
Crawling is one of the essential tools in the SEO toolbox. Because sites must be crawled (by Google) to be indexed, ranked, clicked, crawling your site (with an SEO crawler) and making sure you like the results is a natural first step in a solid SEO strategy. It’s also the best way to sweep all of your site for monitoring and tracking purposes, to benchmark its current state, or to measure improvements.
What is a crawl (and how does it work)?
A crawl is the analysis by a bot of a set of web pages. This can be a finite list of pages, but more frequently, a crawl starts on a specific page or pages, and uses the bot to read the page and discover all of the links on those pages. The bot then visits all of the linked pages that it hasn’t already visited, and discovers links on those pages. This process repeats until the bot can no longer find links to pages it doesn’t already know.
During this voyage, bots record and report on information they encounter, such as page status reported by the server when they request a page, the time it takes to pass all of a page’s information to the bot, and so on.
Bots might also draw information from the pages themselves: page titles, meta information, number of words, structured data…
This means that bots need to be able to access and read a page and identify links in it. Most limitations on crawls come from elements or conditions that prevent one of these steps from occurring.
What are the limitations of a crawl?
Rules you set for SEO crawlers
Unlike for googlebot, you can set many of the parameters of an SEO bot’s behavior. This will determine how the crawl is carried out, and what pages the bot can discover.
A very obvious example is a crawl limit in the form of a maximum number of URLs. If this parameter is set and the number is too low for your site, the bot won’t be able to crawl all of your pages–but not for a technical reason!
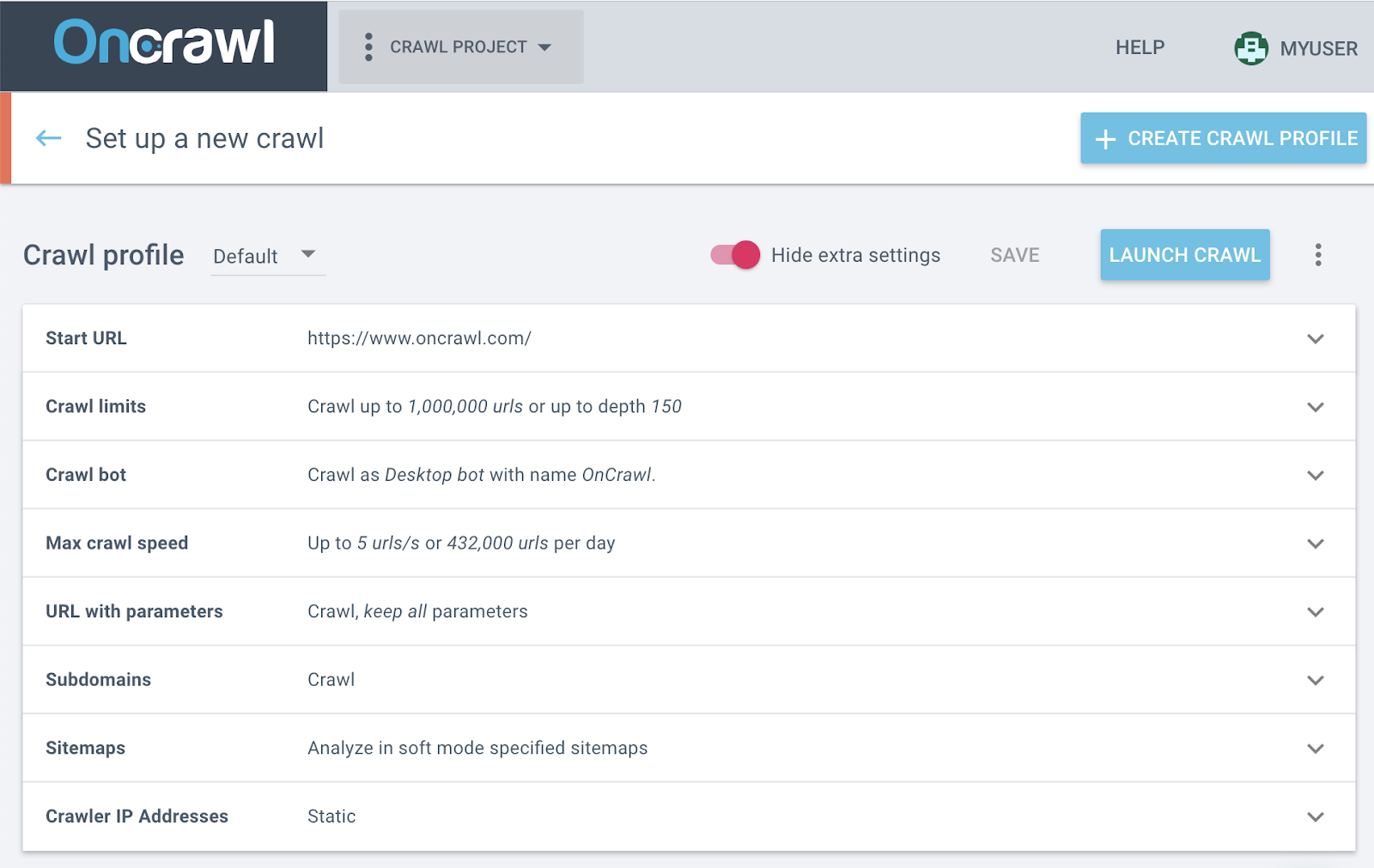
How to fix it: Modify your crawl settings!
Anti-bot prejudice
Sites that don’t play well with bots often create problems with crawls.
This includes sites that refuse access to bots. Sites like this might have legitimate reasons for excluding bots:
- The site owner does not want the site indexed.
- The site requires a login, a cookie, or another verification method that standard bots can’t provide.
- The site has restrictive authorizations after a bad bot experience, such as scraping, monitoring by competitors, or an attack meant to bring down a server.
- The site uses a third-party protection service that blocks all unknown bots or that blocks bots on the service’s blacklist, whether or not the site itself has had a bad experience.
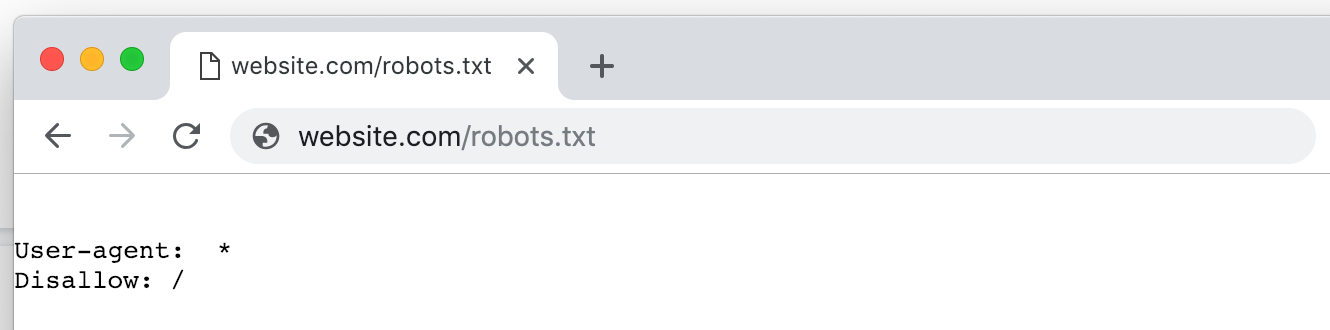 But the problem with general bot exclusions is that crawling a site to understand and improve it is not (and generally cannot) be done by hand. The nature of audits requires that the site be accessible to bots.
But the problem with general bot exclusions is that crawling a site to understand and improve it is not (and generally cannot) be done by hand. The nature of audits requires that the site be accessible to bots.
