
I would like to get this article started with a very simple sort of equation: if your pages are not crawled, they will never be indexed and therefore, your SEO performance will always suffer (and stink).
As a consequence of that, SEOs need to endeavour to find the best way to make their websites crawlable and provide Google with their most important pages to get them indexed and start acquiring traffic through them.
Thankfully, we have many resources that can help us to improve our website crawlability such as Screaming Frog, Oncrawl or Python. I will show you how Python can help you out to analyze and improve your crawling friendliness and indexing indicators. Most of the time, these sorts of improvements also drive to better rankings, higher visibility in the SERPs and eventually, more users landing onto your website.
1. Requesting indexing with Python
1.1. For Google
Requesting indexing for Google can be done in several ways, although sadly I am not very convinced by any of them. I will walk you through three different options with their pros and cons:
- Selenium and Google Search Console: from my point of view and after testing it and the rest of the options, this is the most effective solution. However, after a number of attempts it is possible that there will be a captcha pop-up that will break it.
- Pinging a sitemap: it definitely helps to make the sitemaps crawled as requested, but not specific URLs, for instance in the case that new pages have been added to the website.
- Google Indexing API: it is not very reliable except for broadcasters and job platform websites. It helps to increase crawling rates but not to index specific URLs.
After this quick overview about each method, let’s dive into them one by one.
1.1.1. Selenium and Google Search Console
Essentially, what we will do in this first solution is to access Google Search Console from a browser with Selenium and replicate the same process that we would follow manually to submit many URLs for indexing with Google Search Console, but in an automated way.
Note: Don’t overuse this method and only submit a page for indexing if its content has been updated or if the page is completely new.
The trick to be able to log into Google Search Console with Selenium is by accessing the OUATH Playground first as I explained in this article about how to automate the GSC crawl stats report downloading.
#We import these modules
import time
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.keys import Keys
#We install our Selenium Driver
driver = webdriver.Chrome(ChromeDriverManager().install())
#We access the OUATH playground account to log into Google Services
driver.get('https://accounts.google.com/o/oauth2/v2/auth/oauthchooseaccount?redirect_uri=https%3A%2F%2Fdevelopers.google.com%2Foauthplayground&prompt=consent&response_type=code&client_id=407408718192.apps.googleusercontent.com&scope=email&access_type=offline&flowName=GeneralOAuthFlow')
#We wait a bit to make sure rendering is complete before selecting elements with Xpath and introducing our email address.
time.sleep(10)
form1=driver.find_element_by_xpath('//*[@id="identifierId"]')
form1.send_keys("<your email address>")
form1.send_keys(Keys.ENTER)
#Same here, we wait a bit and then we introduce our password.
time.sleep(10)
form2=driver.find_element_by_xpath('//*[@id="password"]/div[1]/div/div[1]/input')
form2.send_keys("<your password>")
form2.send_keys(Keys.ENTER)
After that, we can access our Google Search Console URL:
driver.get('https://search.google.com/search-console?resource_id=your_domain”')
time.sleep(5)
box=driver.find_element_by_xpath('/html/body/div[7]/div[2]/header/div[2]/div[2]/div[2]/form/div/div/div/div/div/div[1]/input[2]')
box.send_keys("your_URL")
box.send_keys(Keys.ENTER)
time.sleep(5)
indexation = driver.find_element_by_xpath("/html/body/div[7]/c-wiz[2]/div/div[3]/span/div/div[2]/span/div[2]/div/div/div[1]/span/div[2]/div/c-wiz[2]/div[3]/span/div/span/span/div/span/span[1]")
indexation.click()
time.sleep(120)
Unfortunately, as explained in the introduction, it seems that after a number of requests it starts requiring a puzzle captcha to proceed with the indexing request. Since automated method can’t solve the captcha, this is something that handicaps this solution.
