
What is Machine Learning?
The following quotes really sum it up.
More fluid
“Machine learning is something new under the sun: a technology that builds itself.”
Pedro Domingos
More intuition
“Machine learning is as much art as it is science. It’s like cooking — yes, there’s chemistry involved but to do something really interesting, you have to learn how to combine the ingredients available to you.” Greg Corrado, (Google)
More flexibility
“The machine learning model is not a static piece of code — you’re constantly feeding it data. We are constantly updating the models and learning, adding more data and tweaking how we’re going to make predictions. It feels like a living, breathing thing. It’s a different kind of engineering.” Christine Robson (Google)
Cool !
All three quotes from this great article https://www.wired.com/2016/06/how-google-is-remaking-itself-as-a-machine-learning-first-company/
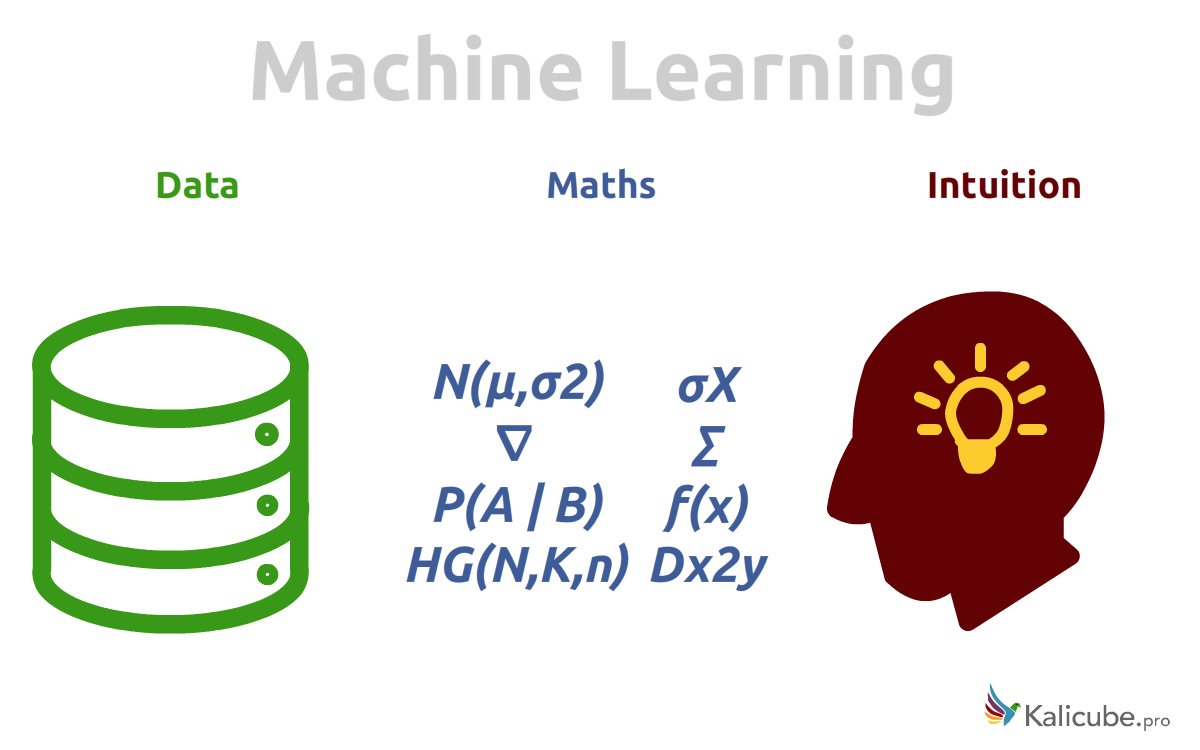
Machine Learning is like cooking
Cooking: ingredients, kitchen equipment and a cook’s flair.
Machine Learning: data, mathematics and an engineer’s intuition.
Machine Learning vs Traditional Code
Whereas traditional code is very much a static science, using a static series of if/else statements, machine learning is a fluid “being”. Each time we ask a question (input) to get an answer (output), the path to return the answer is unique, written on the fly by a machine that has been guided, rather than instructed. And each time it does a task, it learns and can apply that learning to do that task a little better next time.
Mind blowing stuff.
The basic types of Machine Learning
Supervised machine learning involves feeding reliable labelled data to a machine and providing it with the expected result, then asking it to find the formula to deduce the result from the data. Once the formula has been defined from labelled data, we can feed unlabelled data of the same type to the machine and get reliable predictions. AlphaGo is a great example of this – to learn to play Go, it was fed 10 million human games and then beat the world champion.
Unsupervised machine learning – give the machine a basic set of tools, a data source, and a desired result and let the machine label the data and find the path. AlphaGo Zero is a great example of this – it was given the rules to Go and the aim of the game (to win), then left to play itself millions of times. It took just 2 days to learn to play well enough to beat AlphaGo 100 times in a row.