Even when the site to be crawled hasn’t decided that all bots are bad bots, it can still throw a wrench in the works by treating different bots differently from other bots or from human visitors. This might include the following behavior:
- Hiding content from bots or from users (cloaking)
- Providing different restrictions to certain bots using the htaccess file, a robots.txt file or meta robots instructions
When the crawl bot is treated differently than googlebot, the crawl results show the analysis for a site that isn’t the one Google sees, and real issues for googlebots may go undetected. Likewise, when bots are not treated the same as users, the site that is analyzed is not the one users see and cannot be used to reveal user problems.
How to fix it: Make sure you can articulate why you’re crawling the site. Do you want to understand how users see the site? How Google sees it? To get a list of pages and their characteristics, regardless of visitors? This will determine the type of authorizations the crawl bot will need.
Then, talk with the web development team or your web service provider to establish the right compromise between available bot settings in your crawler, and permissible authorizations on your website and its pages.
When using Oncrawl to crawl your site, you can take measures including–but not limited to–the following:
- Request static IP addresses for Oncrawl’s bot and whitelist them.
- Use a virtual robots.txt file to override the website’s instructions to bots (…but only for Oncrawl’s bot).
- Modify the bot name to make Oncrawl’s bot follow instructions aimed at other bots.
- Provide login, cookie, or HTTP header information required to render the site properly..
Bot-JavaScript relations
The history of bot-JS relations is fraught with issues related to the process of producing the content of a page for the visitor that requested it, aka rendering. Until recently, few bots were able to render pages that use JavaScript. While this is no longer the case, not all crawlers can render all JavaScript, and JavaScript crawls continue to be more “expensive” (read: require more complex technologies and run more slowly) than standard crawls.
As JavaScript is used to insert and expand all sorts of content, including header information (like canonicals and hreflang), links, and textual content, bots need to have access to the final version of pages. When this is not the case, the information for each page in a crawl will be incomplete–or the entire crawl may be incomplete, if JavaScript is used to insert links.
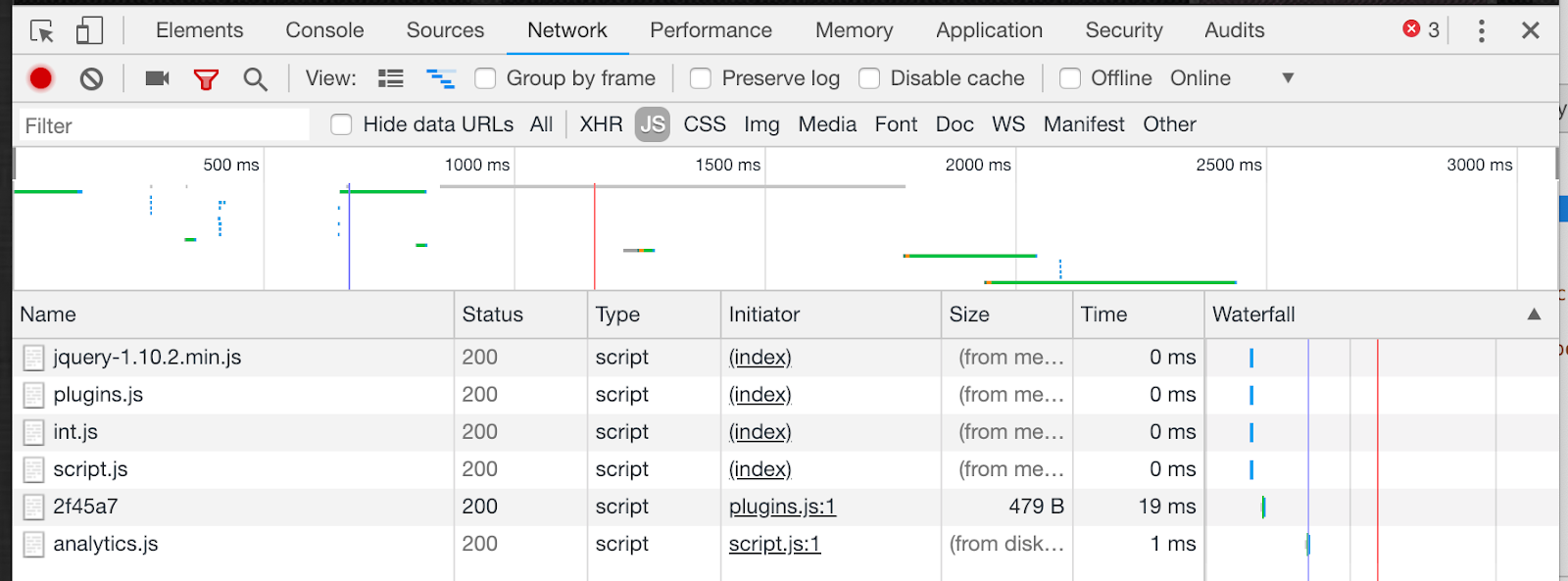
How to fix it: Understand how JavaScript is used on your website, and determine whether or not it is required for bot to get an understanding of the site. If you need to crawl with JavaScript, determine whether your site can be pre-rendered, or whether the crawler’s bot needs to do all of the rendering itself. (Oncrawl’s bot can! Don’t forget to enable the option in the crawl settings.) If you’re looking for the right crawler to use, make sure to choose a crawler with a bot that supports crawls on sites with technical specs like yours.