1.1.2. Pinging a sitemap
Sitemap URLs can be submitted to Google with the ping method. Basically, you would only need to make a request to the following endpoint introducing your sitemap URL as a parameter:
http://www.google.com/ping?sitemap=URL/of/file
This can be automated very easily with Python and requests as I explained in this article.
import urllib.request url = "http://www.google.com/ping?sitemap=https://www.example.com/sitemap.xml" response = urllib.request.urlopen(url)
1.1.3. Google Indexing API
The Google Indexing API can be a good solution to improve your crawling rates but usually it is not a very effective method to get your content indexed as it is only supposed to be used if your website has either JobPosting or BroadcastEvent embedded in a VideoObject. However, if you would like to give it a try and test it yourself, you can follow the next steps.
First of all, to get started with this API you need to go to Google Cloud Console, create a project and a service account credential. After that, you will need to enable the Indexing API from the Library and add the email account that is given with the service account credentials as a property owner on Google Search Console. You might need to use the old version of Google Search Console to be able to add this email address as a property owner.
Once you follow the previous steps, you will be able to start asking indexing and deindexing with this API by using the next piece of code:
from oauth2client.service_account import ServiceAccountCredentials
import httplib2
SCOPES = [ "https://www.googleapis.com/auth/indexing" ]
ENDPOINT = "https://indexing.googleapis.com/v3/urlNotifications:publish"
client_secrets = "path_to_your_credentials.json"
credentials = ServiceAccountCredentials.from_json_keyfile_name(client_secrets, scopes=SCOPES)
if credentials is None or credentials.invalid:
credentials = tools.run_flow(flow, storage)
http = credentials.authorize(httplib2.Http())
list_urls = ["https://www.example.com", "https://www.example.com/test2/"]
for iteration in range (len(list_urls)):
content = '''{
'url': "'''+str(list_urls[iteration])+'''",
'type': "URL_UPDATED"
}'''
response, content = http.request(ENDPOINT, method="POST", body=content)
print(response)
print(content)
If you would like to ask for deindexing, you would need to change the request type from “URL_UPDATED” to “URL_DELETED”. The previous piece of code will print the responses from the API with the notification times and their statuses. If the status is 200, then the request will have been made successfully.
1.2. For Bing
Very often when we speak about SEO we only think of Google, but we cannot forget that in some markets there are other predominant search engines and/or other search engines that have a respectable market share like Bing.
It is important to mention from the beginning that Bing already has a very convenient feature on Bing Webmaster Tools that enables you to request the submission of up to 10,000 URLs per day in most of the cases. Sometimes, your daily quota might be lower than 10,000 URLs but you have the option of requesting a quota increment if you think that you would need a larger quota to meet your needs. You can read more about this on this page.
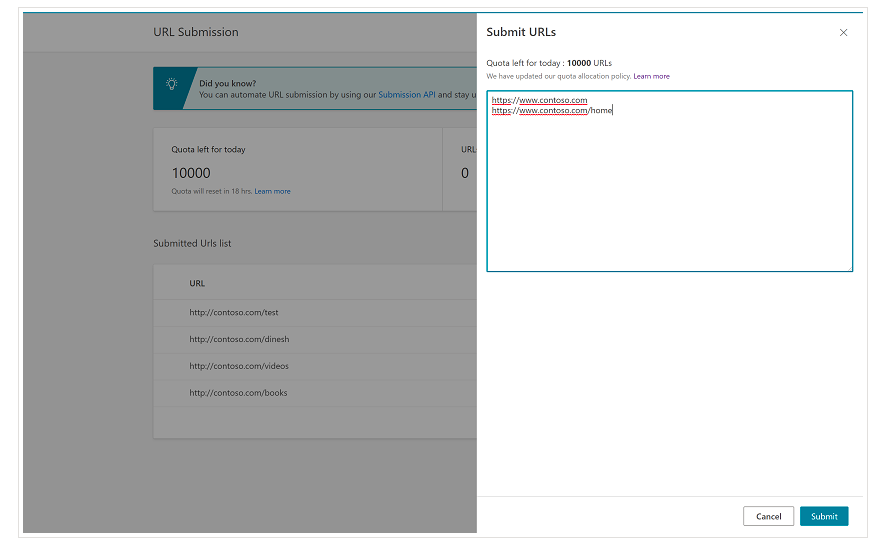
This feature is indeed very convenient for bulk URLs submissions as you will only need to introduce your URLs in different lines in the URL submission tool from the normal interface of Bing Webmaster Tools.