So, in a game with a set of precise rules, Google has the capacity to use unsupervised learning surpass 4000 years of human endeavour in just a couple of days. That neatly emphasises the scale of progress theoretically possible.
Spoiler: Although unsupervised is the Eldorado of machine learning, Google is unlikely to unleash it in the sphere of SEO / AEO since it would be highly dangerous for Google to hand over its business model to a machine – some level of supervision has to be maintained.
So, in SEO and AEO (Answer Engine Optimisation), we are interested in something inbetween – semi-supervised machine learning. Simply stated, that means building a foundation of supervised learning on reliable labelled data, and then extend self-learning using unlabelled data in a controlled manner.
Why is it suddenly such a big deal now ?
Heavy-duty machine learning has only been possible for a few years because to really perform, it requires a set of tools that have never been quite powerful enough, and have never been available at the same time. The game just changed with the emergence of technologies such as Multi-threaded dedicated CPUs, big data, vector based SQL..
The availability of that technology means that the world just changed…
Google are now very clear that they are an AI-first company. Have a look here https://ai.google
Note: although not strictly true, for the purpose of this article, AI and Machine Learning can be considered to be synonyms.
Machine Learning moves the goalposts
Amit Singhal, head of search at Google since the early noughties, hails from the world of “retrievers” – engineers who write static code to collect information, sort through it and rank it according to a set of human-defined rules. Given Google’s success during his leadership, we can conclude he is incredibly good at that. David Pablo Cohn, a leading machine learning engineer at Google since 2002 said:
“It turns out that Amit’s intuition was the best in the world, and we did better by trying to hard code whatever was in Amit’s brain. We couldn’t find anything as good as his approach.”
But by 2014, Google’s machine learning team could beat the “retriever” approach and provide results of equivalent quality. But perhaps more importantly, they could do a much better job of identifying THE answer. With a switch to an approach 100% Machine Learning, Google is fast becoming an answer engine… an engine that aims to provide the definitive (correct) answer / solution to a users need in a given situation.
[Case Study] How business-oriented SEO increases traffic and conversions

RankBrain: Machine Learning in the core algorithm in 2015
When launched in 2015, RankBrain was the first official Machine Learning part of Google’s core algorithm. It was primarily aimed at improving the 15% of search queries Google had never seen before. 9 months later, Google announced it affected 100% of queries and had already become the third most important ranking factor.
That indicates just how reliable and performant their Machine Learning already was in 2016. Google has provided little concrete information, but over the last two years, other implementations have certainly been introduced. And I believe we have recently seen some of the most significant to date.
Three major core algorithm updates in 2018
So far in 2018 most tracking tools (SEMrush, Mozcast, RankRanger) have registered multiple strong and lengthy tremors in SERP volatility (I am ignoring the Mobile First Index update of March 22 since that is a special case).
- Sustained week-long tremor in January 2018
- Sustained week-long tremor in March 2018
- Sustained week-long tremor in April 2018
I dug a little deeper in SEMrush Sensor – looking back to April 2017. I took any Sensor Score of greater than 7 on their scale as being the start of a core update, and calculated the average tremor score over a week. Obviously not masses of data, but the results are quite an eye-opener.
Data courtesy of semrush.com
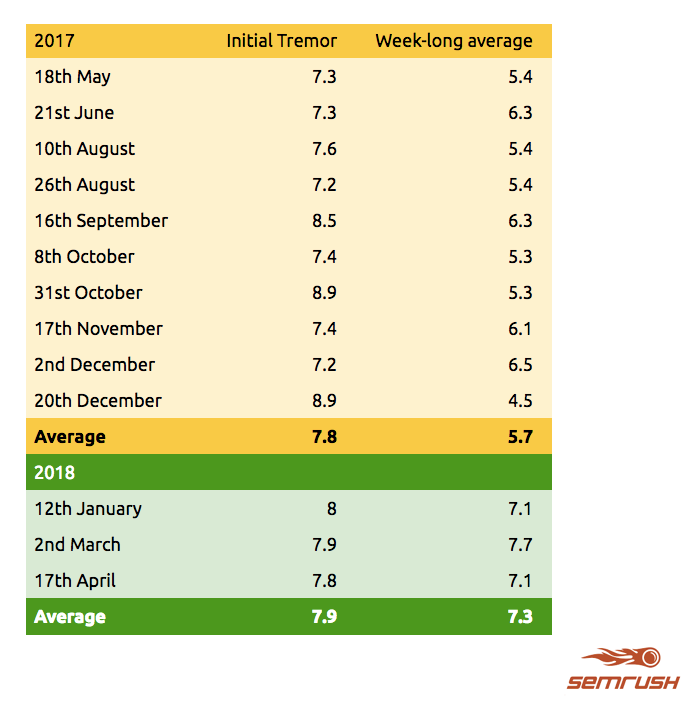
The updates in 2018 are significantly more active than 2017
- 2017 = 10 updates, with an average week-long tremor of 5.7
- 2018 = 3 updates, with an average week-long tremor of 7.3
The average week-long tremor in 2018 is 30% more intense than we saw in 2017.