The Great Unknown beyond your crawl frontiers
A crawl only provides information about the pages it crawls. It has no knowledge of pages that fall outside of the scope of the crawl. This may seem obvious, but it has reaching implications that are easy to forget about:
- A crawl has no knowledge whatsoever of any pages outside of its limits if you’ve restricted the number of pages, the depth of exploration, the subdomains to be crawled…
- A crawl has no idea what may or may not exist beyond the borders of your site. This includes industry standards, competitor sites, other ranking sites, translations of your site on different ccTLDs, the influence of PBNs…
- A crawl is subject to backlink-blindness: it can’t take into account the influence of backlinks because it can’t see the pages that link to your site.
- A crawl can’t see pages that aren’t linked to in the structure of your site (orphan pages).
- A crawl can only report on site-internal measures, without taking into off-site factors, from linking, to paid search, to promotion on social networks…
This can skew results when key elements for your analysis or in your SEO strategy fall outside of the crawl frontier, whether this takes the form of high-performing orphan pages, backlinks, hreflang or canonicals pointing to other (sub)domains, paid or off-site campaigns, or the relative quality of your site in comparison with other sites like it.
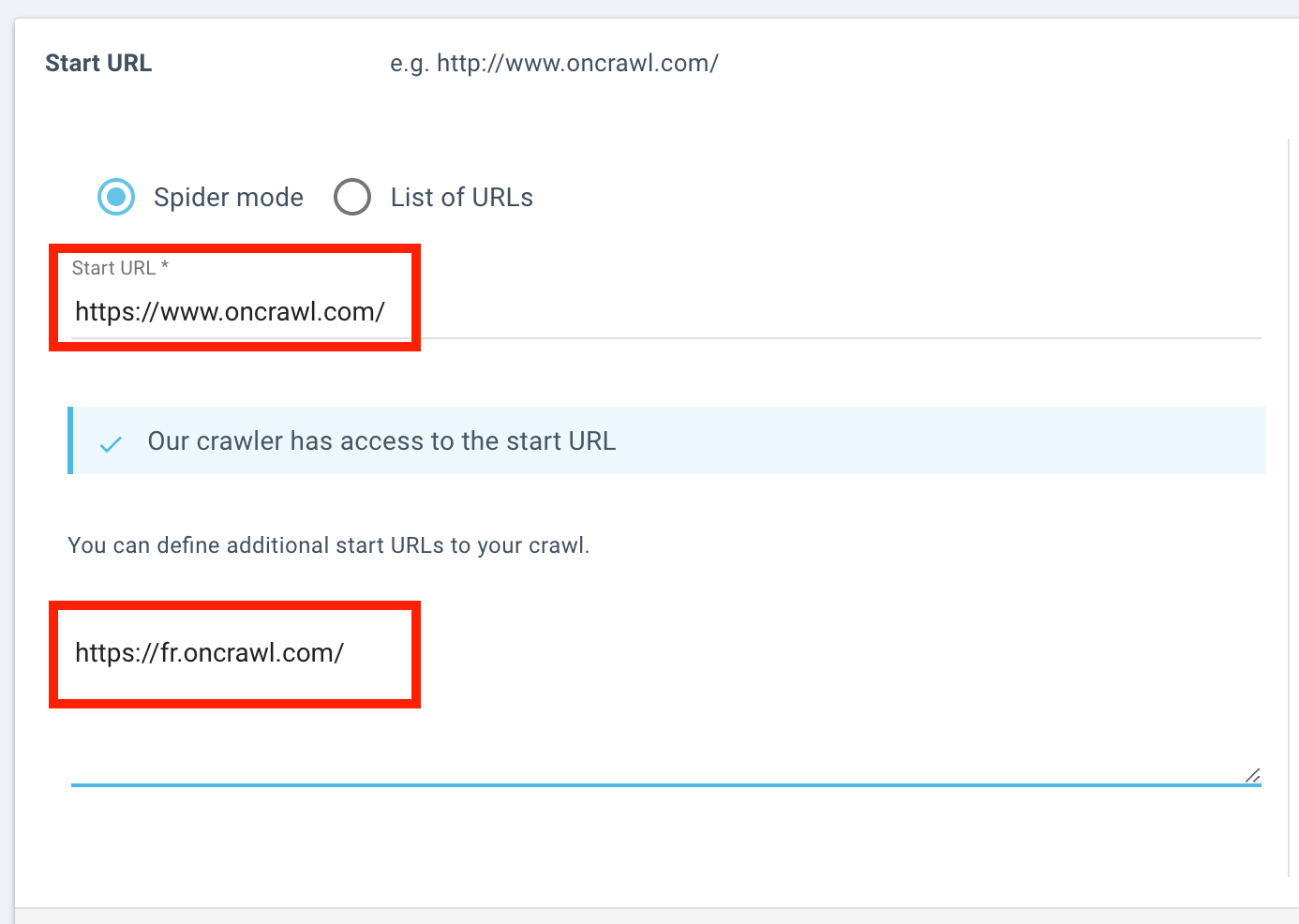
Expanding crawl frontiers to include a subdomain.
How to fix it: Many of the problems associated with the unknown territory beyond your crawl frontiers can be solved by remembering, when analyzing crawl results, that just because you didn’t crawl it doesn’t mean it doesn’t exist. When you are aware of what type of pages you might have excluded from your crawl, you are better able to judge whether or not this might have an influence on your results.
More concretely, though, Oncrawl provides options to help expand the crawl frontier to meet your needs. For example, you can crawl across subdomains, or use multiple start URLs on different domains. You can also use third-party data to include information about pages beyond the crawl frontier. To cite a few:
- You can include to data from Majestic to gain insights on backlinks and their influence on your website’s pages.
- You can use data from different sources (Google Analytics and similar analytics tools, Google Search Console, server log data…) to find orphan pages.
- The crawl and subsequent analysis are built to take on sites of any size, so you can set crawl limits on depth and number of pages based on your site itself, instead of arbitrary maximums.