1.2.1. Bing Indexing API
Bing Indexing API can be used with an API key that needs to be introduced as a parameter. This API key can be obtained on Bing Webmaster Tools, going to the API access section and after that, generating the API key.
Once the API key has been gotten, we can play around with the API with the following piece of code (you would only need to add your API key and your site URL):
import requests
list_urls = ["https://www.example.com", "https://www.example/test2/"]
for y in list_urls:
url = 'https://ssl.bing.com/webmaster/api.svc/json/SubmitUrlbatch?apikey=yourapikey'
myobj = '{"siteUrl":"https://www.example.com", "urlList":["'+ str(y) +'"]}'
headers = {'Content-type': 'application/json; charset=utf-8'}
x = requests.post(url, data=myobj, headers=headers)
print(str(y) + ": " + str(x))
This will print the URL and its response code on each iteration. In contrast to Google Indexing API, this API can be used for any sort of website.
[Case Study] Increase visibility by improving website crawlability for Googlebot

2. Sitemaps analysis, creation and upload
As we all know, sitemaps are very useful elements to provide search engine bots with the URLs that we would like them to crawl. In order to let search engine bots know where our sitemaps are, they are meant to be uploaded to Google Search Console and Bing Webmaster Tools and included onto the robots.txt file for the rest of the bots.
With Python we can work on mainly three different aspects related to the sitemaps: their analysis, creation and uploading and deletion from Google Search Console.
2.1. Sitemap importation and analysis with Python
Advertools is a great library created by Elias Dabbas that can be used for sitemap importation as well as many other SEO tasks. You will be able to import sitemaps into Dataframes just by using:
sitemap_to_df('https://example.com/robots.txt', recursive=False)
This library supports regular XML sitemaps, news sitemaps and video sitemaps.
On the other hand, if you are only interested in importing the URLs from the sitemap, you can also use the library requests and BeautifulSoup.
import requests
from bs4 import BeautifulSoup
r = requests.get("https://www.example.com/your_sitemap.xml")
xml = r.text
soup = BeautifulSoup(xml)
urls = soup.find_all("loc")
urls = [[x.text] for x in urls]
Once the sitemap has been imported, you can play around with the extracted URLs and perform a content analysis as explained by Koray Tuğberk in this article.
2.2. Sitemaps creation with Python
You can also utilize Python to create sitemaps.xml from a list of URLs as JC Chouinard explained in this article. This can be especially useful for very dynamic websites whose URLs are rapidly changing and together with the ping method that was explained above, it can be a great solution to provide Google with the new URLs and get them crawled and indexed fast.
Recently, Greg Bernhardt also created an APP with Streamlit and Python to generate sitemaps.
2.3. Uploading and deleting sitemaps from Google Search Console
Google Search Console has an API that can be used mainly in two different ways: to extract data about the web performance and handle sitemaps. In this post, we will focus on the option of uploading and deleting sitemaps.
First, it is important to create or use an existing project from Google Cloud Console to obtain an OUATH credential and enable the Google Search Console service. JC Chouinard explains very well the steps that you need to follow to access Google Search Console API with Python and how to make your first request in this article. Basically, we can completely make use of his code but only by introducing a change, in the scopes we will add “https://www.googleapis.com/auth/webmasters” instead of “https://www.googleapis.com/auth/webmasters.readonly” as we will use the API not only to read but to upload and delete sitemaps.