All three 2018 updates show a week-long average of over 7.
None of the 10 updates in 2017 gets above 6.5.
Three significant core updates in 4 months with unusually long periods of sustained volatility, nothing in the way of specifics from Google, but insistence that they are not aimed at penalising low quality sites … In that context, this comment takes on a whole new meaning for me.
“There was always this battle between the retrievers and the machine learning people. The machine learners have finally won the battle.”
Pedro Domingos
Are we seeing the introduction of more Machine Learning in the core algorithm in 2018?
Google have previously stated that the learning itself is done offline.
Danny Sullivan (who now works for google)“All learning that RankBrain does is offline… It’s given batches of historical searches and learns to make predictions from these. Those predictions are tested, and if proven good, then the latest version of RankBrain goes live. Then the learn-offline-and-test cycle is repeated.”
Given that manner of working, the three updates (12th January, 2nd March and 17th April) could be something we will soon come to see as a “normal” Machine Learning update: Google pushing a “chunk” of Machine Learning into the core algorithm, creating an initial major shock, immediately followed by a period of significant instability whilst the new learning “beds itself in” on live data.
Who agrees with me on that educated guess?
To Boldly Go… Answer Engines
“The destiny of [Google’s search engine] is to become that Star Trek computer, and that’s what we are building.” Amit Singhal
What makes the Star Trek computer such an interesting aspiration for Google? It provides answers, either after a conversational exchange with the user, or (even more exciting for Google) anticipating the user’s need and providing the solution without being prompted.
Google is on a mission to develop a Virtual Assistant that dialogues with users, observes their behaviour, autonomously learns and improves over time and provides single (“objectively correct”) answers… driven by Machine Learning.

Google is destined to become a Star-Trek-like answer engine.
Machine Learning – the two sides of the AEO equation
Note: Obviously the delimitation is not as clear as suggested below, there is crossover between the two side of the equation. This distinction helps keep things relatively simple and is a great way to approach this challenge short term, without losing sight of the longer term.
- Front end: Understanding user intent
Implementation of Machine Learning in already heavily here – query patterns, word vectors, universal sentence encoding… RankBrain is the catch-all official name for this aspect of Machine Learning in Google’s core search algorithm. It is the part of the algorithm that aims to better understand the user’s need, and thus enable the ranking engine to better prioritise the results according to intent.
For any query, RankBrain takes the query, then factors in information it has on the user (including such aspects as search history, attributes of the person, purchase history etc), the specific context (time, place, device etc), and its understanding of the world to identify the need as accurately and specifically as possible.
Aim: Understand the question so it can pass a very specific and explicit request to the back end.
- Back end: Understanding available options
Google is gathering information about available options through many channels: The Knowledge Graph, MyBusiness, Local Guides, AdWords, etc. with the aim of providing the front end with the most pertinent and credible solution / answer.
There are an enormous number of potential applications for Machine Learning here. But if Google is uncommunicative about RankBrain, it is even less communicative about this aspect of its engine, so this side of the equation often passes very much under the radar.
As far as I know, there is no specific name attributed to this part of the algorithm, but the aim is to reliably collect and understand the available options, then assess their relative suitability and credibility.
This is a vast area where Machine Learning will thrive. Although very coy with their announcements, Google’s patents indicate that Machine Learning is already being applied in this sphere, and is destined to be the dominant force. Bill Slawski’s articles are a great source of information and inspiration on those patents. Start reading here.

Aim: Provide the answer (and not just a set of results to choose from).
Changing our approach
Machine Learning is a revolution in SEO. So much so that, rather than think “how can I be one of the possibilities offered by Google to its user”, we must now think “how can I be the single answer Google provides to its user”. And that shift in perspective is necessary today. New opportunities for being the answer are coming at us hard and fast – AnswerBoxes, Knowledge Panels, People Also Ask, MyBusiness etc. And voice search is truly a game changer where being the answer is the only viable option for marketers. Keeping up with implementing effective tactics for such a multitude of Position0 is already a tough task, and that task that will become much more difficult as machine learning increasingly makes those opportunities case-specific.
Implementing the relevant tactics is, of course, necessary. But within the context of a “Machine Learning revolution”, having any chance of being offered up as the answer by Google, Microsoft, Amazon et al requires a holistic, brand-centric approach.
Machine Learning is the driving force that heralds the new era of Answer Engines, and the winning strategy in AEO is one centered on Understanding and Credibility.
More on AEO from Jason BARNARD
The Key to the Future of SEO / AEO – Understanding and Credibility
BrightonSEO A Universal Strategy for Answer Engine Optimisation – Beyond Position0 (link to be announced)
Hummingbird and the Knowledge Graph – what are they, and what is their impact on SEO? (webinar)