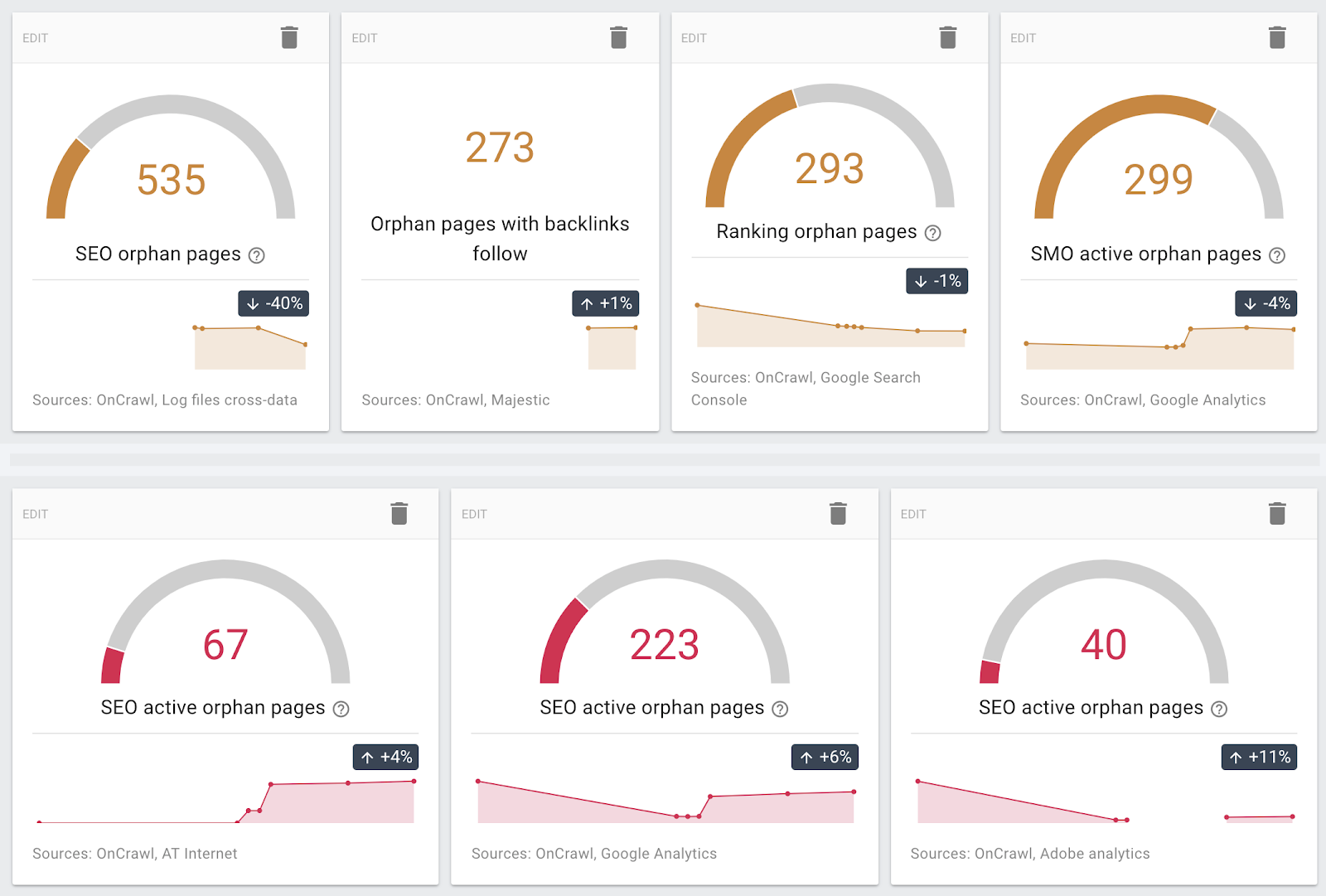
Orphan pages from discovered using different sources
Crawl expectations vs. reality
A crawl describes your site and how a bot or a user will see its pages, starting from the entry point you defined as your start URL. However, an SEO crawl bot does not have the search intent, search results, or decision-making facilities that a human visitor does; nor does it have the crawl scheduler, the ranking factors, machine learning, and knowledge of much of the rest of the internet that search engine bots have.
A crawl cannot provide information on how and when search engine bots or users consume your site. This sort of information, which is key to how a site performs, includes:
- How measured elements affect or are affected by user or bot behavior
- When, how, or in what order your pages will be crawled by Google
- Which pages get the most visits
- How pages rank
- Where to concentrate SEO efforts for the best ROI
The result is often an analysis in a vacuum. A crawl provides extensive information about your site, but no way to relate that information to how your site lives and breathes with relation to your customers, the SERPs, and the rest of the internet.
How to fix it: Use more data!