Once, we connect with the API, we can start playing with it and list all the sitemaps from our Google Search Console properties with the next piece of code:
for site_url in verified_sites_urls:
print (site_url)
# Retrieve list of sitemaps submitted
sitemaps = webmasters_service.sitemaps().list(siteUrl=site_url).execute()
if 'sitemap' in sitemaps:
sitemap_urls = [s['path'] for s in sitemaps['sitemap']]
print (" " + "\n ".join(sitemap_urls))
When it comes to specific sitemaps, we can do three tasks that we will elaborate in the next sections: uploading, deleting and requesting information.
2.3.1. Uploading a sitemap
To upload a sitemap with Python we only need to specify the site URL and the sitemap path and run this piece of code:
WEBSITE = 'yourGSCproperty’ SITEMAP_PATH = 'https://www.example.com/page-sitemap.xml' webmasters_service.sitemaps().submit(siteUrl=WEBSITE, feedpath=SITEMAP_PATH).execute()
2.3.2. Deleting a sitemap
The other side of the coin is when we would like to delete a sitemap. We can also delete sitemaps from Google Search Console with Python using the “delete” method instead of “submit”.
WEBSITE = 'yourGSCproperty’ SITEMAP_PATH = 'https://www.example.com/page-sitemap.xml' webmasters_service.sitemaps().delete(siteUrl=WEBSITE, feedpath=SITEMAP_PATH).execute()
2.3.3. Requesting information from the sitemaps
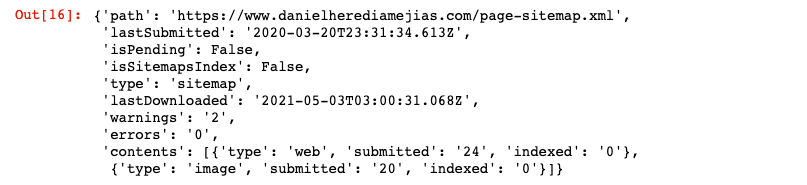
Finally, we can also request information from the sitemap by using the method “get”.
WEBSITE = 'yourGSCproperty’ SITEMAP_PATH = 'https://www.example.com/page-sitemap.xml' webmasters_service.sitemaps().get(siteUrl=WEBSITE, feedpath=SITEMAP_PATH).execute()
This will return a response in JSON format like:
3. Internal linking analysis and opportunities
Having a proper internal linking structure is very helpful to facilitate search engine bots the crawling of your website. Some of the main issues that I have come across by auditing a number of websites with very sophisticated technical setups are:
- Links introduced with on-click events: in short, Googlebot does not click on buttons, so if your links are inserted with an on-click event, Googlebot will not be able to follow them.
- Client-side rendered links: despite that Googlebot and other search engines are becoming much better at executing JavaScript, it is still something quite challenging for them, so it is much better to server-side render these links and serve them into the raw HTML to search engine bots than expecting them to execute JavaScript scripts.
- Login and/or age gate pop-ups: login pop-ups and age gates can prevent search engine bots from crawling the content that is behind these “obstacles”.
- Nofollow attribute overuse: using many nofollow attributes pointing to valuable internal pages will prevent search engine bots from crawling them.
- Noindex and follow: technically the combination of noindex and follow directives should let search engine bots crawl the links that are on that page. However, it seems that Googlebot stops crawling those pages with noindex directives after a while.
With Python we can analyse our internal linking structure and find new internal linking opportunities in bulk mode.
