it plays a decisive role on the crawl budget. Indeed, we’re today in a mobile world. Your best asset is therefore the page’s loading time to optimize your crawl budget and your SEO. With the mobile revolution, load time is an essential factor in assessing the quality of a site. Its ability to respond quickly – especially for mobile and index mobile first.
To optimize it, we can use CDN solutions (Content Delivery Network) like Cloudflare. These solutions allow Google’s robots to be as close to resources as possible and load pages as quickly as possible.
Google constantly tests the ability of a site to respond quickly. Architecture and coding quality have a strong impact on Google’s notation.
Load time
It’s the crawl budget’s first allocation factor!
Server wise, you need to:
- Avoid redirections;
- Authorize compression;
- Improve response time.

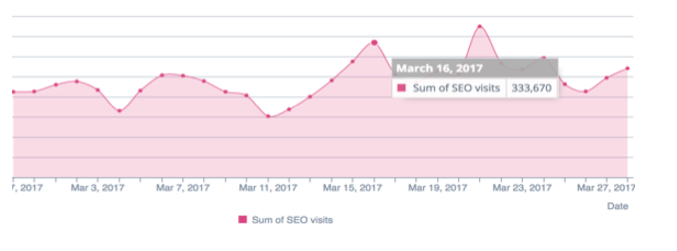
Above, an example with Manageo’s site which had a linear crawl budget and where we can see a linear increase. In May, there’s a drop in the number of pages crawled per day and consequently a change in the site’s speed. Google sees that the site responds less quickly so it cuts in half its crawl budget. To correct all this, you have to optimize your codes on the server side, reduce redirections, use compression, and so on.
Front wise, you need to:
- Operate browser caching
- Reduce resources size (image optimization, use CDN/lazy loading/delete JS that block display;
- Use asynchronous scripts.
Drop in quality = no more love = no more budget
It’s necessary to check the status codes sent back to Google’s robots to ensure that the IS is clean. This is the only way for Google to validate that the quality of your code and your architecture is clean.
Tracking their evolution over time ensures that code updates are SEO friendly. Google spends a lot on resources (css, img, js) so make sure they are flawless.
Unique and rich content
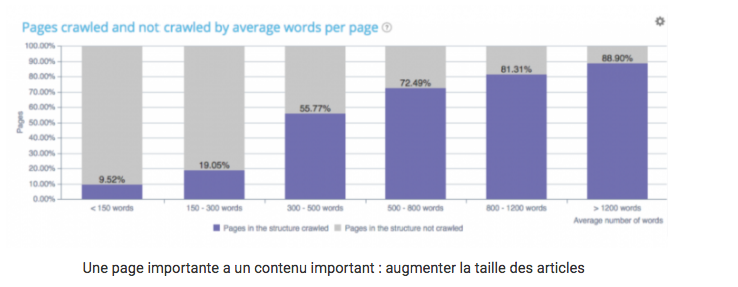
More important a page is, the richer its text is. As shown above, the number of pages crawled and not crawled by Google is related to the number of words that are on the page. Your pages should therefore be enhanced and updated as regularly as possible.
Beware of canonicals and duplicate content
Google will spend twice as much budget when two similar pages do not point to the same canonical URL. Thus, canonical management can become critical for sites with facets, or external links with queryString.
Content management in near duplicate and canonicals become important aspects of crawl budget optimization.
Internal structure and InRank distribution

Pages that generate SEO visits are considered active. These are the ones that are at the top of the site’s architecture. On the other hand, we see here that on page 15 there is a group of pages emerging. Maybe these pages are much more searched by your users than you thought and would need to be upgraded in the architecture to improve their ranking.

As we know, the deeper the pages are, the less Google will visit them!
Are my money pages well located?
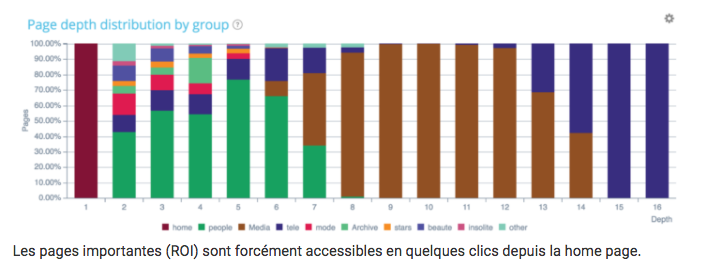
Tip: If you want to optimize the depth of certain groups of pages, do not hesitate to create html site plans, meaning pages that are crucial for managing your depth.

Google will compare the pages of your structure vs crawled vs active. That said, it would be to your advantage to solve the problem of orphaned pages for which Google spends unnecessarily budget and fix the site’s architecture to return links towards active but out-of-structure pages.
Sometimes pages do not receive links anymore, they are called orphaned pages. On the other hand, Google has not forgotten about them. He will continue to visit them. They no longer receive links so they lose importance, but in the right graph, some orphaned pages continue to receive SEO visits. What you need to know is how to identify them quickly and fix the linking problems that are in the architecture. This is a great way to optimize your crawl budget.
Mistakes to stay away from
- Robots.txt in 404;
- Sitemap.xml & sitemap.html out of date;
- 50x / 40x / soft 404 errors;
- Having chain redirections;
- Canonicals errors;
- Duplicate content (footer) / near duplicate / HTTP vs HTTPS;
- Too long response time;
- Page heaviness too important;
- AMP/ errors. This protocol is widely used by Google especially for e-commerce sites (not just media sites);
- Bad internal linking + Rel=nofollow;
- Using JS without any other alternative.
Conclusions
To optimize your crawl budget, you need to:
- Know your money pages and know Google’s reactions;
- Improve load time;
- Optimize your internal linking: put all your money pages at the top of the structure;
- Fix your orphaned pages;
- Add text to your money pages;
- Update to the fullest your money pages – freshness;
- Reduce your poor content and duplicates;
- Optimize your canonicals, images, resources weight;
- Avoid chain redirections;
- Monitor your logs and react when there are abnormalities (check out this use case from Manageo during SEOcamp Lyon on the topic).
To optimize your crawl budget, you need to monitor precisely Google’s crawler

Some moments of Google’s path on your site are more important than others so you have to know how to optimize them.
To optimize your crawl budget, it’s necessary to manage correctly your HTTPS (HTTP2) migration

You need to be able to follow and monitor it. Challenge your IT teams to migrate to HTTP2 with HTTPS.
Oncrawl helps you track Google’s crawl budget on a day-to-day basis and quickly targets fixes and structural changes to improve your SEO performance.