The crawl’s basic data for each known URL on a website can be paired with any or all of the following types of data to turn a crawl into an extremely powerful tool for understanding and managing web performance:
- Analytics data on how users behave
- Ranking data drawn from Google Search Console
- Bot and user hit counts and frequency from server logs
- Business indicators from a CRM
- Custom datasets from other sources
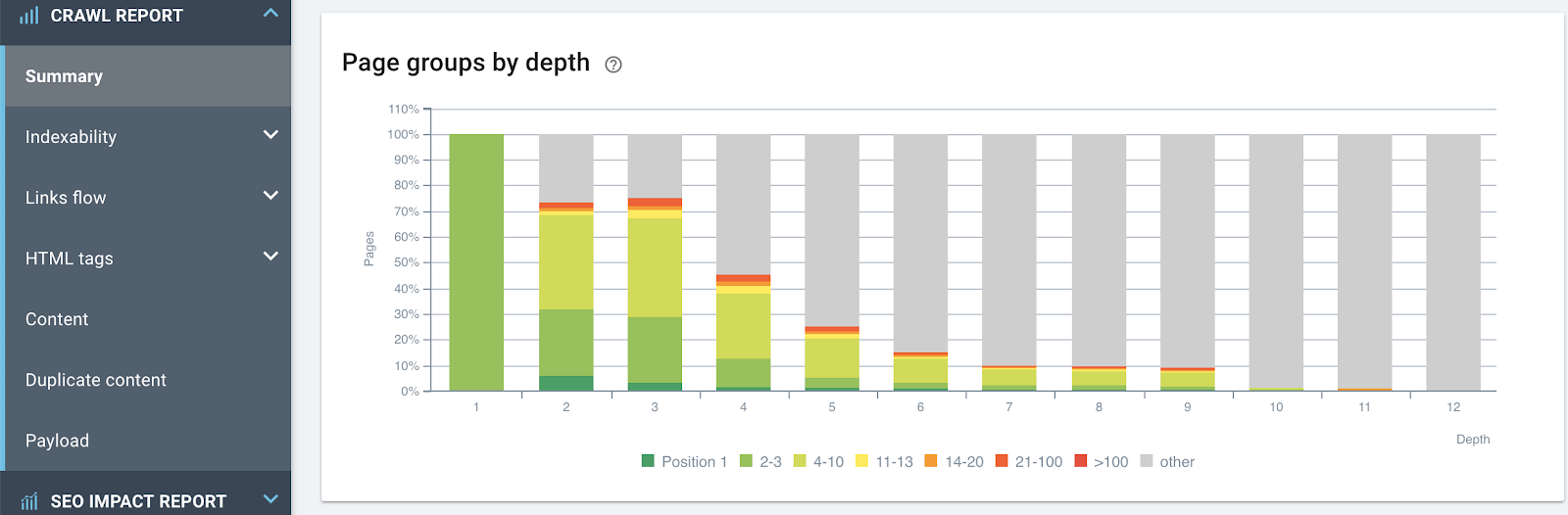
Effect of depth (distance from the home page in number of clicks) on ranking: the closer to the home page it is, the better a page can rank.
TL;DR How to overcome problems with crawls
Crawling may be an essential tool in the SEO toolbox, but when taken alone it is not an SEO panacea. As we have seen above, many of the shortcomings of a crawl can be mitigated or eliminated by two major strategies:
1. Addressing bot limitations. Limitations imposed on bots can be linked to the technology behind the crawler, rules set by the website, or options chosen by person setting up the crawl. Working with the website’s development team, using the right crawler with appropriate crawl settings can remove many of the obstacles to crawling your pages and obtaining useful analyses.
2. Providing access to additional data. By nature, a crawl’s view of the website cannot include business or website performance data–key indicators for the marketing decision-making process–since these are not contained on the web page itself. Cross-analysis between crawl data and behavioral, ranking, or even business data can turn a crawl analysis into a fine-tuned decision-making tool.
Once you’ve overcome the limitations that made your crawl results less than reliable, you’ll find a wealth of insights to drive your SEO strategy.