3.1. Internal Linking Analysis with Python
Some months ago I wrote an article about how to use Python and the library Networkx to create graphs to display the internal linking structure in a very visual way:
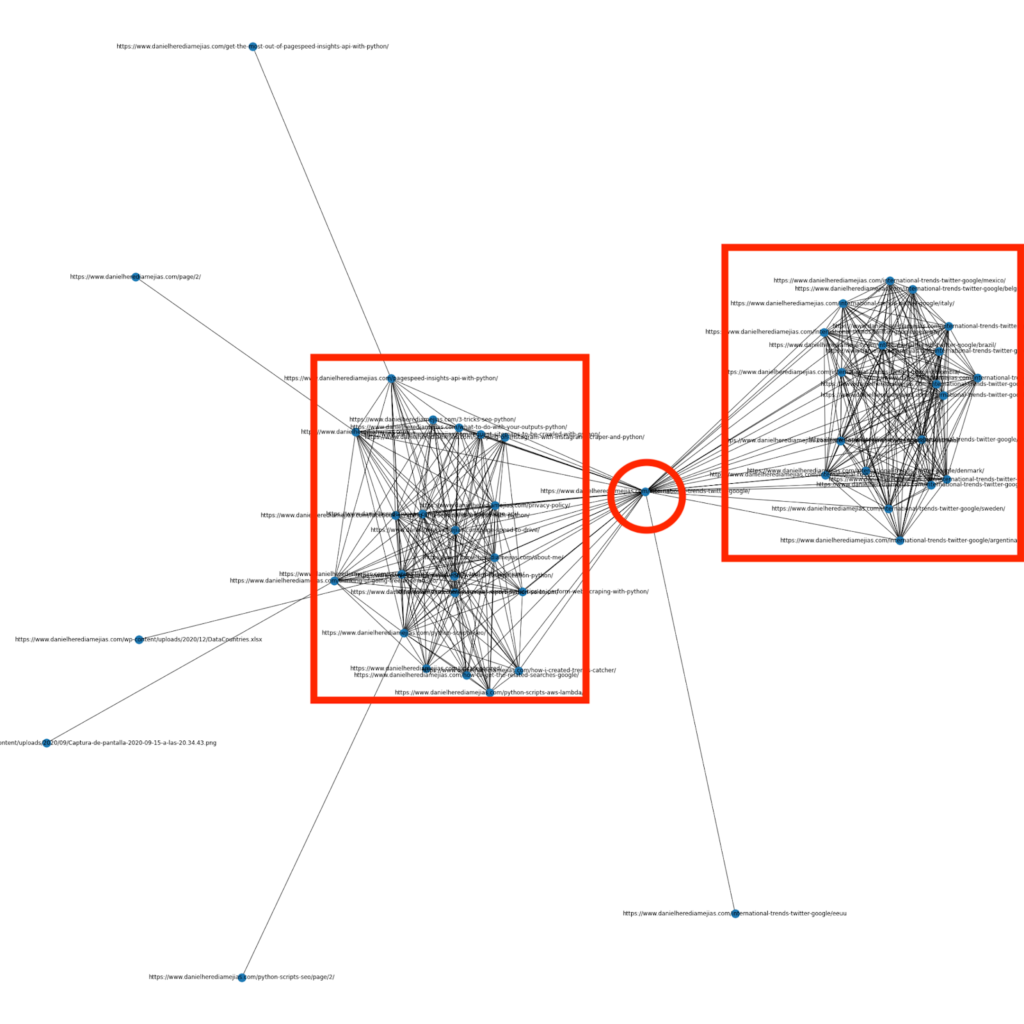
This is something very similar to what you can obtain from Screaming Frog, but the advantage of using Python for this sort of analyses is that basically you can choose the data that you would like to include in these graphs and control most of the graph elements such as colors, node sizes or even the pages that you would like to add.
3.2. Finding new internal linking opportunities with Python
Apart from analyzing site structures, you can also make use of Python to find new internal linking opportunities by providing a number of keywords and URLs and iterating over those URLs searching for the provided terms in their pieces of content.
This is something that can work very well with Semrush or Ahrefs exports in order to find powerful contextual internal links from some pages that are already ranking for keywords and hence, that already have some type of authority.
You can read more about this method over here.
4. Website Speed, 5xx and soft error pages
As stated by Google on this page about what crawl budget means for Google, making your site faster improves the user experience and increases the crawl rate. On the other hand, there are also other factors that might affect crawl budget such as soft error pages, low quality content and on-site duplicate content.
4.1. Page speed and Python
4.2.1 Analyzing your website speed with Python
Page Speed Insights API is super useful to analyze how your website is performing in terms of page speed and to get lots of data about many different page speed metrics (almost 50) plus Core Web Vitals.
Working with Page Speed Insights with Python is very straightforward, only an API key and requests are needed to make use of it. For example:
import urllib.request, json url = "https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url=your_URL&strategy=mobile&locale=en&key=yourAPIKey" #Note that you can insert your URL with the parameter URL and you can also modify the device parameter if you would like to get the data for desktop. response = urllib.request.urlopen(url) data = json.loads(response.read())
In addition, you can also forecast with Python and Lighthouse Scoring calculator how much your overall performance score would improve in case of making the requested changes to enhance your page speed as explained in this article.
4.2.2 Image Optimization and Resizing with Python
Related to the website speed, Python can also be used to optimize, compress and resize images as explained in these articles written by Koray Tuğberk and Greg Bernhardt:
- Automate Image Compression with Python over FTP.
- Resize Images with Python in Bulk.
- Optimize images via Python for SEO and UX.
4.2. 5xx and other response code errors extraction with Python
5xx response code errors might be indicative that your server is not fast enough to cope with all the requests that it is receiving. This can have a very negative impact on your crawl rate and it can also damage the user experience.
In order to make sure that your website is performing as expected, you can automate the crawl stats report downloading with Python and Selenium and you can keep a close eye on your log files.
4.3. Soft error pages extraction with Python
Recently, Jose Luis Hernando published an article in honour of Hamlet Batista about how you can automate the coverage report extraction with Node.js. This can be an amazing solution to extract the soft error pages and even the 5xx response errors that might negatively impact your crawl rate.
We can also replicate this same process with Python in order to compile in only one Excel tab all the URLs that are provided by Google Search Console as erroneous, valid with warnings, valid and excluded.
First, we need to log into Google Search Console as explained previously in this article with Python with Selenium. After that, we will select all the URL status boxes, we will add up to 100 rows per page and we will start iterating over all the types of URLs reported by GSC and download every single Excel file.
import time
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get('https://accounts.google.com/o/oauth2/v2/auth/oauthchooseaccount?redirect_uri=https%3A%2F%2Fdevelopers.google.com%2Foauthplayground&prompt=consent&response_type=code&client_id=407408718192.apps.googleusercontent.com&scope=email&access_type=offline&flowName=GeneralOAuthFlow')
time.sleep(5)
searchBox=driver.find_element_by_xpath('//*[@id="identifierId"]')
searchBox.send_keys("<youremailaddress>")
searchBox.send_keys(Keys.ENTER)
time.sleep(5)
searchBox=driver.find_element_by_xpath('//*[@id="password"]/div[1]/div/div[1]/input')
searchBox.send_keys("<yourpassword>")
searchBox.send_keys(Keys.ENTER)
time.sleep(5)
yourdomain = str(input("Insert here your http property or domain. If it is a domain include: 'sc-domain':"))
driver.get('https://search.google.com/search-console/index?resource_id=' + yourdomain)
elem3 = driver.find_element_by_xpath("/html/body/div[*]/c-wiz/span/c-wiz/c-wiz/div/div[3]/div[2]/div/div/div/span/c-wiz/div/div[1]/div/div[4]/div[1]/span/span/div/div[1]/span[2]")
elem3.click()
elem6 = driver.find_element_by_xpath("/html/body/div[*]/c-wiz/span/c-wiz/c-wiz/div/div[3]/div[2]/div/div/div/span/c-wiz/div/div[1]/div/div[3]/div[1]/span/span/div/div[1]/span[2]")
elem6.click()
elem7 = driver.find_element_by_xpath("/html/body/div[*]/c-wiz/span/c-wiz/c-wiz/div/div[3]/div[2]/div/div/div/span/c-wiz/div/div[1]/div/div[2]/div[1]/span/span/div/div[1]/span[2]")
elem7.click()
elem4 = driver.find_element_by_xpath("/html/body/div[*]/c-wiz/span/c-wiz/c-wiz/div/div[3]/div[2]/div/div/c-wiz/div/span/div/div[2]/div/div/span[1]/span/div[2]/div[1]/div[1]/div[2]/span")
elem4.click()
time.sleep(2)
elem5 = driver.find_element_by_xpath("/html/body/div[*]/c-wiz/span/c-wiz/c-wiz/div/div[3]/div[2]/div/div/c-wiz/div/span/div/div[2]/div/div/span[1]/span/div[2]/div[2]/div[5]/span")
elem5.click()
time.sleep(5)
problems = driver.find_elements_by_xpath("/html/body/div[*]/c-wiz/span/c-wiz/c-wiz/div/div[3]/div[2]/div/div/c-wiz/div/span/div/div[1]/div[2]/table/tbody/*/td[2]/span/span")
list_problems = []
for x in problems:
list_problems.append(x.text)
counter = 1
for x in list_problems:
print("Extracting the report for " + x)
elem2 = driver.find_element_by_xpath("/html/body/div[*]/c-wiz/span/c-wiz/c-wiz/div/div[3]/div[2]/div/div/c-wiz/div/span/div/div[1]/div[2]/table/tbody/tr[" + str(counter) + "]/td[2]/span/span")
elem2.click()
time.sleep(5)
downloading1 = driver.find_element_by_xpath("/html/body/div[*]/c-wiz[2]/c-wiz/div/div[1]/div[1]/div[2]/div")
downloading1.click()
time.sleep(2)
downloading2 = driver.find_element_by_xpath("/html/body/div[*]/c-wiz[2]/div/div/div/span[2]")
downloading2.click()
time.sleep(5)
if counter != len(list_problems):
driver.get('https://search.google.com/search-console/index?resource_id=' + yourdomain)
time.sleep(3)
elem3 = driver.find_element_by_xpath("/html/body/div[*]/c-wiz/span/c-wiz/c-wiz/div/div[3]/div[2]/div/div/div/span/c-wiz/div/div[1]/div/div[4]/div[1]/span/span/div/div[1]/span[2]")
elem3.click()
elem6 = driver.find_element_by_xpath("/html/body/div[*]/c-wiz/span/c-wiz/c-wiz/div/div[3]/div[2]/div/div/div/span/c-wiz/div/div[1]/div/div[3]/div[1]/span/span/div/div[1]/span[2]")
elem6.click()
elem7 = driver.find_element_by_xpath("/html/body/div[*]/c-wiz/span/c-wiz/c-wiz/div/div[3]/div[2]/div/div/div/span/c-wiz/div/div[1]/div/div[2]/div[1]/span/span/div/div[1]/span[2]")
elem7.click()
elem4 = driver.find_element_by_xpath("/html/body/div[*]/c-wiz/span/c-wiz/c-wiz/div/div[3]/div[2]/div/div/c-wiz/div/span/div/div[2]/div/div/span[1]/span/div[2]/div[1]/div[1]/div[2]/span")
elem4.click()
time.sleep(2)
elem5 = driver.find_element_by_xpath("/html/body/div[*]/c-wiz/span/c-wiz/c-wiz/div/div[3]/div[2]/div/div/c-wiz/div/span/div/div[2]/div/div/span[1]/span/div[2]/div[2]/div[5]/span")
elem5.click()
time.sleep(2)
counter = counter + 1
else:
driver.close()
You can watch this explanatory video:
Once we have downloaded all the Excel files, we can put all of them together with Pandas:
import pandas as pd
from datetime import datetime
today = str(datetime.date(datetime.now()))
for x in range(len(list_problems)):
print(x)
if x == 0:
df1 = pd.read_excel(yourdomain.replace("sc-domain:","").replace("/","_").replace(":","_") + "-Coverage-Drilldown-" + today + ".xlsx", 'Tabla')
listvalues = [list_problems[x] for i in range(len(df1["URL"]))]
df1['Type'] = listvalues
list_results = df1.values.tolist()
else:
df2 = pd.read_excel(yourdomain.replace("sc-domain:","").replace("/","_").replace(":","_") + "-Coverage-Drilldown-" + today + " (" + str(x) + ").xlsx", 'Tabla')
listvalues = [list_problems[x] for i in range(len(df2["URL"]))]
df2['Type'] = listvalues
list_results = list_results + df2.values.tolist()
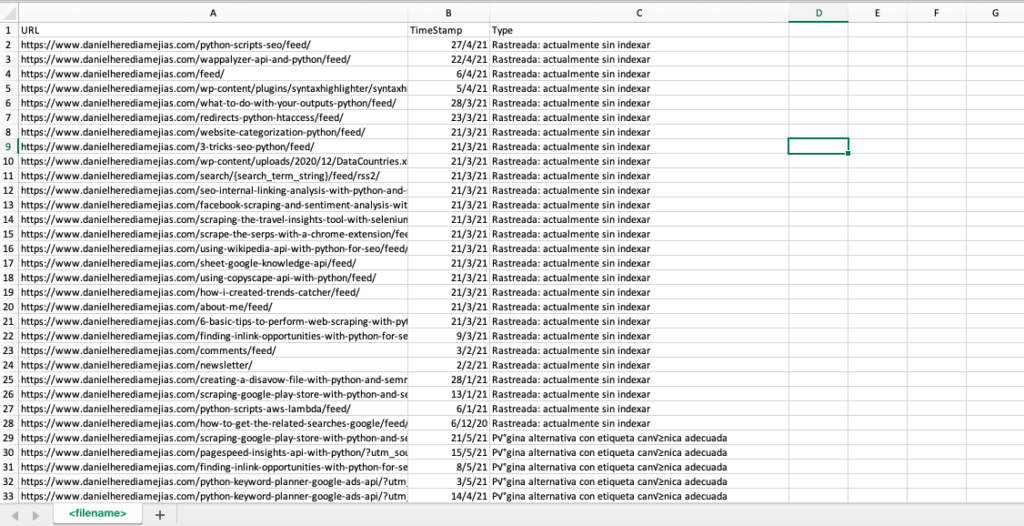
df = pd.DataFrame(list_results, columns= ["URL","TimeStamp", "Type"])
df.to_csv('<filename>.csv', header=True, index=False, encoding = "utf-8")
The final output looks like:
4.4. Log file analysis with Python
As well as the data which is available on the crawl stats report from Google Search Console, you can also analyze your own files by using Python to get much more information about how the search engine bots are crawling your website. If you aren’t already using a log analyzer for SEO, you can have a read at this article from SEO Garden where log analysis with Python is explained.
[Ebook] Four Use Cases to Leverage SEO Log Analysis
5. Final conclusions
We have seen that Python can be a great asset to analyze and improve the crawling and indexing of our websites in many different ways. We’ve also seen how to make life much easier by automating most of the tedious and manual tasks that would require thousands of hours of your time.
I must say that unfortunately I am not fully convinced by the solutions that are offered at the moment by Google to request indexing for a large number of URLs, although I can understand to some extent its fear of offering a better solution: many SEOs might tend to overuse it.
In contrast to that, there is Bing, which offers exceptional and convenient solutions to request URL indexing via API and even through the normal interface on Bing Webmaster Tools.
Due to the fact that Google indexing API has room for improvement, other elements like having an accessible and updated sitemap in place, your internal linking, your page speed, your soft error pages and your duplicate and low quality content become even more important to ensure that your website is properly crawled and your most important pages are indexed.
